We are living through what has frequently been called the era of Big Data. Big Data usually refers to the three characteristics of data (called 3 V’s): Volume, Velocity and Variety. Volume refers to the amount of data that is generated by systems. Velocity refers to the speed at which data are being generated. Variety refers to the form of data (structured, unstructured, semi-structured) and types of data (text, image, video, audio).

These three characteristics influence other aspects visible in IT systems: data forms change quickly, structures evolve rapidly, many types of events are processed, data flows through many systems, and data is stored in various databases. In general, changes around data are happening faster than before.
IT departments try to keep up with these changes by constantly evolving data schemas, changing architectures and reorganising their systems. At the same time, business teams need to analyse the data, but they also want to manage processes, such as marketing campaigns, fraud detection, risk scoring and many others. These processes require operational data to run on them.
For analytics purposes, the industry has invented many suitable approaches to make data more accessible to the business. We have data warehouses, the data lake approach and data federation connected with data mesh architecture, but we won’t be exploring them in this article. What we will be looking at are operational data and processes based on them.
Acting on operational data is a more complex task than analytics. You have to react with low latency and because of many trade-offs, data is stored in various places, in different formats. As a result, we still don’t have an industry standard that makes this part of the job more accessible to the business and it’s still almost entirely implemented by the IT team.
Unfortunately, this approach – leaving everything to the IT team – has several drawbacks.
Firstly, organisations make inefficient use of their people's skills. IT people are good at delivering services, designing the most appropriate solution architecture and creating a model of the domain, while the business team is good at analysing data, extracting insights and thinking about processes. Why waste the IT team’s time translating business requirements into the code and the business team’s time shaping those requirements?
Secondly, the business is not fully aware of all the possibilities offered by the data and services available. As a result, it’s very likely that they’ll miss out on some opportunities around data. And nobody likes missing out, do they?
The last thing is the length of the OODA loop. What happens currently is the business team analyses the data, proposes the process design, and then asks IT to implement it. They then have to twiddle their thumbs and wait for implementation and deployment before they can validate the design. You see the problem? The process is much longer than it needs to be. If there was a way to eliminate some or all of these steps, we could streamline the process and save time and money.
Happily, it turns out there is a way to resolve these issues and make the implementation of operational processes more accessible to the business. We’re calling this idea a bridge application, and it’s what I’m going to talk about in this article.

But first, to better understand what a bridge application is, we need to take a closer look at the aspects of operational data that are changing quickly.
Aspect one: Data sources
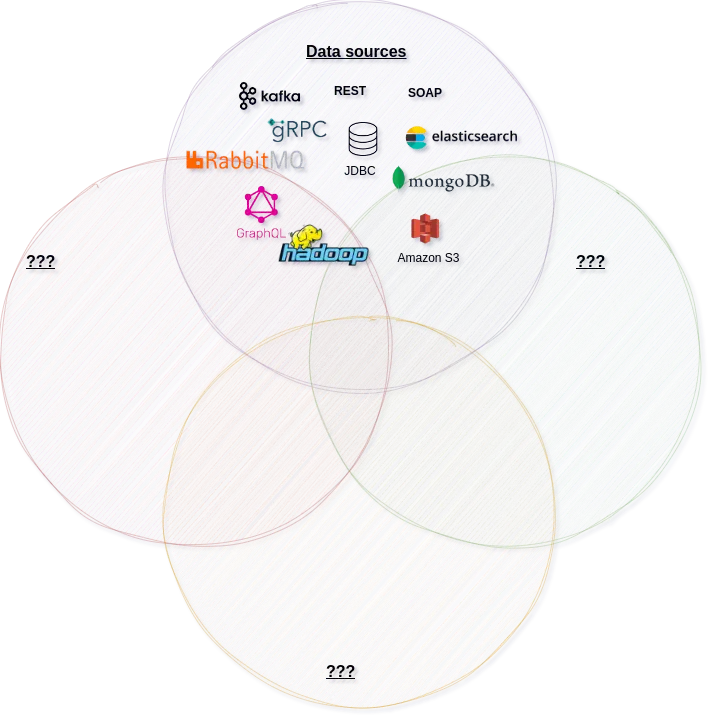
The last decades have changed the way IT stores data and communicates between systems. After the hegemony of RDBMS, there was a boom in the NoSQL databases. Each solution showed its own concept of how to handle the CAP (Consistency, Availability, Partition Tolerance) triangle and dedicated approaches for various forms of data (structured, unstructured, semi-structured). Data is exposed directly through protocols such as JDBC, custom DB protocols or hidden behind service layers: REST services, using gRPC or GraphQL. More often, data flows in streaming solutions such as Apache Kafka or RabbitMQ.
Aspect two: Data formats
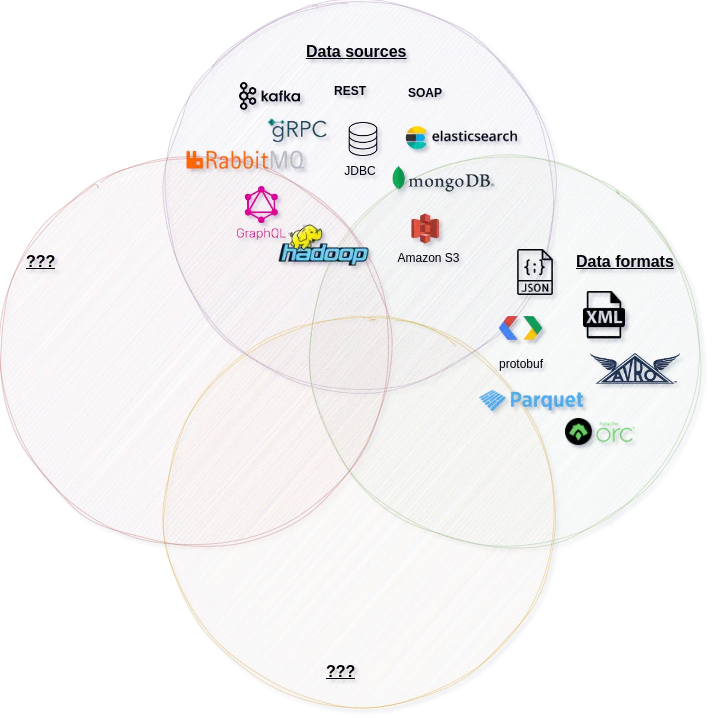
Many of the described solutions don’t specify the format of the data. This allows them to handle both structured and unstructured data such as audio or images. And even for structured data, users can choose the format that best suits their needs. This makes data formats the second area where innovation leads to diversity. Each of them comes with their own trade-offs. Let’s discuss some of them:
- JSON is a reasonably concise and human-readable format, so it’s easy to debug issues during communication. It does, however, transfer a lot of unnecessary data (field names), which adds a cost and reduces throughput.
- While CSV is human-readable and doesn’t transfer field names, it isn’t really suitable for complex data structures and schema evolution.
- Binary formats such as Avro and Protobuf are very concise, they can be processed at high throughput and they are schema evolution-ready. However, reading or writing records is more difficult because you need a schema to do so.
Formats such as ORC or Parquet are designed for the optimal processing of large files distributed across many computing nodes.
Aspect three: Schemas
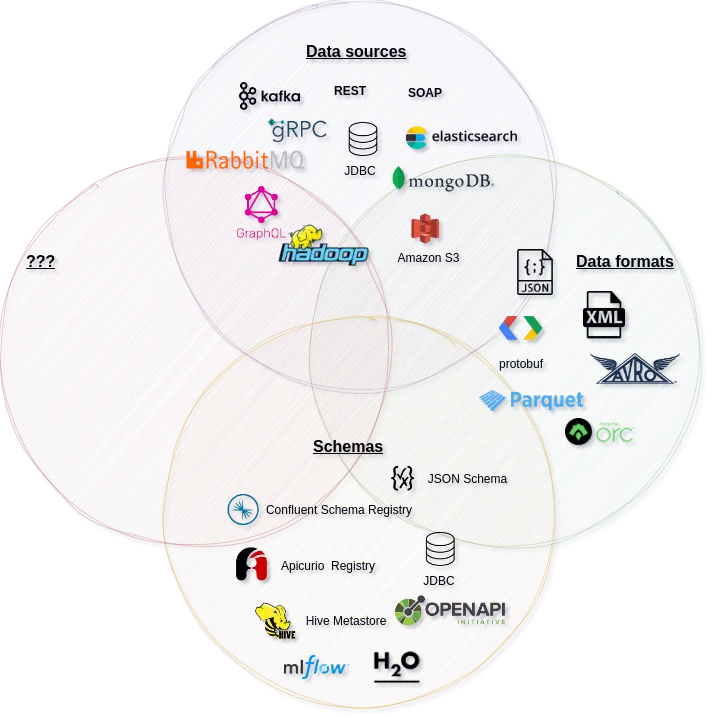
The data format is a set of basic rules for expressing data. It doesn’t specify the exact structure of the data. To specify the exact structure, you need to define a schema. There are two things about schemas: the format of the schema and the way data is associated with the schema.
Most data formats have idiomatic schema definition types: e.g., JSON messages have JSON Schema, XML has XML Schema, REST services are specified using OpenAPI. The way in which data is associated with a schema is more flexible. For example, with Avro you have multiple implementations of schema registries and options for how to identify the schema associated with each message.
In the database world, you have specific interfaces for reading schemas. For example, the metadata part of JDBC interfaces for most of RDBMS. In Machine Learning Word, model definitions are stored in registries such as MLflow Model Registry or H2O Model Registry.
Some organisations have their own concepts of schema organisation, for example, they store schemas exposed by services in a shared Service catalogue.
Aspect four: Processing models
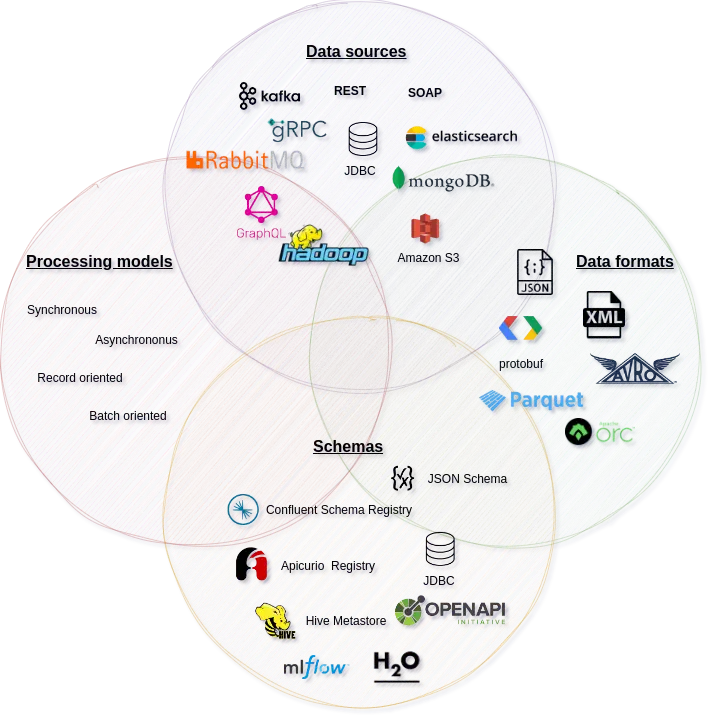
The final aspect, but perhaps the most significant one, is processing models. We can think of processing models in two dimensions:
- Synchronous vs. asynchronous processing
- Batch-oriented vs. record-oriented processing
Let’s start with the first dimension. The synchronous approach is very natural for people because we communicate with each other synchronously. You ask a question and after a moment you get an answer. This allows you to make some inferences and move on to the next step. For some tasks, however, it can be harmful. You have to deal with timeouts and repeated calls. Therefore, in many situations, you should consider an asynchronous approach. In the asynchronous approach, data passes through several stages of processing. Each stage doesn't know the result of the next stage – it only knows the input from the previous stage.
Another dimension is the dimension of batch-oriented versus record-oriented processing. Sometimes you are interested in some scope of data. For example, you need to produce a report for last month. In order to do this, you need to look at your data as a set of records, sort it, calculate averages, and do some other aggregations. In the end, you want to have a result associated with this set of records. In this case, batch processing is the natural choice. In all other cases, it is easier to think in terms of records rather than batches. Even if your data is split into multiple batches for technical reasons (e.g. performance).
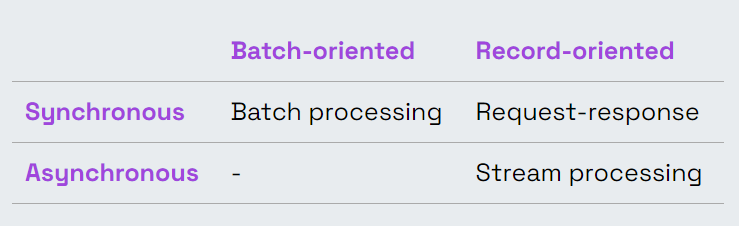
The special case of synchronous, record-oriented processing is the request-response processing paradigm, well-known from Web services. It is synchronous – you wait for a response from a service – but it is also record-oriented – your service sees each request separately, without knowledge of the broader context of the requests.
A bridge application
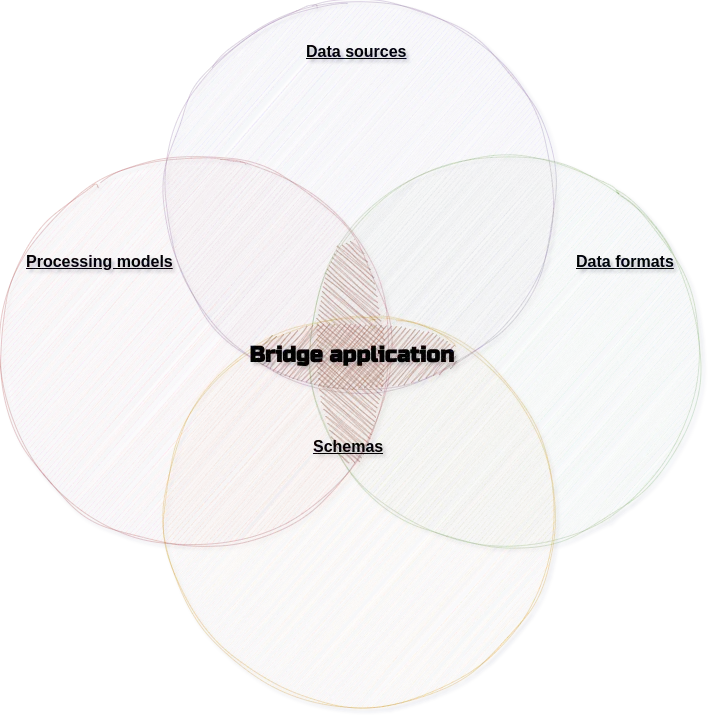
And here we come to the bridge application mentioned above. The perfect bridge application should handle all of these cases. You might say “OK, that’s easy, we should just find one application that integrates everything with everything!” But that is not exactly the answer. Let’s say it again: We want to build a bridge for the business to allow them to act on operational data. If integration were the only important feature, we would create a tool that only IT could use.
To enable the business team to use this application, we have to hide all the technical details that are not important to them. The bridge application can achieve this through a number of techniques. One is to move information such as URLs, credentials and other configuration parameters to a place in the application where the business team’s user doesn't have access. Another technique is the unification of concepts. From a technical perspective, the synchronous approach, which is the request-response model with web services under the hood, is completely different from the asynchronous approach with a message broker in the middle. Also, Avro messages look different from JSON messages, and communicating with a database is different from communicating with a web service. And yet, to the average business user, all this stuff is mostly meaningless; it’s just data and services (operations).
The next thing to consider is how quickly and seamlessly the bridge application will react to changes in the described areas. Let's consider the most common case: we add a new event type or service operation or change the existing one. A good bridge application should expose these changes immediately so that users can deliver their solutions on time and teams can collaborate smoothly.
A good bridge application should also enable the discovery of available data types and services. Well-organised IT departments already use techniques such as service catalogues or data governance solutions (e.g. Apache Atlas or OpenMetadata). Users should be able to relate this information to the data types and services available in the application. This will give them a better understanding of how things are organised, how exactly they work and who is responsible for a particular area.
Now this sounds great, you're probably thinking, but what about the integration aspect? Should we also be concerned about that? Yes, we should. First of all, a good bridge application should be extensible. It should allow IT to add all the things we have mentioned, such as data sources, data formats, schema types or schema registries. Thanks to this, if there is a change in the architecture, it will be possible to add an extension to deal with it.
Adding new extensions may be expensive for some organisations, and sometimes it will be cheaper to add an adaptation layer that translates one format into another. To do this, the bridge application should support at least some of the popular protocols for each processing paradigm. Then we can use tools such as Apache NiFi or Kafka Connect to translate a given format into the existing one.
Finally, let’s go back to the word “bridge”. The bridge should connect both teams. They will see different perspectives but they should work closely together. Using different words for the same things is unacceptable. They should be able to talk about specific event types and identify certain services without hassle or possible misunderstandings.
Let's summarise the features of a good bridge application:
- Hidden technical details
- Unification of concepts
- Fast and seamless response to IT changes
- Discoverability of data types and services
- Extensibility
- Support for various: data sources, data formats, schemas, schema registries and processing paradigms
- IT terms shared with the business
How does it help?
At this point, it might be worth reminding ourselves of why we're talking about a bridge application and why, we believe, there's such a pressing need for one.
First issue: efficient use of people's skills in organisations. Thanks to the bridge application, the business team will be able to design processes and implement them on their own. Meanwhile, the IT team is free to focus on delivering services and data. Both teams will discuss capabilities that are available in data and services instead of requirements of the process that will be implemented. In this way, everybody's work becomes more efficient.
The second issue was awareness of data and services. The business team will discover the capabilities of operational data and services in their daily work. Thanks to that, they will be more aware of possibilities and they will not miss opportunities around data.
The last issue was the length of the OODA loop. With a bridge application, the business team won’t need to spend so much time thinking about optimal process design before they pass their requirements to the IT team. They can carry out experiments on live data, quickly verify assumptions and introduce adjustments that will improve prepared indicators. They can repeat this cycle more often and deliver more sophisticated solutions to their customers.
Recap
Today, organisations need to keep up with the rapid pace of change around data. Operational data requires complex IT solutions to handle these changes. This makes the implementation of business processes inaccessible to the business team. You can change this by using a bridge application. This bridge application should have features that make it suitable for business use. This approach will bring you many benefits: you will make better use of your organisation's resources and you will be ready for new opportunities around your data.
Stay tuned for my next blog post where I'll go backstage of our product development process – I'll describe what we've already done and what our plans ahead are to be a full-featured bridge application.