How to act on data when the data structure is flexible
In this blog post, I’ll show how to integrate Nussknacker with data stored in Elasticsearch. One of the most important features of Nussknacker is autocompletion and validation mechanisms. To make it work, it is necessary to deliver schema for data that are processed by Nussknacker. Elasticsearch and other document-oriented databases have a “flexible” approach to handling the structure of data. I’ll check if it is easy to write decision rules on data structures that evolve quickly.

What are document-oriented databases
The last couple of years is a high growth in the popularity of document databases. What does it mean exactly, that a database is a “document database”? It means that data are stored in the database in a form of a document. The “document” can be understood as a data structure with various properties (fields), potentially nested, with leaf values represented as simple types (string/number/boolean) or lists. It can be represented as
a JSON:
{ “name”: “John”,
“surname”: “Smith”,
“roles”: [
“reader”,
“writer”
],
“nested”: {
“field1”: 123
}
}
an XML:
<userDetails> <name>John</name>
<surname>Smith</surname>
<roles>
<role>reader</role>
<role>writer</role>
</roles>
<nested>
<field1>1234</field1>
</nested>
</userDetails>
or any other format suitable for transferring objects (sometimes called structures or records) well known in almost every programming language.
Contrary to relational databases, it is very easy to save a document. In relational databases, you need to define table schema, translate your internal representation to relational representation and execute matching insert/update queries. In document databases, you don’t need to do the translation. Objects can be serialized to JSON automatically.
The difference between static and dynamic schemas
What about the schema definition step? Firstly why schema is important at all? Schema is useful in two situations: during insertion - for validation of data and during read queries - to let the database engine know how to read data and how to do it fast (the engine can prepare optimized structures to make queries faster).
There are three options, how to define schema:
- Static Schema on Write: Schema should be specified by the user ahead of time before the first insert - to make sure that all that will follow rules specified in the definition
- Dynamic Schema on Write: Schema will be added by the engine based on the structure of an inserted record
- Schema on Read: Schema will be specified by the user just before reading the record - it can be done explicitly in a database or implicitly in the application using concrete values from data
RDBMSs use the first approach. Schema on Read approach is used by Document-oriented databases like MongoDB (implicit schema) and Data Lake solutions like Hive (explicit schema). Elasticsearch allows users to decide if the Static Schema on Write or Dynamic Schema on Write approach should be used.
Dynamic Schema on Write and Schema on Read approaches are geared towards elastic schema changes. It is easy to add a document in the new format. It has some drawbacks like the quality of your data can become worse over time but on the other hand, you can very quickly experiment with your data.
Elasticsearch - a brief introduction
In this paragraph I’ll go through a quick introduction to the concepts behind Elasticsearch. To make it easier to understand I recommend downloading the repository with example and invoking:
After a while, you’ll have Kibana available at http://localhost:5601/ . This example has other tools included like Nussknacker and Kafka, but I’ll elaborate on that later.
In Elasticearch you have the concept of indices (don’t confuse it with RDBMS indices). An index is something very similar to a table - you should keep the same type of documents in the same index. Thanks to that it will be easy to query across them.
It is a good thing to distribute timestamp-based data into indices associated with some period of time that can be retained after some time. For example, you can organize events into indices: events-2023.01, events-2023.02, etc. In the RDBMS world, those indices will be called “partitions”.
You can see all indices by clicking Stack Management → Index Management at the left menu. Some indices are hidden, you can show it by switching the “Include hidden indices” toggle on.
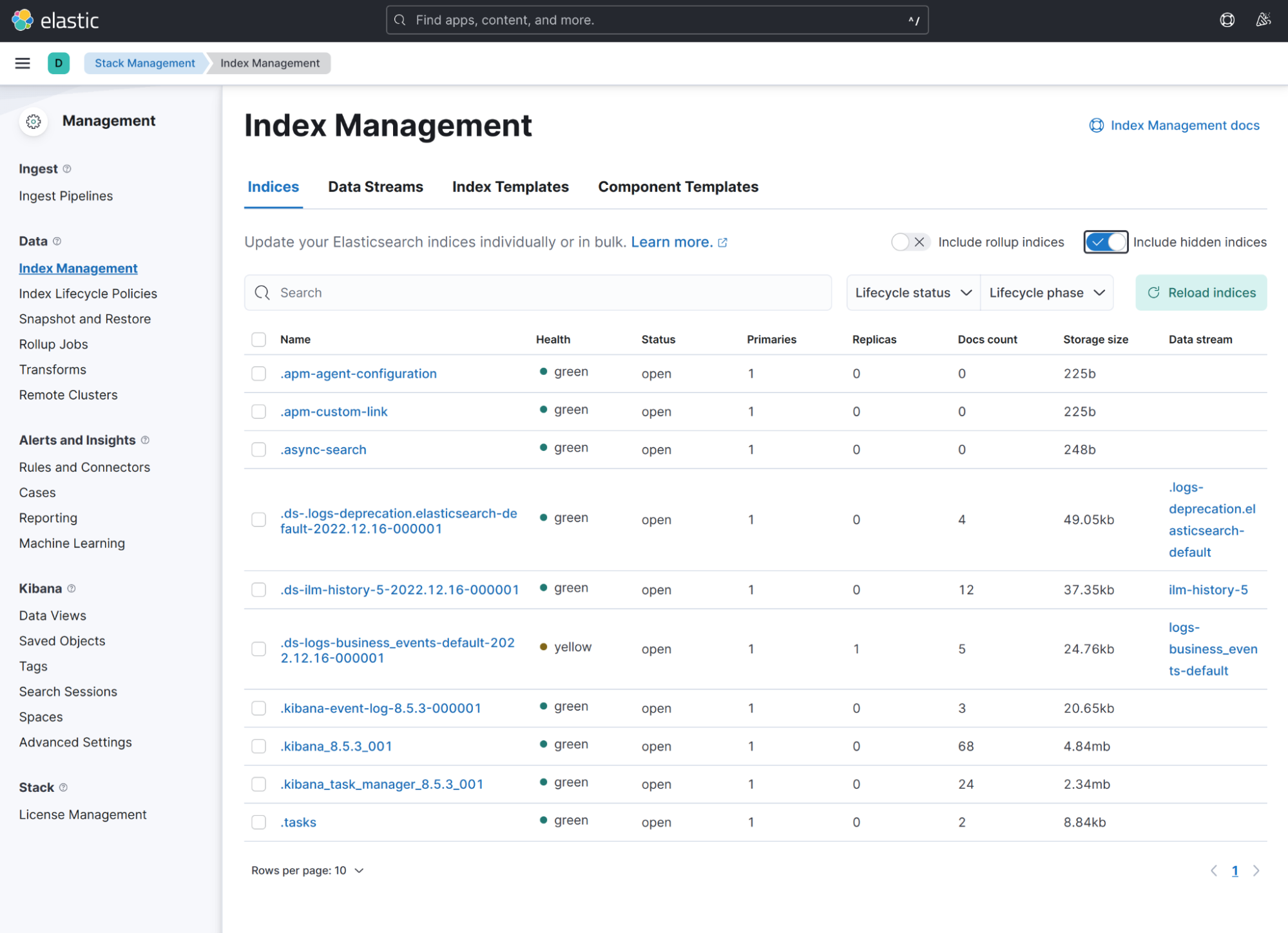
Elasticsearch has also a concept of Index templates. Those templates group all similar indices (probably partitioned by time). You can see some predefined templates on the “Index Templates” tab.
Index templates can have associated Mappings. Let’s see some existing mapping by clicking e.g. “ilm-history” index template and switching to “Mappings” tab: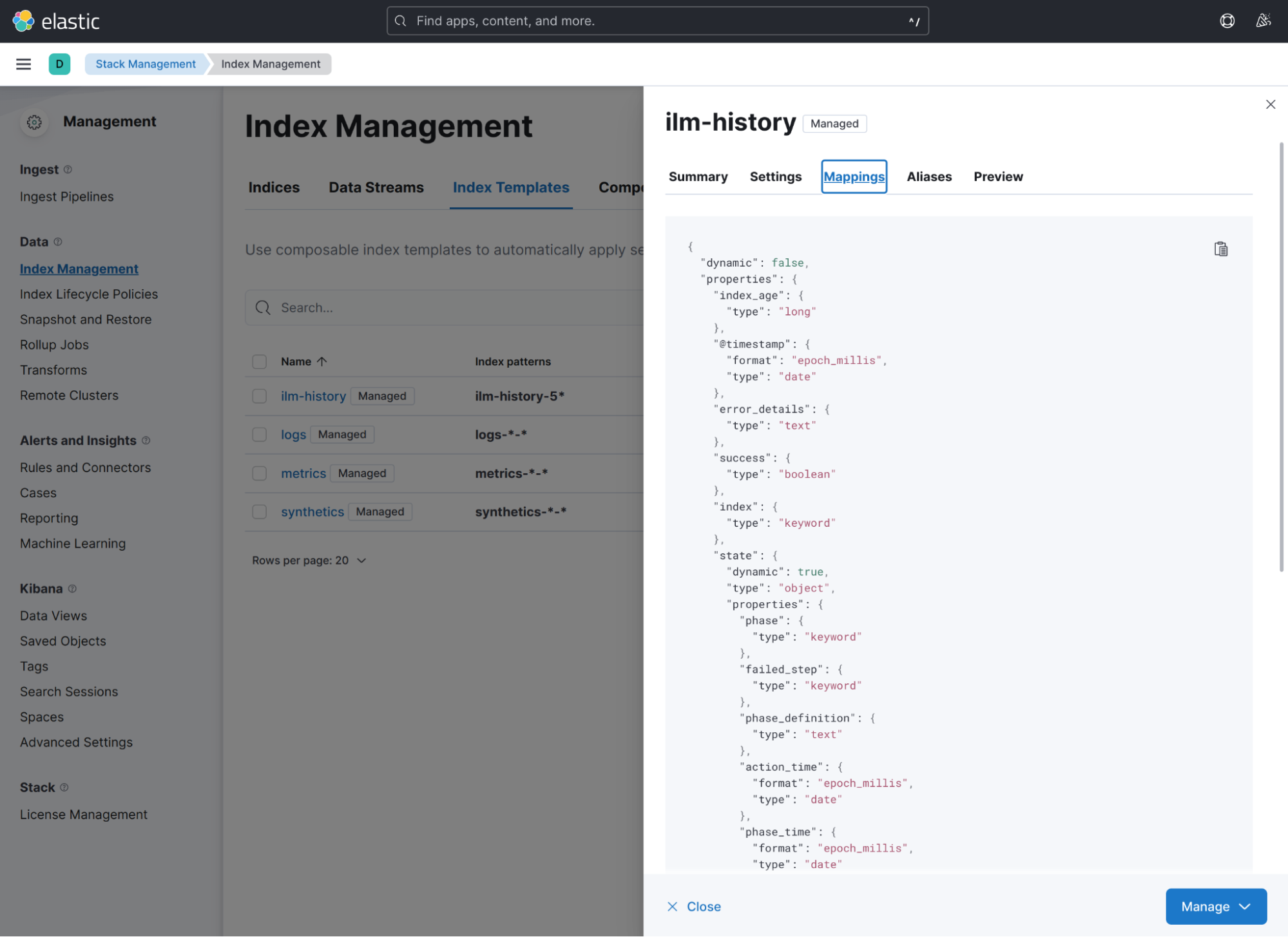
As you can see, these mappings are very similar to a JSON schema. They describe what properties will be available in the data and what type they will have. You can also check, that not all templates have mappings defined. You can just put a document to some new index without defining mappings. In this case, the dynamic mapping will be used. It is the dynamic schema approach that I’ve described in “Static vs dynamic schemas” paragraph. To make schema static, you should switch “dynamic” field inside mapping to the "false" or “strict” value and define schema explicitly. In the example, I’ll focus on the dynamic schema approach because it is much more interesting if you want to analyze your data as quickly as possible.
Data ingestion through the data stream
OK, but how to make data available in the index (indexed or commonly called “ingested”)? Elasticsearch gives many possibilities to do that. You have a brand new Elastic Agents approach, Beats, you can transform data using Logstash, processors, or ingestion pipelines. You can read more about that in Elaticsearch's guide. All of those options are pull-based. The pull-based approach is nice because you don’t need to worry about Elasticsearch’s temporary unavailability. Some of them like Logstash give the ability to send data to more than one destination.
But for a simple use case, you can also use a push-based approach. You can post data using Document API via:
But as I mentioned before, it is better to write documents to indices partitioned by time e.g. some-index-2023.01.09. You can do that on your own by extracting some timestamp field and passing it to the index name but also you can use data stream for that. A data stream “dispatch” documents to correct backing indices by @timestamp field.
To make it work you have to create an index template that defines that indices matching, given index pattern will be interpreted as data streams. To do that, use the script available in the repository.
After that post some data to event stream. You can do that by invoking:
After that events-business_event-default event stream appears in data stream tab:
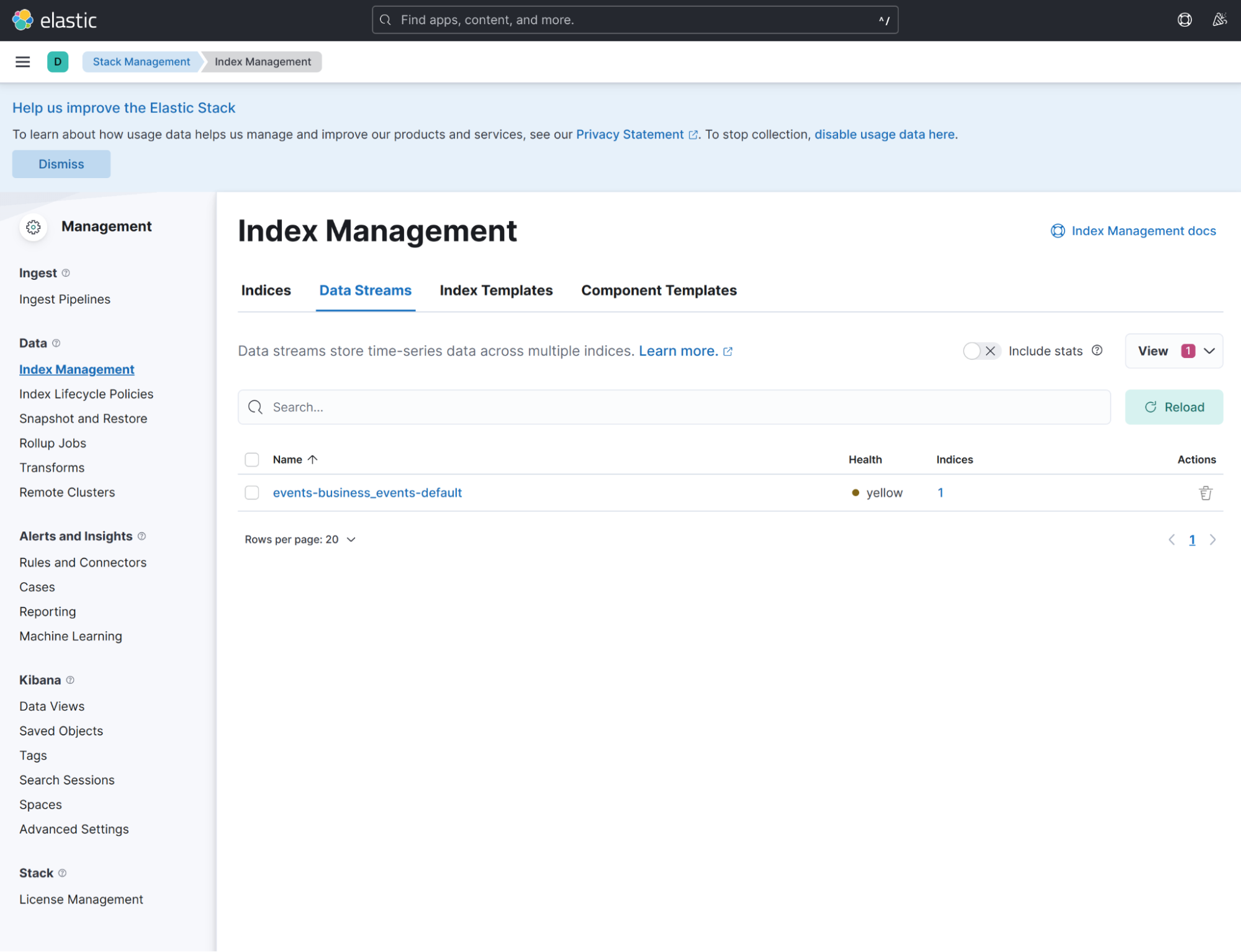
Also, you can find out that in indices tab there is a hidden index called .ds-events-business_events-default-YYYY.MM.DD-000001 available. The index will have mapping generated based on data available in the event.
From Elastisearch to Nussknacker via Kafka Connect
Now we want to make those data available in Nussknacker. Nussknacker doesn’t have a built-in Elasticsearch source but we can save those data to Kafka and after that read them by Nussknacker from it.
For transferring data from Elasticsearch to Kafka we can use Kafka Connect with Elasticsearch's Kafka Connect source. In the example, Kafka Connect with this source is already installed and configured. You can now just add a connector using AKHQ or using provided ./put-connector.sh script. This connector reads data from Elasticsearch indices and saves them to the Kafka topic. During this process, Avro schema is also created.
Now you can just open Nussknacker and create a scenario using documents from Elasticsearch:
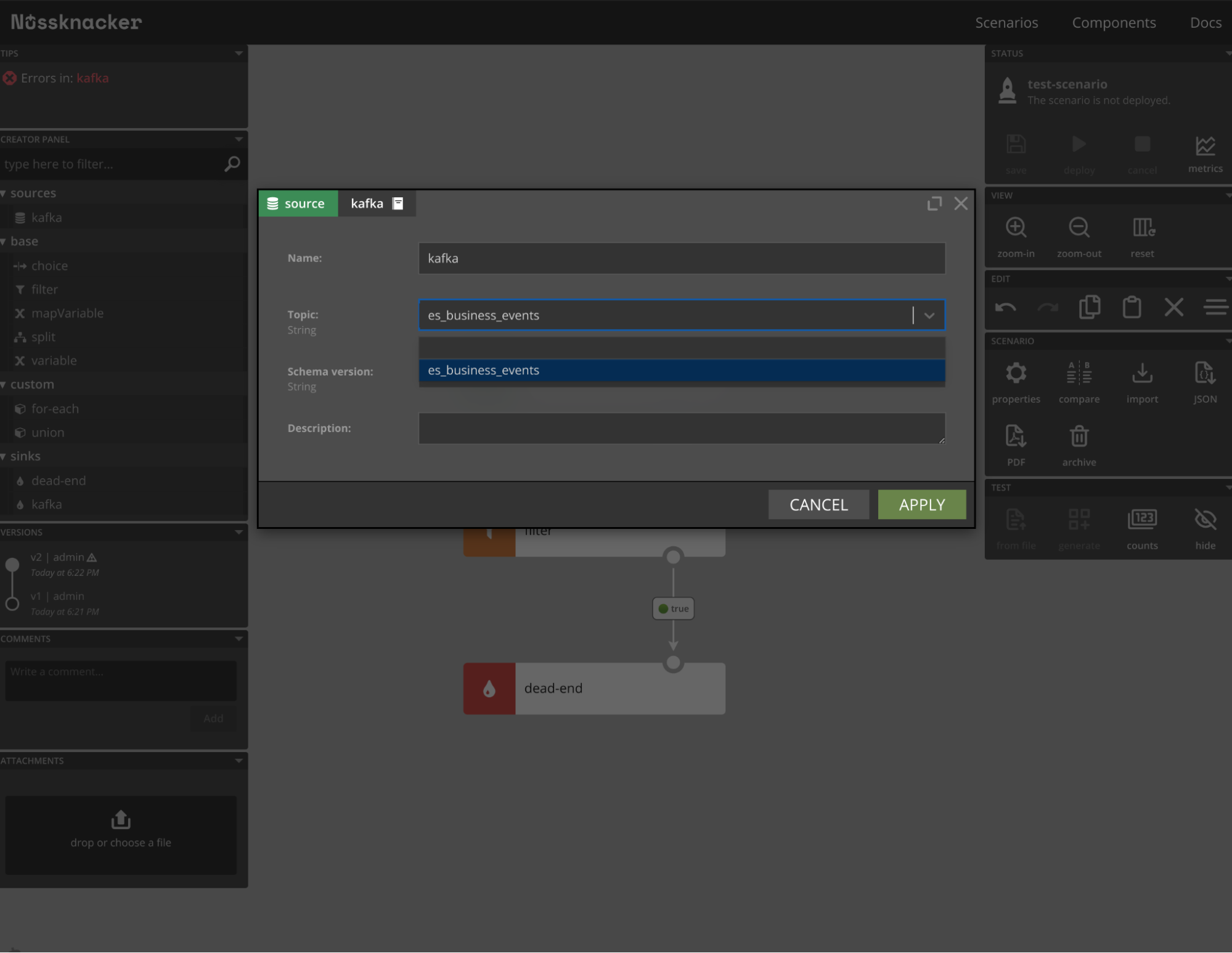
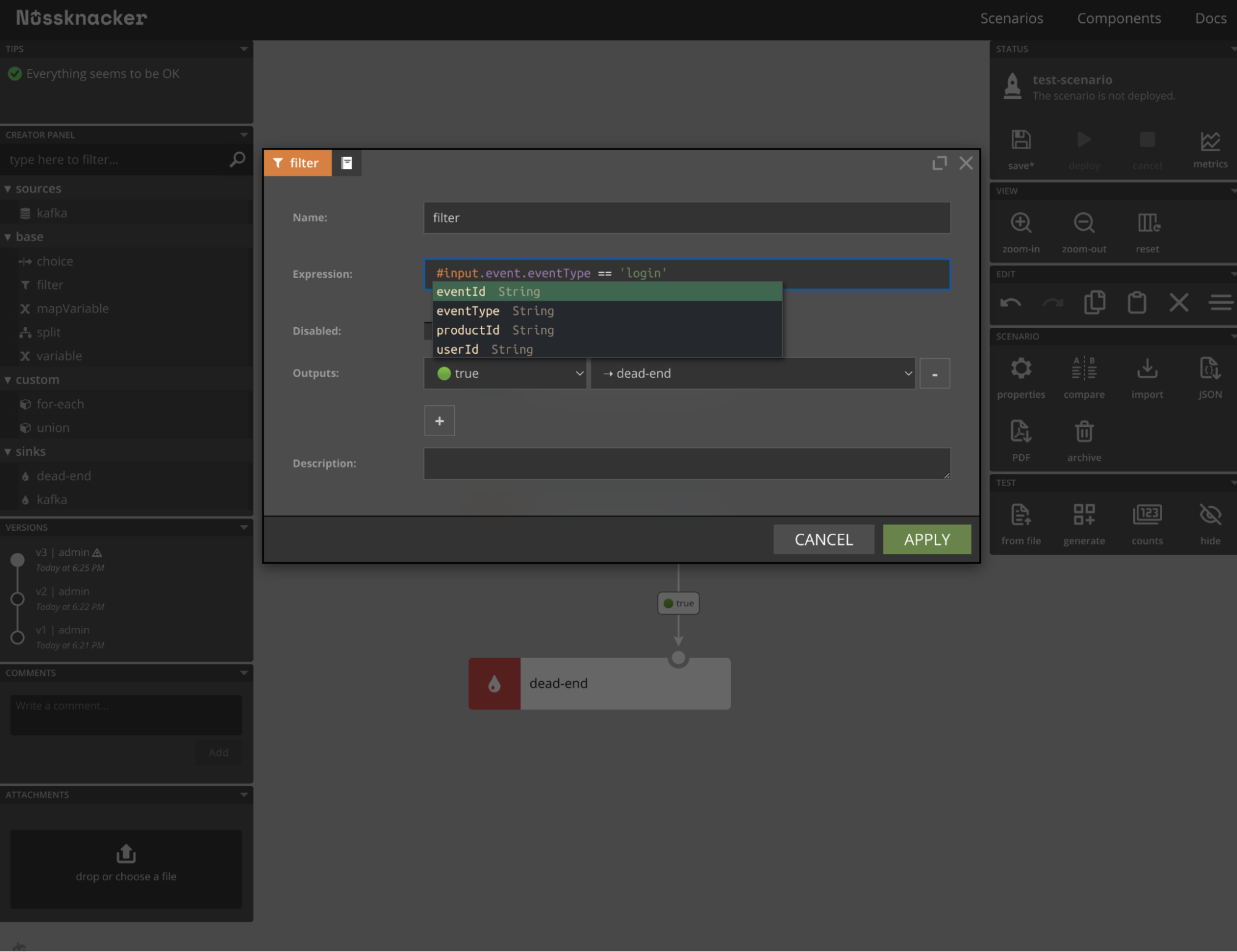
You can check e.g. by filter component that the “input” object has the field “event” on which completion and validation work as expected.
BTW: this example scenario is available as a test-scenario.json file in the repository - you can import it if you want.
Nussknacker evolves all incoming events to the latest schema version
Let's say that our events evolved - a new “productId” field was added. It is a very typical situation during using document databases so it should be painful during storing new document:
After checking the mapping you’ll see that the new field is available. What about schema inside schema registry?
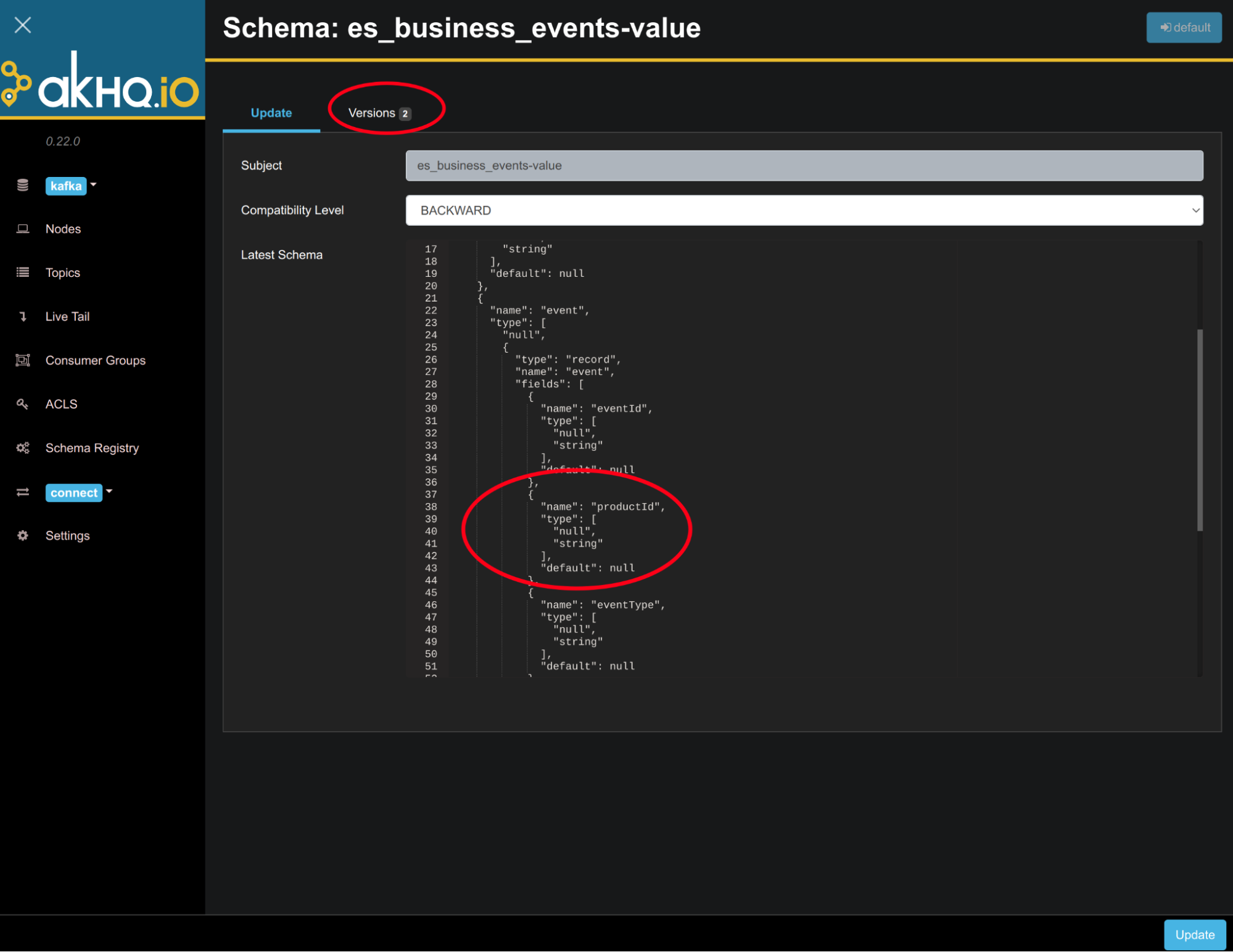
You can see that the new version with a new optional field is available.
How to use it in Nussknacker? You need to just refresh a page and voila - productId is already there:
The magic happened because by default Nussknacker uses the “Latest version” in Kafka source:
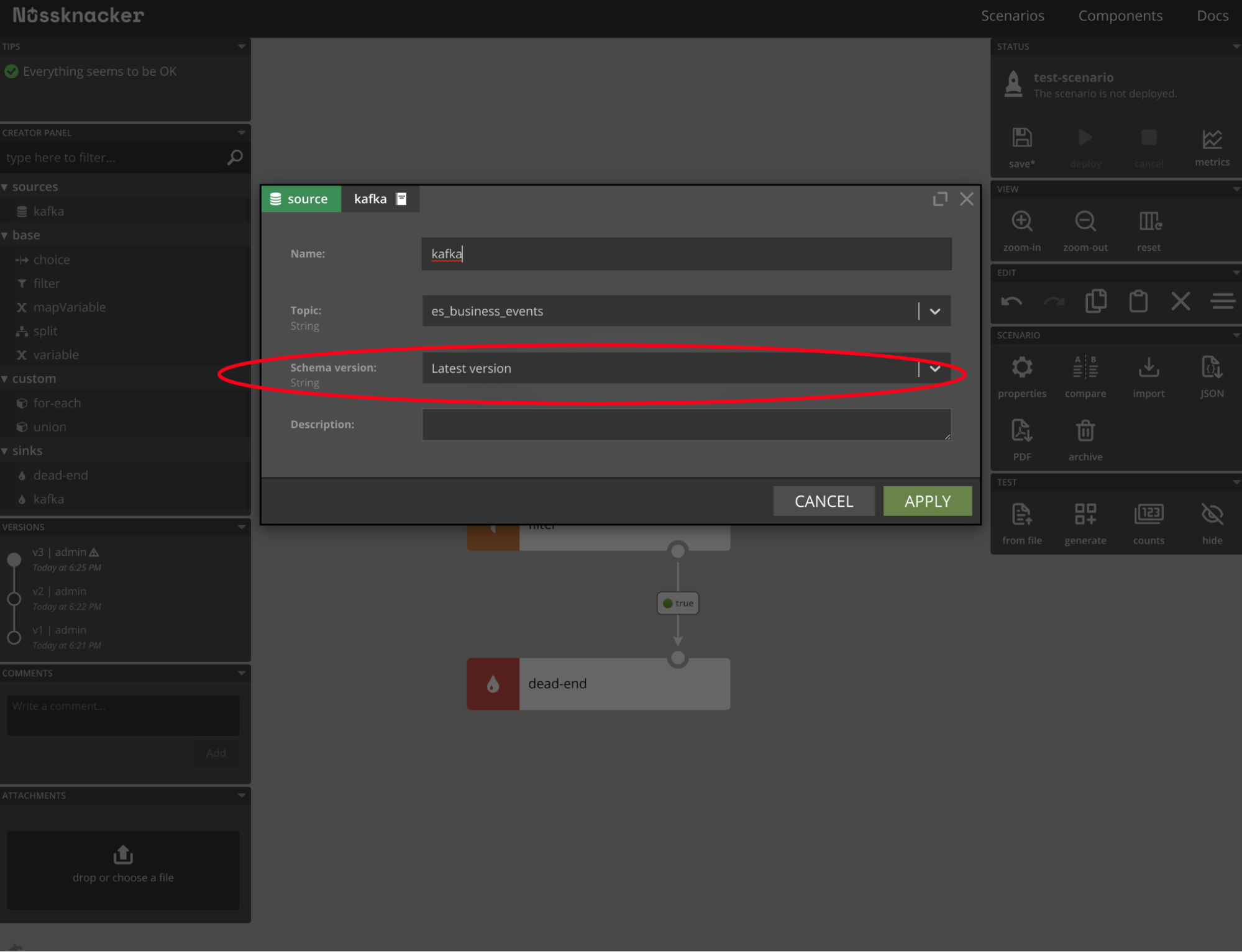
Thanks to Nussknacker’s schema evolution support, it will evolve all incoming events to the latest schema version. If productId will be unavailable, the default value will be used.
You might ask how this Avro schema is related to Elasticsearch mappings. It is not exactly the same. Kafka connect creates Avro schema for the purpose of serialization - it is based on document fields, not based on the mappings. It has some disadvantages:
- We can’t use information about the “logical” type behind the field e.g. when a given string represents a date
- When you remove some field from the document, it will be removed from the schema as well. The new schema will be still compatible with the previous one because all fields are optional, but you won’t see old fields in autocompletion
For “full” integration with Elasticsearch it is necessary to make Nussknacker use Elasticsearch mapping instead of generated Avro schema but for many cases, given solution will be OK.
Dynamically changing schemas are handled in the right way
In the example, I showed how Kafka Connect can be used to integrate Nussknacker with Elasticsearch. Nussknacker leverages Kafka Connect’s Avro schemas autoregistration feature for purpose of providing nice autocompletion and validations. In the end, thanks to Nussknacker’s schema evolution feature, dynamically changed schemas were handled properly.
It showed that Nussknacker and Elasticsearch are a good match and you can define your own real-time actions on documents available in Elasticsearch without a hassle. How do you use your data available in Elasticsearch? Do you use some external tools to invoke actions on them or only use them for analysis inside Kibana? Please share with us your experiences on Twitter/LinkedIn.