check out also the latest blogpost where we go through the complete process from training a model to inferring it in business logic and later refining the model
Jun 24, 2022
The Nu Blog
Non trivial processing ml models algorithms built and deployed in an easy way
Is your ML deployment scenario a trivial one?
There are many platforms for serving ML models to choose from: KFServing, TFServing, and Seldon - just to name a few. They provide a rich set of features, including A/B Testing, Multi-Arm Bandits, explainers, drift detection, and many more. If your use case is:
- all your model input data is immediately available to your program - for example in the file; you do not need any data enrichments or decision logic;
- you have idle programmers happy to code data enrichment and decision logic in the programs which call ML models;
- you are not in a hurry to deploy the next version of the model if data enrichment or ML inputs changes
then you are all set. You can stop reading this post, it is a waste of your precious time.
If you reached this paragraph though, it means that your case is not as trivial as many tools would like it to be.
Let’s come up with a scenario that I would argue can be encountered in real life very often:
- Data is read from some ‘source’ which can be a stream of events, file, or a REST API call. Let’s imagine that not all data required by the ML model is available in the source.
- Some non-trivial filtering logic should be applied to the input data - you want to run models only on data records meeting some criteria.
- If you run models on events from data streams, you may need to compute aggregates in time windows. For example, you may need a sum of customers' transactions in a time window or a count of sensor measurements when a readout exceeded some threshold value.
- The missing data which are needed for the ML model are read from the database.
- Two or more ML models are invoked.
- Some decision logic should be applied to the models’ results; maybe the first model would feed results to the next one or some logic should be applied to decide which model returned a more optimal result.
- Final result should be written to some kind of a ‘sink’.
What are the skills needed to build all this? “Regular language” programming skills - probably Java or Python, Kubernetes (just have a look at this Seldon config for the “Two ML models called in parallel”), understanding of Kafka, JDBC / ODBC, Flink (if you need aggregates in time windows). This is quite a lot. Not many organizations have the comfort of having highly knowledgeable Java / Kubernetes / Flink / Seldon (or equivalent) developers and experts on board. If you are starting from scratch and your use case is not a trivial one, your team may have months of a steep learning curve ahead of them.
Interestingly, if programming skills are not on your problems list and you have plenty of programmers keen on playing with new technologies, you may hit another problem after a while. When the learning curve issues are over and initial excitement with new technologies fades, your IT guys will tell you that they are bored with what they are doing. In the very end, unless you have a very complicated case, the coding work seems repetitive and devoid of challenges - the whole logic can be synthesized into seven steps outlined above. Not so exciting anymore. Sooner or later your programmers will start looking around who might replace them in the mundane job of modifying their programs. Unfortunately, most likely there will be no candidates and the reason there will be no candidates is that this work requires non-trivial coding skills in multiple technologies.
Is there a way out of it? Can we offload programmers from the chore of modifying input fields, enrichment database lookups, and computing aggregates in time windows? Can this be achieved in such a way that even non-trivial modifications, not to mention completely new logic could be built in minutes or hours rather than days? By non-programmers?
Here comes Nussknacker to your rescue - if you already have your input data and enrichment db, you can visually build the Nussknacker decision scenario literally within minutes and have it deployed with a click of a button. Just take the Docker Quick Start version, modify the enrichment database and Kafka broker connection parameters, and off you go, you can start authoring decision scenarios. Unfortunately, because of the licensing limitations, the PMML Ennricher component is not Open Source and is not available in the Quick Start. If you are interested in licensing it, please contact info@nussknacker.io for more information.
ML models inference with Nussknacker
In the picture below you can see how a scenario outlined at the beginning of this post would look in Nussknacker. In our case, the Kafka topic is used as a source of input data. You can check this scenario out live on the Nu demo site here; double-click on the nodes to see how they are configured. Typically a node takes one or more parameters.
Nussknacker uses SpEL expression language to define these parameters. Because SpEL is a highly expressive language, quite powerful expressions and hence data manipulations can be done using it. SpEL difficulty level can be compared to intermediate Excel, in the simplest case though, you may not even notice that you are using some kind of a programming language. Definitely, it is way easier to define the scenario logic using Nussknacker and SpEL than using alternative tools. As an example take a look at Seldon - you specify data transformations and scenario flow using yaml. That’s ugly and hard to understand.
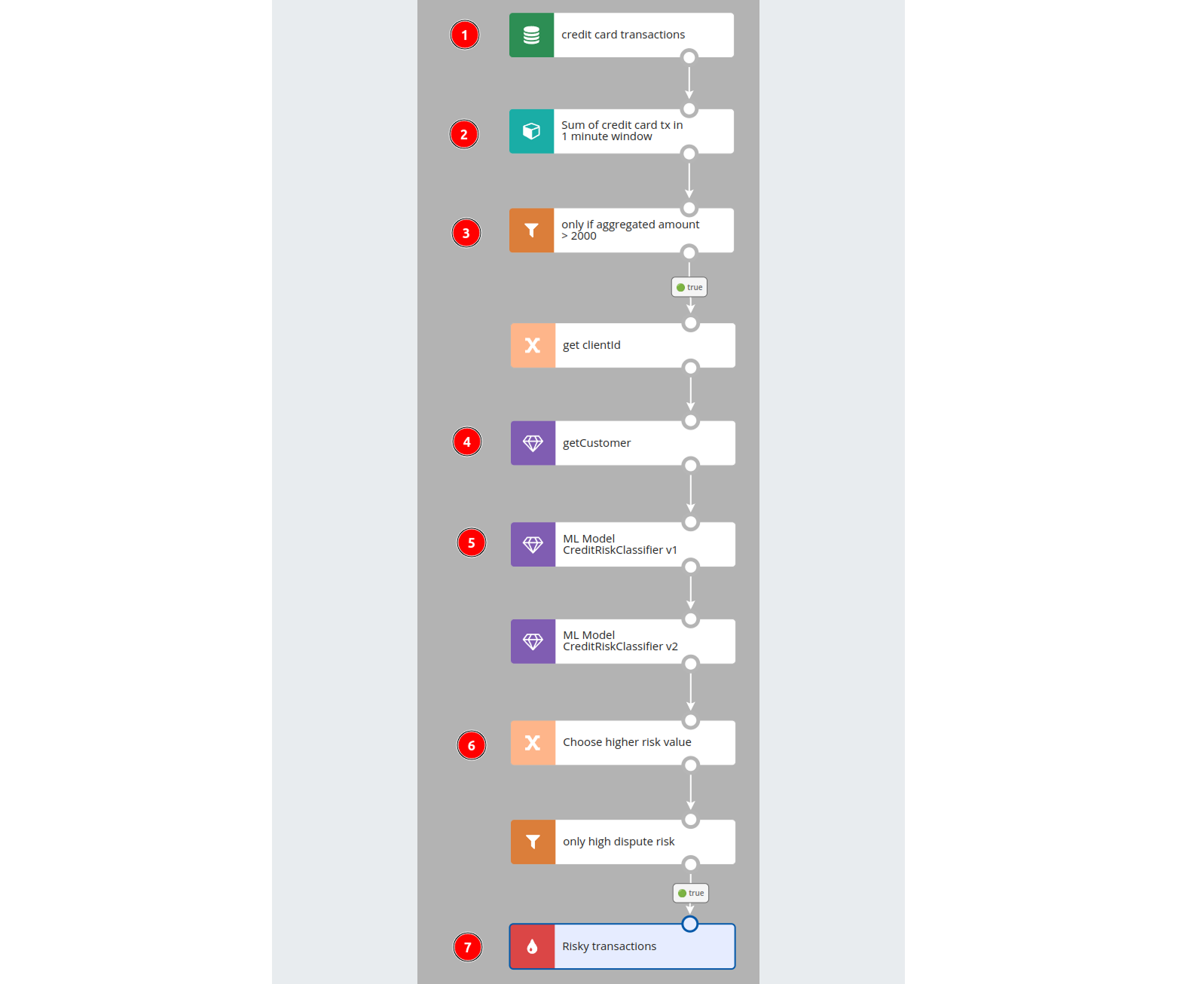
The Nussknacker scenario building blocks explained:
- Read from Kafka source. If you set up the Kafka url, you will be able to choose the Kafka topic from the list of existing topics. If you decided to describe your topic using Avro schema, Nussknacker will know the content of the event and will help you with syntax hints and validations.
- Aggregate card transactions in the time windows. We compute the sum of card transaction amounts in a 1-minute window (we would make this window longer in any real-life application) - the ML model expects this sum as a parameter to the model.
- Filter out cases with an aggregate below a certain threshold.
- Enrich data. We use OpenAPI enricher to get the client category from the OpenAPI service; we will use category value in the last step of the scenario when writing to the output Kafka topic. The client details look-up is made based on the #clientId variable.
- Invoke ML models. Nussknacker can integrate with models in various ways - PMML encoded, deployed in containers exposing REST API, exported with H2O Mojo / Pojo. Automatic model discovery is possible with the MLFlow registry; custom registry integration is also possible. As a PMML encoded model is used in our case, Nussknacker can infer what are the inputs and outputs to the model and generate on the fly a component that can be later dragged & dropped in the scenario.
- Choose a higher dispute risk value. We have dispute risk scores returned by the ML model in version 1 and version 2; we choose a higher value between the two.
- Write to the Kafka output topic. Once we have high-risk cases in the Kafka stream some other system can act on them.
Uh, this was easy and fast; wasn’t it? The scenario can be deployed to the target processing environment (engine) with just one click. You will not be able to do it on the demo site though, as scenarios running there are read-only.
Detecting the new ML model
Getting the ML model right requires a lot of experimentation. Fortunately, Nussknacker comes to the rescue here: when a new model is placed in the model repo, it will be autodetected and a new enricher component will be added to the components palette in the Designer. No recompilation, no configuration file changes are needed. If the input or output model parameters change and you try to use a new model in a scenario, Nussnacker will immediately detect data type mismatches, input parameter names mismatches, etc. Additionally, scenarios are versioned, so you can go back to some previous versions.
If you need to modify the scenario logic, the time required to deploy the next version of the scenario can be just minutes - no need to involve the IT department. You can test tens of versions of your decision logic per day easily. Just modify a couple of SpEL expressions, drop a new node onto a diagram, and click the deploy button.
ML models inferring in business logic
You can use Nussknacker to design and deploy ML models in use cases where complex decisioning, data transformation, and enrichment logic are needed. The decision logic you can build with Nussknacker can be pretty sophisticated - we moved the bar of how much you can achieve with low code to pretty high. Scenarios can be authored by non-programmers, typically subject matter experts, using a visual tool that gives immediate feedback in case of erroneous configs. As a result, you can not only offload your IT team but also - and more importantly - engage your experts in the development/test cycle. Finally, the author/deploy cycle length can be down to literally minutes.
The demo
Nussknacker can use different engines fit for different architectures and deployment scenarios. Currently, there are two engines available: Streaming-Flink and Streaming-Lite (without Flink). A third engine is on the assembly line - the Request-Response one, with which you will invoke Nussknacker scenarios via REST API.
Configuring enrichers like OpenAPI enricher, SQL enricher or PMML enricher is fairly straightforward; once they are configured Nussknacker Designer will automatically generate appropriate components (the “processors” you drag and drop in the scenario) and make them available in the components palette.
The ML model used in the demo can be found here.
Enjoy!
Free consulting: book a 30 min call with developers behind Nussknacker
The Nu Blog
Filip Michalski
Jun 24, 2026
Turn your Flink UDFs and PTFs into low-code components
Kuba Nowakowski
Jun 21, 2026
Serving real-time Kafka data to AI agents through MCP
Łukasz Jędrzejewski
Jun 18, 2026
Typed structured output from LLMs in Nussknacker — no more parsing JSON by hand
Feel free to ask any questions
Nussknacker can make your data processing use case more agile and easier to manage.