Open-source in data streaming
People quite often ask us, what are the differences between Nussknacker and other similar (at first glance) tools. A good tool can be used in many different ways. There are usually some overlapping areas in which many of them can be used interchangeably. But when your system grows, tools used for other purposes than they were designed for, can cost you a lot of pain and can introduce a lot of technical debt.
Our company grew as a software house. We specialized in crafting systems based on well-known, battle-tested, open-source projects. We used BPMN tools like Apache ODE and its “successor” - Activiti. We also have some experience in Drools. After the era of fast growing server side enterprise applications, there comes the time of big (fast) data. We used some graphical tools like Apache NiFi or Apache Airflow for that purpose, but we also deployed programmatically written jobs on Apache Flink. All those tools are good and we still recommend using them in certain situations. But if you want to pick the tool that fits your requirements correctly, you should take a look at them from multiple perspectives.
Imperative vs declarative
Most of the mentioned tools are rather imperative. It means that the user designs HOW something will happen step-by-step instead of expressing WHAT should be the effect of the computation.
Here is an example of both concepts. Let’s say that you want to send an email to each of your vip users who visit your product page side. You can write it in declarative form. One of the most declarative languages is SQL. It will look like this:
INSERT INTO email(user_id, template_id)
SELECT u.id, ‘special_offert’
FROM clickstream c
LEFT JOIN users u
ON u.id = c.user_id
WHERE c.page_id = ‘some_product_page_id’ AND u.segment = ‘vip’
And in imperative form:
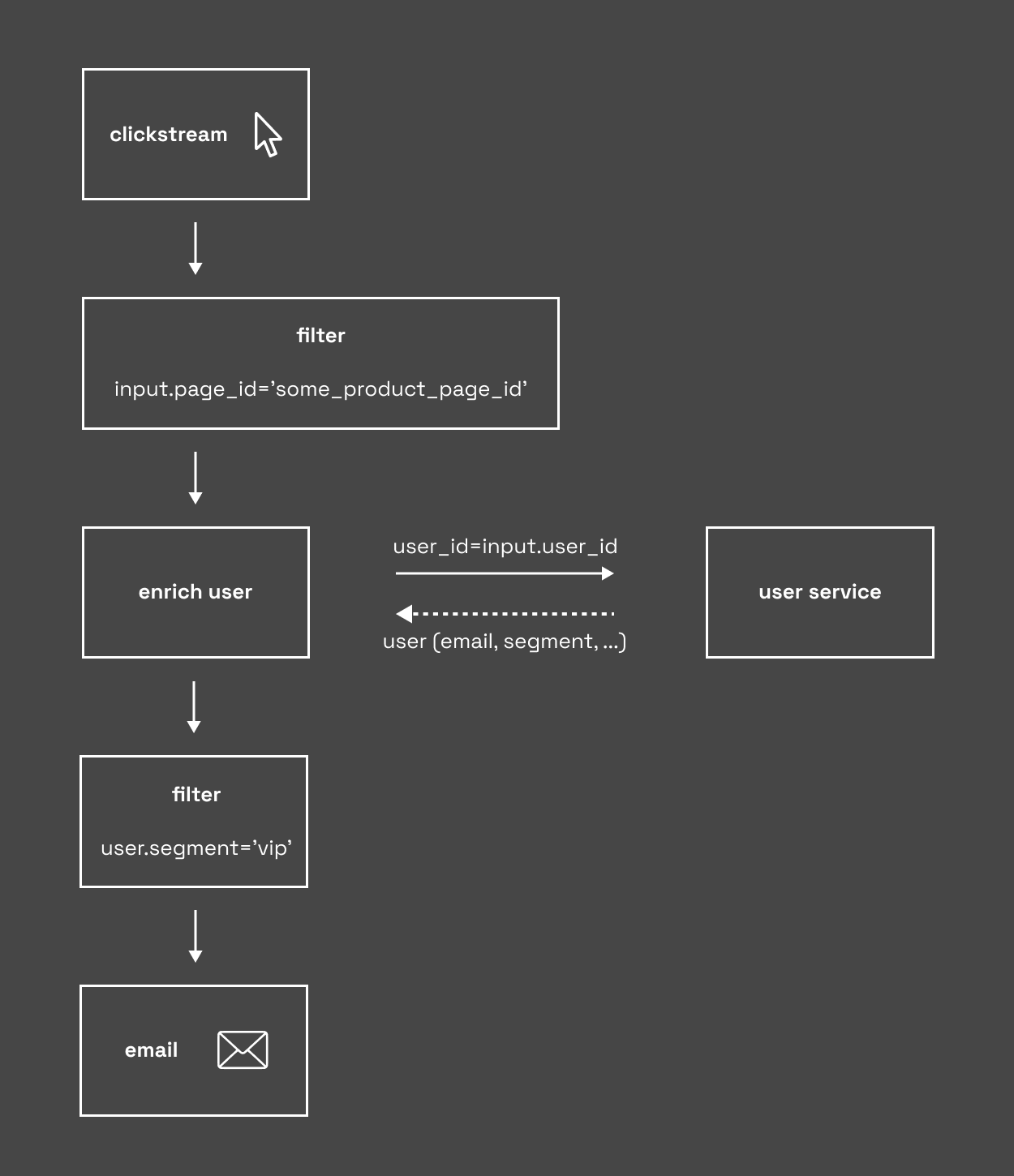
You can also write the same using some imperative programming language like Java - it will look quite similar.
There are advantages and disadvantages of both ways of expressing things. First of all, the declarative form is more effect-oriented instead of method-to-achieve-effect-oriented. It can be a big advantage - you don’t need to think how the user is joined with the clickstream, it just happens. On the other hand, the imperative form is more natural for people. It is quite often that your business team sends you a draft of their concepts written in e.g. visio diagrams or similar tools. You can translate this description to imperative language straightforwardly.
Things become more complicated if you think about more complex examples with some aggregations, switches with multiple choices, splits, and joins. Declarative ways of expression can be limited and hard to understand. Also, it is harder to monitor what happened during execution. Take a look at the example above. It is easy to present how many events are rejected on the first filtration and how many on the second one.
Business logic vs integration logic
Because of those benefits, when considering different tools, you or your business team will look for a graphical tool with some kind of activity diagrams. But not all graphical tools are for all purposes. Take a look at the chart below:
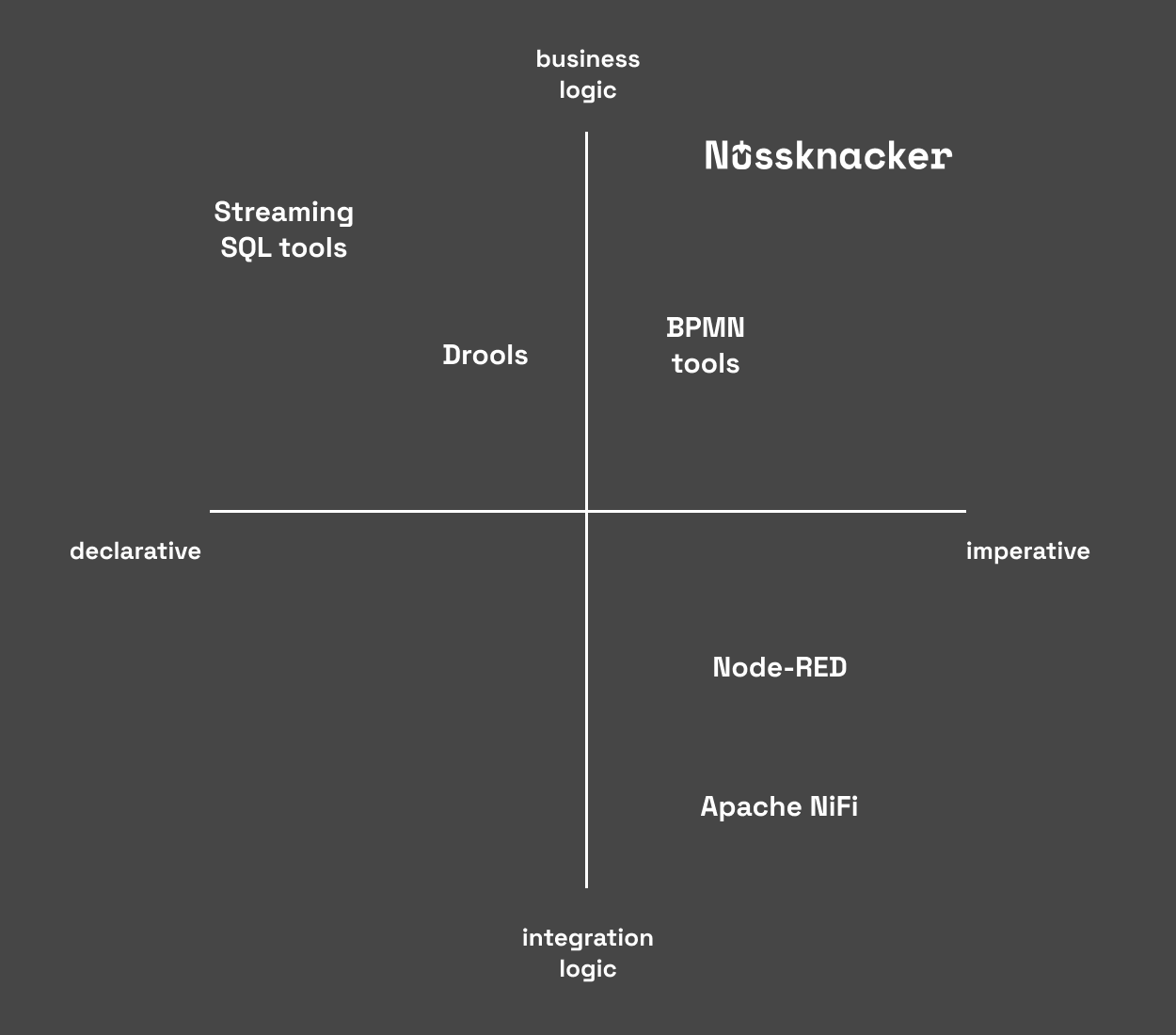
Apache NiFi is a graphical tool for running flow diagrams. At first glance, you may think that it is good for writing your business logic. But the greatest power of this tool is the ability of integration of many sources and sink types and message formats. You can easily read files from disk, translate xml to json and send it using JMS. Yes, you can also write your business logic there, but it won’t be easy to achieve. You don’t have things like variable fields completion and validation of expressions. Also, you need to be aware that messages are computed in batches and the order of them can be shuffled if you won’t handle concurrency correctly. Such technical details usually obfuscate the business meaning of a diagram.
On the other hand, BPMN tools are rather business logic oriented. Still, usually, those tools don’t give you too many options to write this logic by real business users. The greatest power of those tools is stateful processing. Deployed business processes can live a long time. During this time many systems can be involved in the business process, many things can change and some state migrations can be needed. Because of that, it will be better if business processes will be implemented by engineers with good software development skills. But still, it will be a huge benefit for your company, that your software development team will have a common language with your business team thanks to those tools.
Nussknacker is also an imperative tool. It hasn’t got too many options to ingest messages - it should be delivered on the kafka topic as an avro or json. But on the other hand it has features that make writing business logic easier. You have variable fields completion, expression validation and types inference. You can test your business scenario before deployment and monitor how it behaves after deployment.
Scalability
Take a look at the chart below.
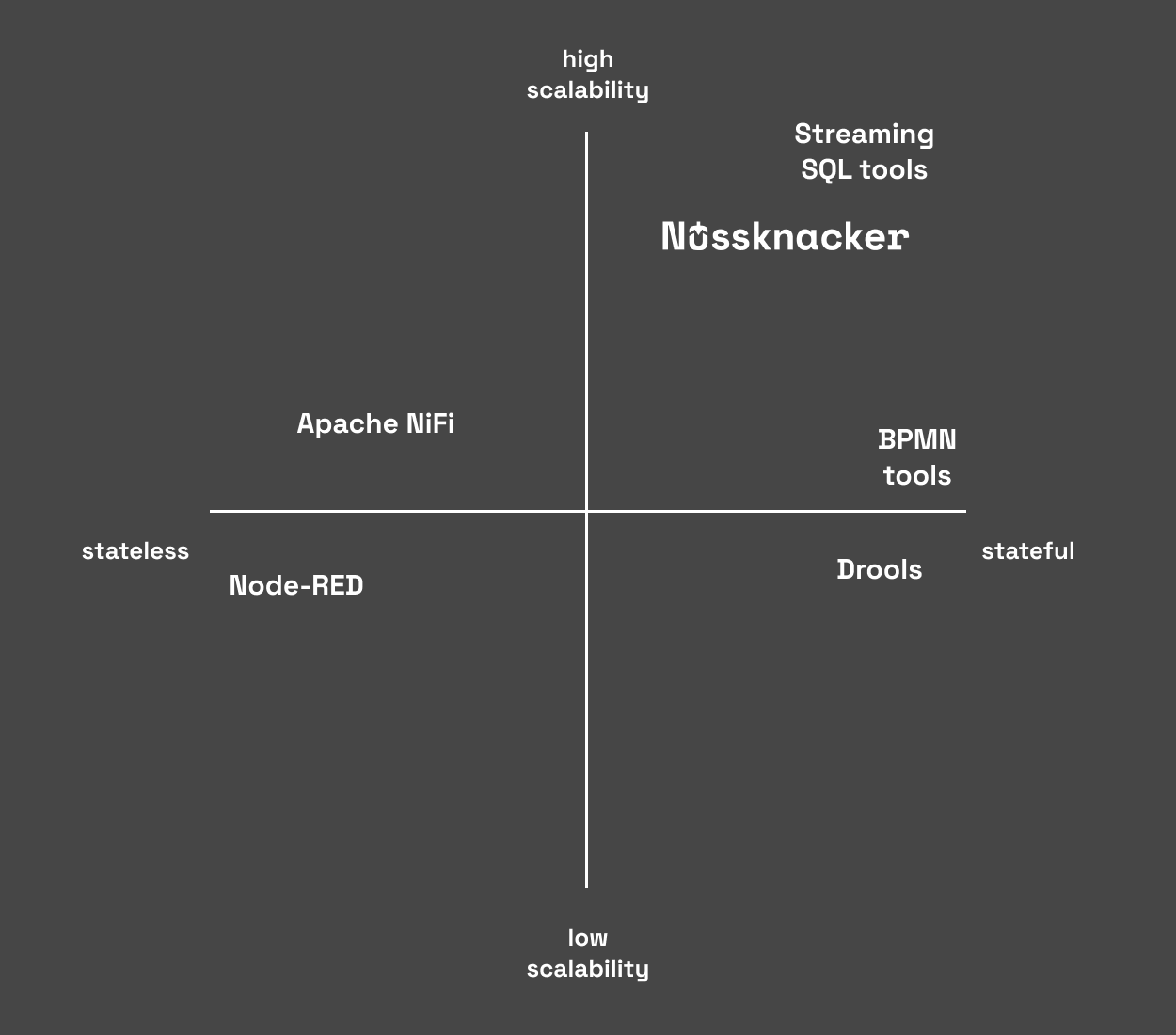
If you take a look at those tools from a scalability perspective, you will see that not many of them give you very good scalability. Most of those tools are written effectively which means that they will scale up vertically and will use most of the potential of your CPUs. But not too many can scale-up horizontally. It is easy to scale up a stateless microservice. But when the application has state or consumes messages from a high intensive stream (e.g. from Kafka), it should be designed in a way that allows each step stream to be partitioned correctly and messages are not shuffled randomly.
Because of that big (fast) data ecosystem is mostly dominated by tools for software engineers. There are some high-level tools like KSQL or Flink SQL but as I wrote before, they are declarative tools. They may be ok for some purposes but in other cases they may not be enough. If your business logic is written by analysts and you aren't afraid of glitches in communication between the analytics team and business team, then they can fit your requirements. But if you expect that your business logic could be more complex in the future, you want to shorten your OODA loop and think about tightening relations between your business team and software developers/analytics team, you should consider tools like Nusskancker.
Fit for the domain
The open-source applications world is wide and fast-growing. You can find a lot of tools that look similar and sometimes can be used interchangeably. If you want to build solid architecture, you should consider many aspects: which user will use them, and what problem you want to solve using them (is it a technical problem or a business one?). Sometimes you should consider using more than one tool. For example, we quite often recommend the usage of Nussknacker for modeling business logic and Apache NiFi or Kafka Connect for message ingestion. If you want to learn more, take a look at our Overview page