How low-code and open data standards allow fast TTM
The world of finance and banking is changing pretty fast. The concept of OpenBanking is changing the way we look at FinTech. Driven by both startup innovation and regulations such as EU PSD2, the idea is to have a common set of APIs that will allow for customer data access, transaction initiation, and so on.
Of course, the crucial point is that the financial institutions provide access to their systems, however equally important is the vision that those APIs are standardised - so that service providers do not have to develop integrations with each of the banks separately.
When integrations are easy, the pace of innovation and the creation of new products increases. The problem of reducing TTM and shortening development cycles becomes paramount. With the shortage of developers, and backlogs filled for the coming months - how can the business experts deliver their ideas?
The answer can be as simple as: “let them do the work by themselves” - but as we know, this sounds simpler than it is. The low / no-code tools often do not deliver on their promises - why should this be different? We argue that one of the reasons is the standard form of communication.
We’re not talking about technical protocols - Kafka, gRPC etc. They are important for the developers and do make integration possible, but for the domain experts, we need something more. We need common business data formats - with accessible documentation, and examples, relieving the users of having to think about date formats, decipher cryptic field names etc.
Only with such well-prepared data, the users can successfully use a tool - such as Nussknacker.

Turning data into actions
To show what can be achieved, in this post we’ll tackle the challenge of taking the following:
- Generated transaction data in standard, industry format
- Simple fraud prediction model, taken from “the internet” - i.e. the kaggle
- A few pieces of additional data (e.g. a database of postcode locations)
We’ll show how Nussknacker can turn those data into actions - that is, decisions if a given transaction is a fraud or not.
We want to emphasize that the building blocks are based on standard formats, not specifically crafted for the case.
If you want to have a look at the full example and play around with it, it’s on GitHub: https://github.com/TouK/nussknacker-card-example
The data
For quite a long time, ISO-8853 was “the” standard for handling card transaction data. It is a binary format, with rather limited capabilities for additional data. Fortunately, after many years of struggle, the adoption of the new ISO-20022 gains traction in the industry.
It’s XML based, meaning that we get a standard language of description - XML Schema. Unfortunately, while XML was state-of-the-art in 2004 when the standard was created, now it seems a bit antiquated. This isn’t a problem, as there are translations to more modern formats, such as Protobuf or JSON Schema. For this article, we’ll use JSON Schema definitions from https://iso20022.plus/api/json/.
We’ll use CAIN.001.001 messages (Acquirer Authorization Initiation) to track initiations of card transactions and act on them.
To generate the data, we’ve used a simple python script that sends it to Kafka topic. We don’t fill all the fields, as there are literally hundreds of them. We just fill in the required ones, and the ones required for our algorithm. Please remember that we’re no experts here, we prepared the script based on the documentation!
Of course, in real life, some additional processing probably would be needed (e.g. stripping the message of security data etc.).
What about the output? The scenario response will be a part of CAIN.002 message - that is Acquirer Authorization Response. Now, you may wonder why we don’t want Nussknacker users to fill all the fields - contrary to input, where all fields are accessible.
The point is that most fields can have only one correct content - they are technical, connected with security, and others are calculated based on the request. Their content does not depend on the specific business scenario, but rather on general rules. Such fields are far better handled by services created by developers - those rules usually do not change often, yet it’s crucial to fill them correctly.
We’ll want the user to fill in only the following fields: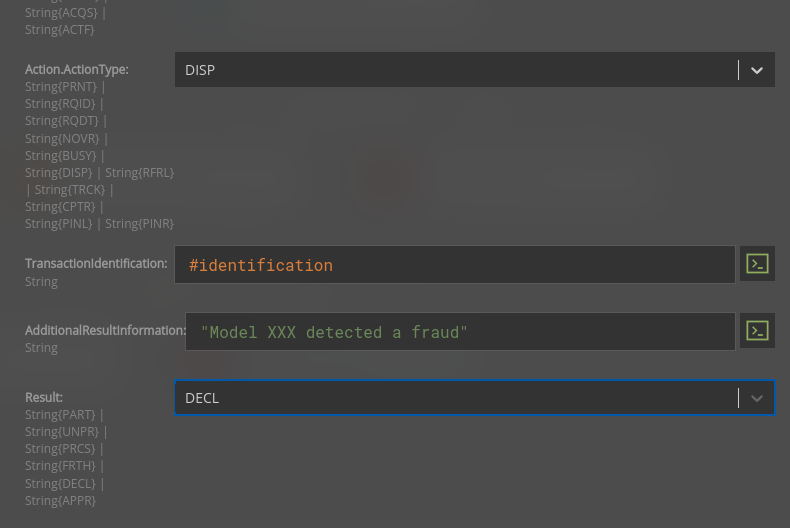
Not so difficult to grasp, I think?
It’s no longer needed to read cryptic technical documentation to understand field format.
And we didn’t need to use custom-prepared connectors (that many products are advertising) for that - just a generic Kafka connector and properly defined schema. Now that we have the data, let’s look at what we can do with them.
The algorithm
So, we have the data - how will we assess if the transaction is a fraud? We will use a combination of an ML model and expert rules. Let’s start with the model. This isn’t a post on machine learning and I’m no data scientist, so we’ll start with something done by the others - after a quick look I’ve found a dataset and a notebook on Kaggle.
It’s relatively simple, yet it will allow us to use some cool features of Nusskacker. The most important thing is that features are understandable - you can find a few models where the data is anonymized with PCA first, so it’s virtually impossible to use it directly to score our simulated data.
Since I wanted to base this post on the OSS version of Nusssknacker, we’ll serve the model with a simple python microservice, exposing the OpenAPI interface. It’s quite easy to do, however, we need to configure enricher manually, know a bit about fastapi library and maintain serving microservice.
If you want better integration with ML frameworks such as MLFlow, (j)PMML, H2O or Seldon - contact us to learn more about enterprise features.
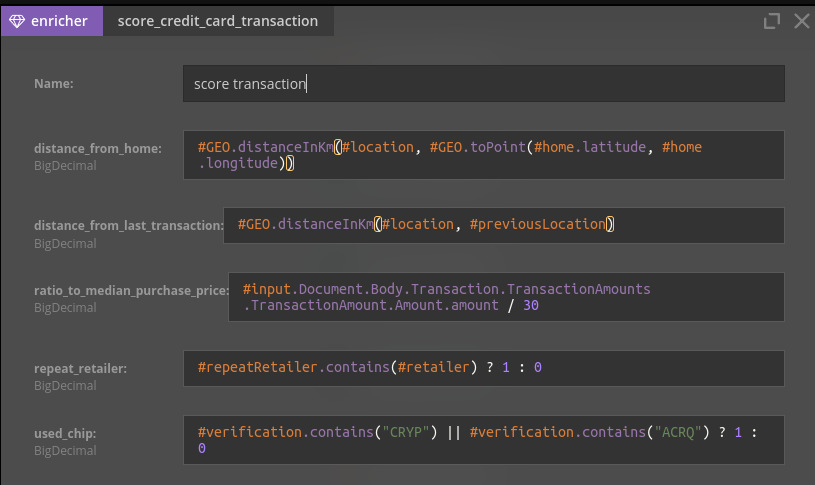
One of the biggest challenges in serving real-time predictions is preparing features - the input to the model. Hopefully, in the future, the Realtime Feature Store will take care of most of it. However, the introduction of such a system is still an underestimated challenge, so in our case, we’ll do it manually.
Some of the features can simply be taken from the input message - these include details about the transaction (if it’s online if the pin/chip was used).
Other features depend also on previous events - e.g. we want to calculate the distance from a previous transaction or if it’s the first transaction for this retailer. Those can be computed with Nussknacker time window components
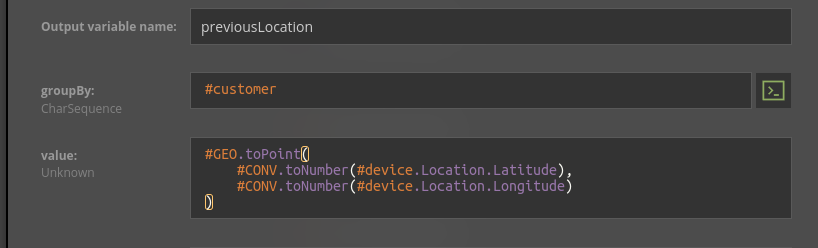
Finally, for some of the features, we’ll need additional data - for example, to translate the payer's address to the exact location. Fortunately, Nussknacker comes with a couple of simple helper functions that allow us to e.g. compute distance.
Expert rules
We got the prediction - so are we ready yet? Of course, we may just say that 1 from the model means fraud, 0 - not fraud, but the reality may be a bit more complex…
Imagine the following situations:
- We’ve learned from trusted sources that some of the accounts/transaction types are used as a source of fraud. It’ll take some time (even if it’s just hours) until our data scientists come up with a new model version
- There is a bug somewhere in the model, causing it to mark all transactions from a given few honest merchants as fraud. Of course, the model will be corrected, but we have to do something quickly to reduce the damage
- The model returns not a binary score, but rather the probability of fraud - how should we set the threshold? Maybe it should depend on the type of customer. Or time of day?
What do they have in common? It’s simple - the model should not always have the last word. The domain experts need to be able to make the final decision if needed. Fortunately, Nussknacker is perfectly suited for such cases. Using components like choice or filter, together with some more enrichers if needed, it’s easy to express pretty complex logic. For example, let's look at how we can implement a simple decision table:
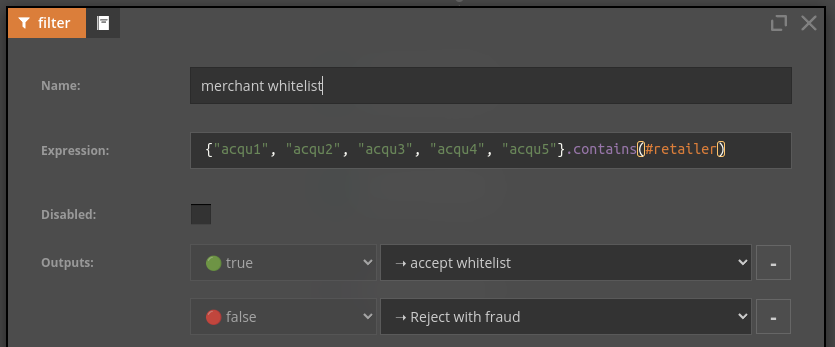
And that’s it - let’s have a look at the whole algorithm:
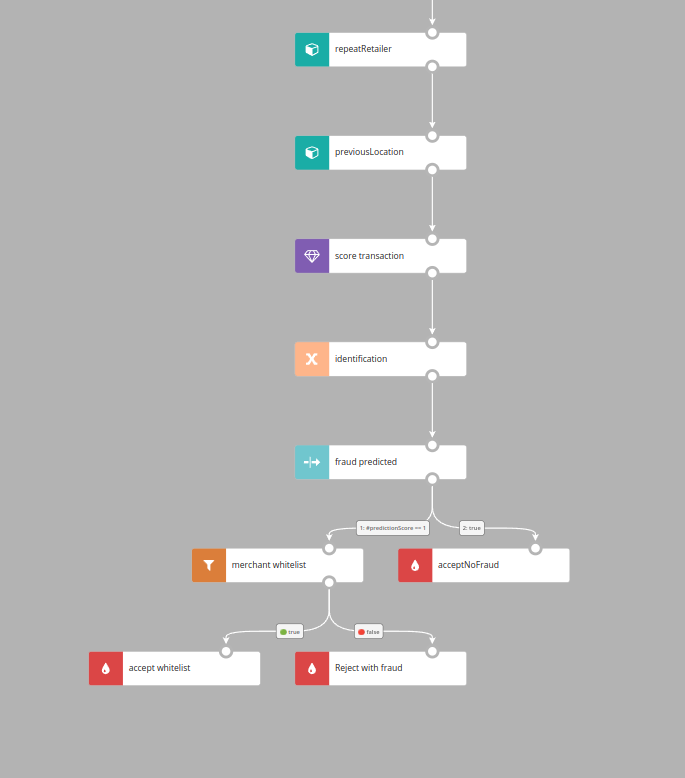
We can run it on simulated data and see how it performs if we need to adjust some thresholds (the change around 8:30 is a result of adjusting a scenario parameter to classify fewer transactions as fraudulent):
Unlocking the business creativity and actions on data
OpenBanking, OpenInsurance etc. are on the rise. To unlock business creativity two things are needed:
- Access to data
- Tools that will let the experts iterate quickly on new ideas
Access to the data used to be cumbersome for two reasons: technical integration (including protocols, authentication and so on) and various, non-compatible data schemas, and structures.
Thanks to the rise of open standards - be it ISO-20022 or various initiatives around Open Insurance, the second problem slowly disappears.
Common technical data formats made it easier for developers to integrate systems.
The rise of common business data standards makes it easier for domain experts to use them.
This makes it possible for the experts to act on those data with a low-code tool such as Nussknacker, to make changes and innovate much faster.
You can run the whole case with the sample code. If you have any questions or insights, or you are interested in NU enterprise features: enterprise@nussknacker.io.