I believe that using SQL in streaming is, in many use cases, counterproductive and confusing. Let me explain.
Acting on streaming data is not easy unless you are a Java (or Scala developer). To make streaming data more accessible both Confluent and Flink promote using SQL. Confluent's and Flink's answer on how to use SQL over a stream of data differ - for example Flink uses the metaphor of dynamic tables, requiring you to “mentally convert” a stream into a table and then run SQL statements on it.
To be honest, unless I’m dealing with a simple streaming ETL case (including time windows), I find both approaches confusing—despite having used SQL for almost 30 years. The difficulty isn’t just due to Flink’s fragmented documentation in this area.
For example, it is hard to discern, let alone trace, the connection between a connector’s configuration and whether it produces “updating” or “append-only” streams. In one case I had to resort to taking screenshots from a Flink tutorial and comparing them side by side to spot subtle configuration differences between a connector operating in “update” versus “append” mode.
However, the issues with streaming SQL go beyond Flink’s documentation. Fundamentally, there are two types of streaming applications: streaming ETL and actions on streaming data.
The second category is particularly broad, encompassing use cases like high-frequency trading, fraud detection, real-time marketing, and processing sensor readouts in automotive or manufacturing.
There’s simply no way to build such applications exclusively with SQL—it has too many limitations (which I’ll discuss later). This is where the push for SQL hampers the growth of streaming.
Applications in the “actions on data” category often require significant domain knowledge and hundreds of iterations to get right. In many cases, these algorithms are moving targets, requiring continual updates.
Ideally, these are the domain experts—people with the required knowledge and enthusiasm for improving their algorithms—who should be creating and refining these applications. But SQL, especially in a streaming context, is either insufficient or awkward to use for this purpose.
I firmly believe that the overemphasis on (streaming) SQL in this category is detrimental to the growth of streaming.
It prevents domain experts from entering the space where they could build, experiment with, and refine complex streaming algorithms. Streaming will truly take off when domain experts can build “actions on streaming data” applications without having to grapple with the complexities of Kafka, Flink, or similar technologies. These experts should be able to interact with streaming data as easily as they work with static data in spreadsheets—a tool used by hundreds of millions of people. There’s no inherent reason why streaming data shouldn’t be just as accessible.
Following Python success in the ML field, some may view Python API as an answer to (streaming) SQL limitations. However, the challenges of building streaming applications go far beyond replacing SQL with Python.
To start, because latency matters, while Python’s DataStream API in Flink might suffice for use cases where latency isn’t critical, it falls short for latency-sensitive scenarios, making it only a partial solution. Real-time applications however have unique requirements beyond stream interaction.
Real-world use cases also demand solutions for the e2e technical stack (technical monitoring, algorithm behavior insights, logging) and address unique aspects of actions on streaming data apps: easy experimentation, very short development cycle length, debugging, developer satisfaction (a 100th version of the algorithm not necessarily is a Flink developer dream activity), accessibility for those who don’t know Python - to name a few.
This is very different from using SQL in ETL where both tech stack and the way ETL logic is built is much simpler. Similarly, Python will not be a comprehensive answer.
I believe we need a much more comprehensive solution than simply extending (streaming) SQL or using Python as a substitute to SQL. At Nussknacker we believe we’ve found the answer to streaming’s current dilemma: to make streaming truly mainstream and accessible to a wider audience, as Giannis Polyzos aptly put it.
You can see an example of both approaches on our demo site. The example SQL is taken from the RisingWave blog post; we show how the same logic would be implemented with Nussknacker.
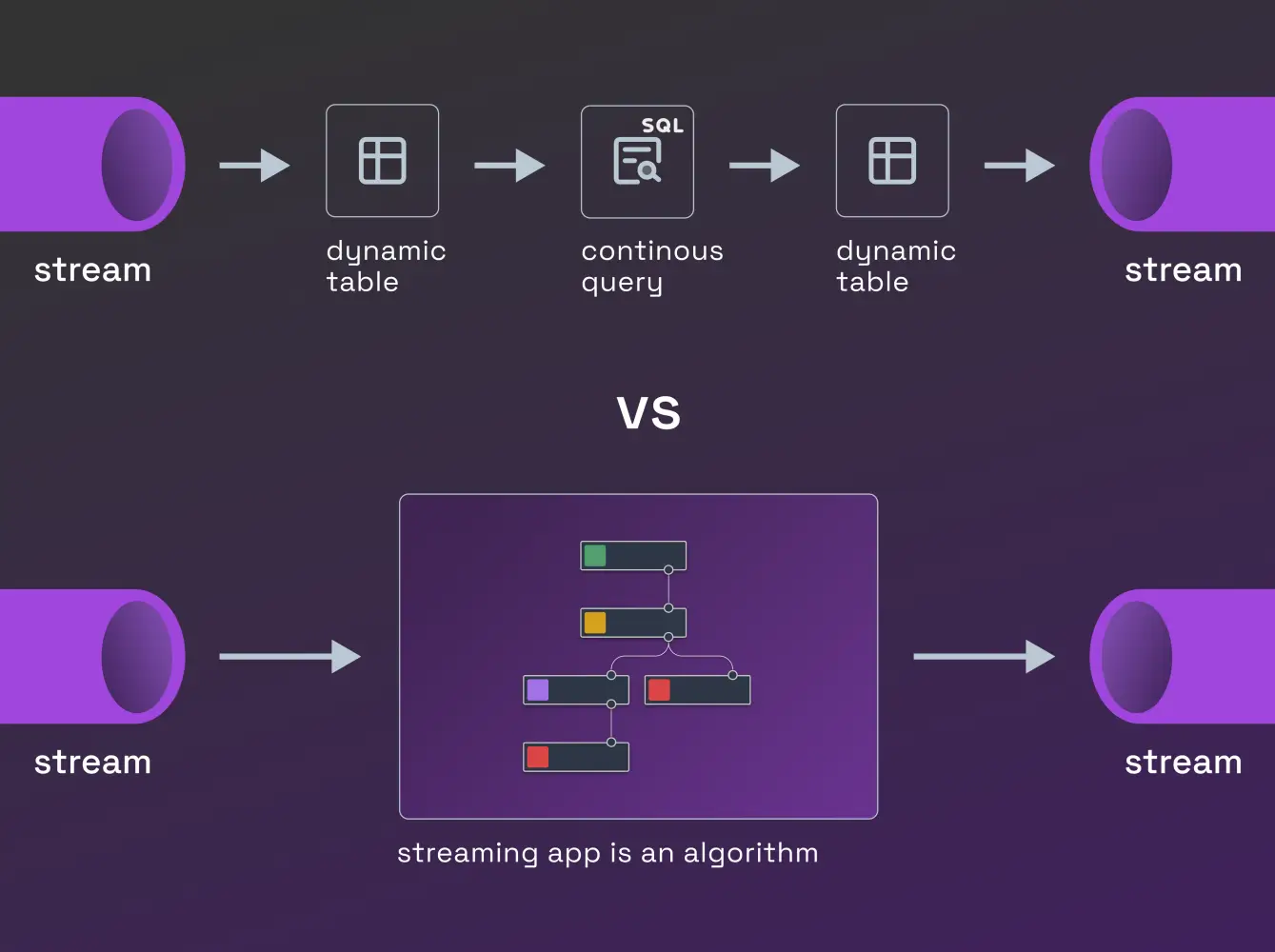
What Are SQL’s Weaknesses in Data Streaming Applications?
- Set-based processing feels unnatural in some cases: When an event arrives, the immediate question is, “What do I do with this event now?” In such scenarios, there’s no set—just a single event. Why force everyone to think of a stream as a table? While the stream-as-a-table abstraction works well for certain scenarios, such as windowed aggregations or streaming ETL, it feels cumbersome and counterintuitive for many "actions on data" use cases. A more flexible approach, allowing developers to choose between set-based and event-based processing, would be far more practical.
- Complexity in non-trivial algorithms: For anything beyond trivial logic, SQL quickly becomes unwieldy. Its syntax and structure are far removed from how algorithms are typically visualized or coded. As a declarative language, SQL was never designed for expressing complex algorithms or accommodating iterative processes. This disconnect often leads to extreme cases—like the 8,000-line SQL statement I encountered at one client. In such situations, poor readability prevents effective debugging or refactoring into something more maintainable.
- Mismatch with algorithm graphs: Many people intuitively think of algorithms as graphs—arguably the most natural way to represent them. However, there’s little connection between the concept of an algorithm graph and SQL. This mismatch makes SQL an awkward choice for defining workflows or decision-making processes in "actions on data" applications.
- Readability issues with conditional logic: Adding complex conditional logic, such as CASE statements not to mention decision-table-like structures, quickly renders SQL unreadable to those who aren’t SQL specialists. This lack of readability significantly reduces SQL’s accessibility to a wider audience, including domain experts.
- Challenges in debugging and monitoring: Understanding the internal behavior of an algorithm—such as how many events passed through a particular node or route—is difficult with SQL. Debugging and monitoring nested SQL statements often requires significant effort, which limits its practicality in dynamic or iterative development workflows.
- Mixed support for JSON: JSON is the lingua franca of modern data processing, and working with complex JSON objects is often a necessity in streaming and real-time applications. Although Flink SQL supports JSON data, JSON handling still remains far from seamless or "first class." Handling deeply nested or highly dynamic JSON structures in SQL can still feel cumbersome compared to more specialized tools.
- Limited external integrations: Calling external services—such as OpenAPI endpoints or machine learning models—is either awkward or outright impossible in SQL. Yet, these interactions are often critical for building non-trivial algorithms. Many real-world applications rely heavily on external systems that aren’t databases, and SQL provides little support for integrating them seamlessly.