Challenge
Nussknacker is a powerful data analysis tool for defining decision rules. It can process streaming data in real-time. It uses an advanced expression language called Spring Expression Language (SpEL). In this post, I’ll check how easy it is to analyze sentiment on run-time Twitter data using Kafka, Nussknacker, SpEL, one-click deployment, and build-in metrics.

This challenge will be a little bit harder than it might be because recent months are not only a time of changes in Twitter company ownership and structure but also in Twitter’s API. This new, v2 streaming API is still not supported well by many libraries
- https://github.com/Twitter4J/Twitter4J/issues/389
- https://github.com/takke/twitter4j-v2/issues/1
- https://github.com/jcustenborder/kafka-connect-twitter/issues/31
but I’ll give it a try.
Data
In the example, I’ll run an analysis on a random 1% sample stream of all available tweets on Twitter. The first step is to make tweets available on the Kafka topic. To do that, I forked the Kafka twitter connector and rewrote it a bit to make it work with the new Twitter v2 stream API. Effects are available in the twitter-connector directory in nussknacker-twitter-example repository. I published docker image that contains this connector. It is available at: ghcr.io/touk/kafka-connect-twitter:7.2.1.
To use it, the only things that should be done are:
- Create an account on https://developer.twitter.com/, create a project on it, and submit for elevated access to Twitter API
- Create .env file with content
TWITTER_BEARER_TOKEN=”YOUR_PROJECT_BEARER_TOKEN”
- Run docker-compose available in the repository including Kafka, Kafka-connect with Twitter connector, and Nussknacker:
docker-compose up - Add connector using
./put-connector.sh twitter twitter-connector.json
or using AKHQ
Now you should see that tweets are available on Kafka: http://localhost:8085/ui/kafka/tail?topicId=tweets 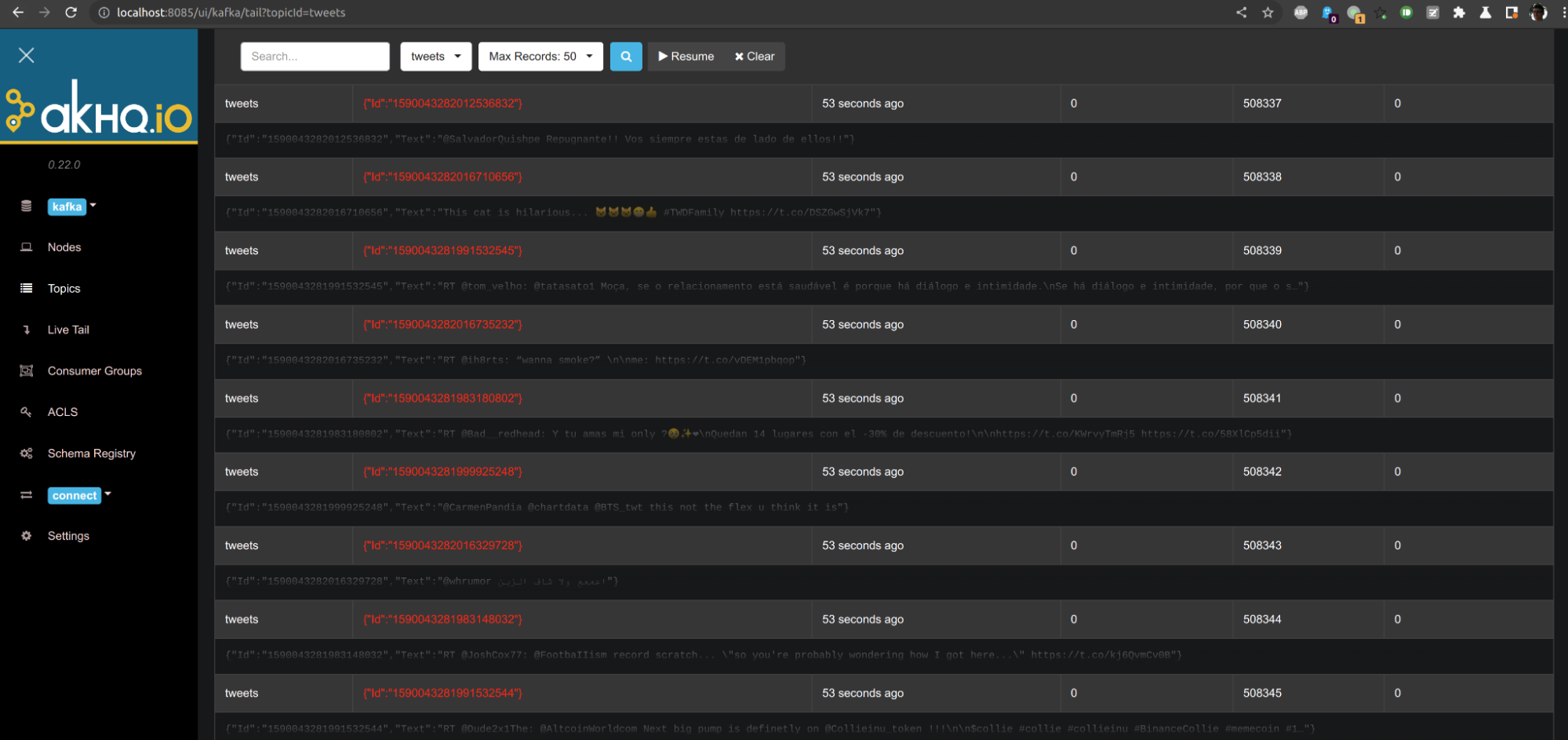
If you want, you can change the connector definition in twitter-connector.json - for example, adding “filter.rule”: “#bitcoin” will cause that instead of a 1% random sample stream, a complete stream of tweets with hashtag #bitcoin will be consumed. You can find more about filtering rules at Twitter API Documentation
Sentiment analysis
For the sake of simplicity, in the example, I’ll use only simple SpEL rules to define what sentiment a given tweet has. The whole scenario looks like this: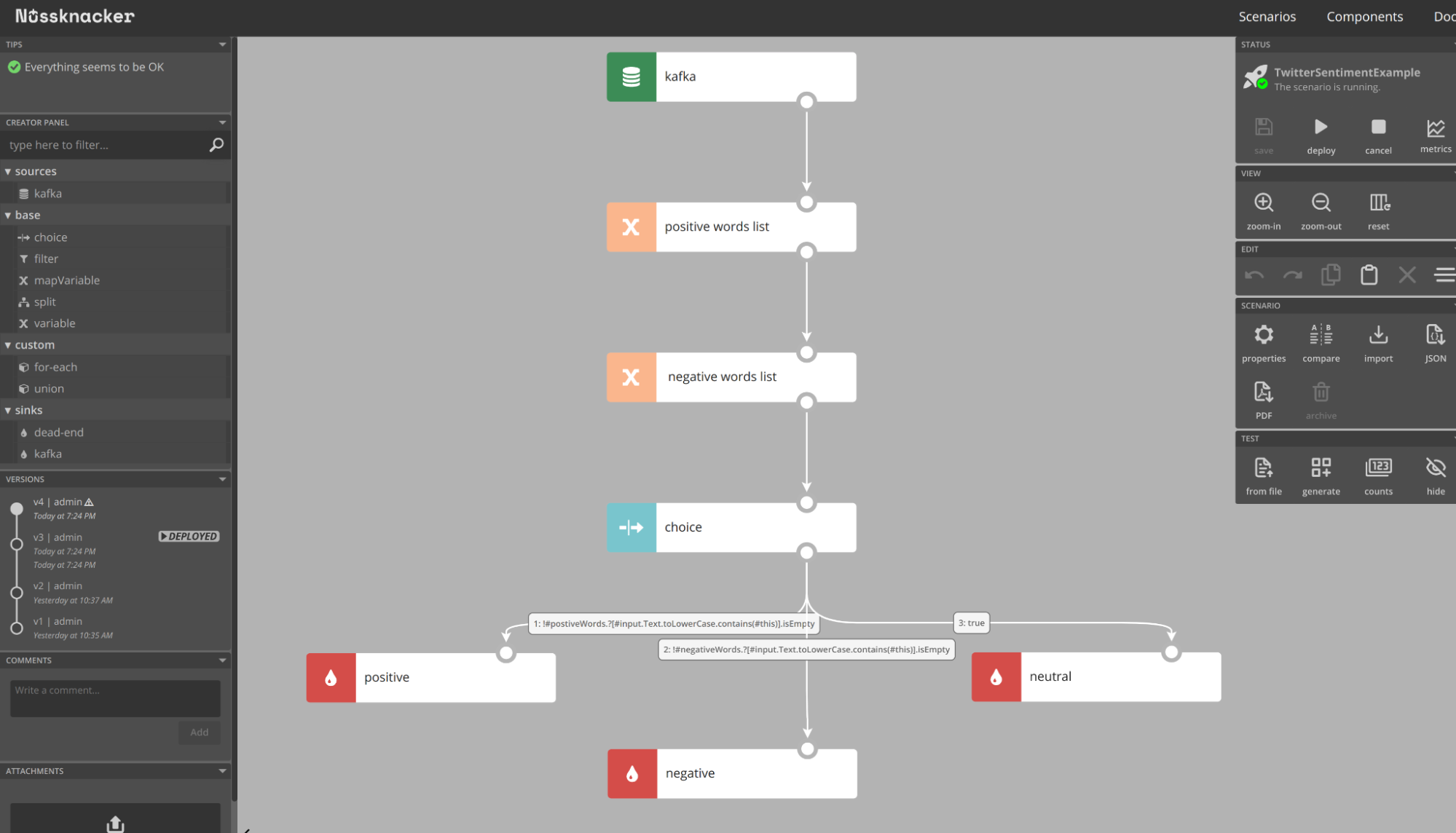
Firstly, it reads tweets from Kafka, after that, it defines two lists of words: with positive words and with negative words. After that, there is the most important part - the choice node with two expressions: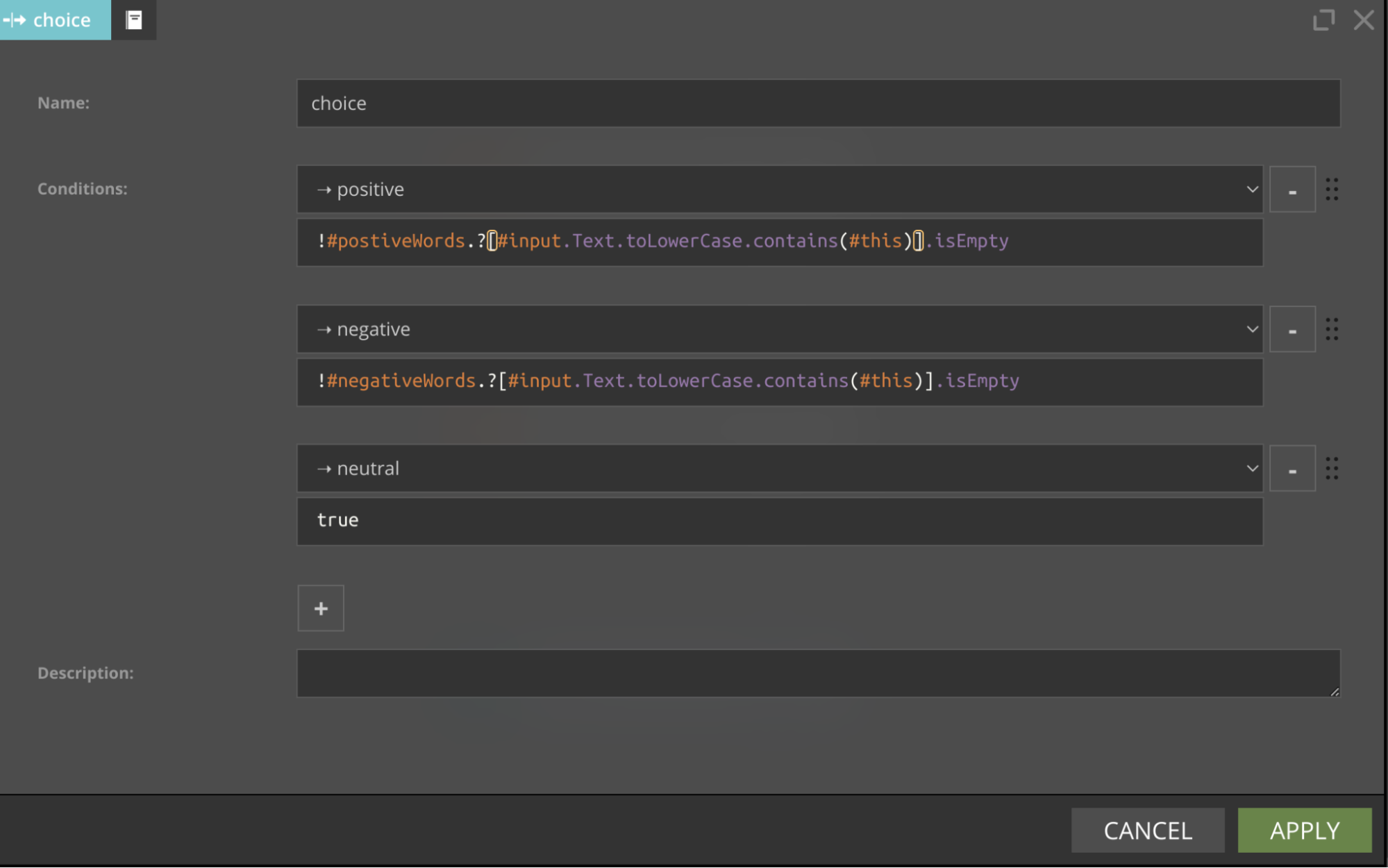
Both expressions look very similar. They check whether a positive (or negative) list of words contains tweet text. They use the SpEL filtering operator (.?) you can read more about it in SpEL Cheat Sheet.
In choice, we decide to which node, the result of processing will be passed. Ending nodes are just dead-ends. We don’t send results anywhere, it will be used only for the presentation of metrics.
The scenario is available in the repository in the TwitterSentimentExample.json file. You can import it on your own. After importing, just press the deploy button. After a while, the scenario will be deployed and you can check the results by clicking the metrics button.
Results
The most important metric is “Events that passed the whole scenario”. The chart is dominated by neutral sentiment. After filtering it out, you will see that some tweets have also either positive or negative sentiment: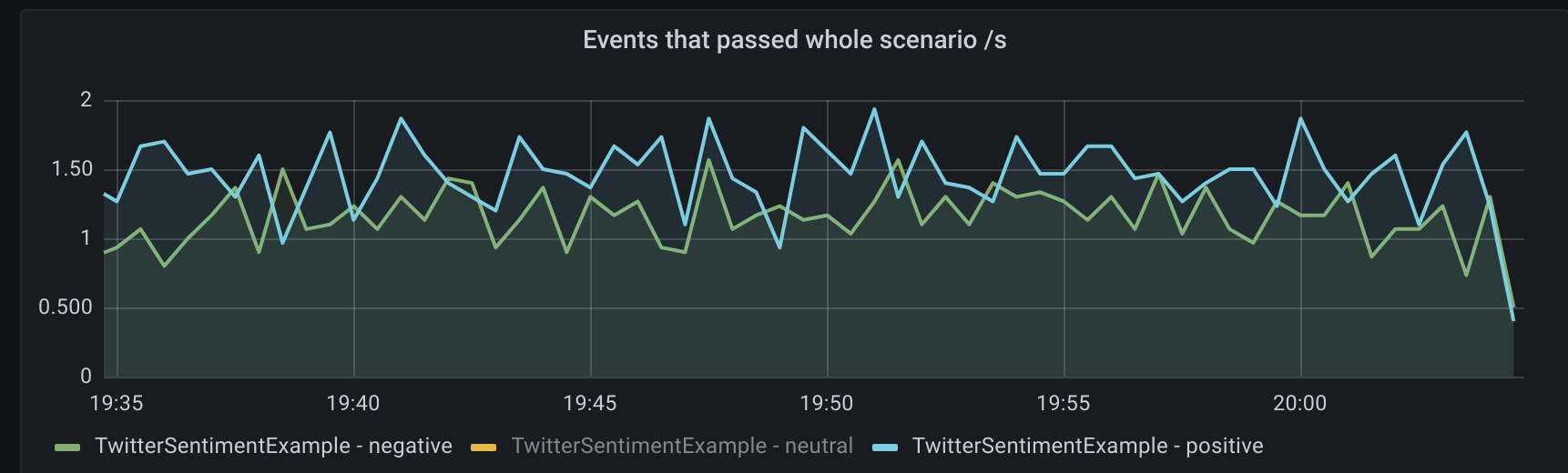
The whole input stream has a throughput of about 40-50 tweets per second: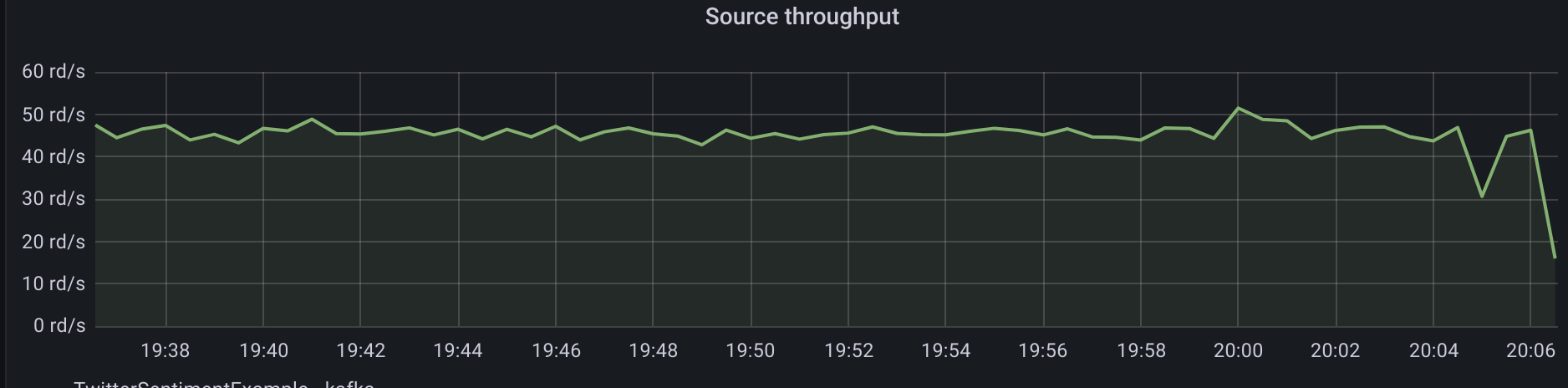
We processed only 1% of tweets so we can assume that at the time of writing this post, the results are:
- ~5000 tweets/second produced by people in general
- ~150 tweets/second are with positive sentiment
- ~100 tweets/second are with negative sentiment
- Rest are with neutral sentiment
Recap
The experiment showed that Kafka tooling by design lets you easily ingest events in virtually any format. The only obstacle was the lack of support for Twitter v2 streaming API in Kafka Twitter connector but it will be improved in the near future. Once data is on topics with defined schemas, they are ready to be used in Nussknacker. What’s more, Nussknacker has a flexible expressions language that allows for defining decision logic. The results of computations are visible in a nice form on metrics charts.
What’s next?
It was only an example of how Nussknacker can be used for sentiment analysis. For more accurate sentiment analysis, NLP (Natural Language Processing) algorithms should be used. Without that, the sentence “I can’t say anything good about this” will be marked as a positive sentence! :-). The good news is that Nussknacker has integration with Machine Learning models in the Nussknacker Enterprise version. You can read more about that in another blog post on ML inference.
I highly encourage you to run this example on your own and experiment with SpEL and other Nussknacker features. Tweet something on #Nussknacker or to @Nussknacker_io and check in metrics what sentiment had your tweet!