With the recent Confluent announcement of the Stream Designer, the company entered a vast field of low-code visual tools aimed at professionals without programming experience.
It may feel like a step forward to the democratisation of data streaming application development and toward the wide adoption of stream processing in general. On the other hand, Nussknacker Designer released its Cloud edition recently.
Let’s see what are key takeaways of the Confluent announcement are and how the aforementioned tools diverge and are similar to each other.

What is a Stream Designer?
From what we can read on Confluent documentation Stream Designer is…
"Confluent Stream Designer is a high-productivity, easy to use, visual designer for building, testing, running, and monitoring data pipelines. With Stream Designer, you build pipelines end-to-end by using a non-programming based, low-code approach, with augmentation by code when you need it."
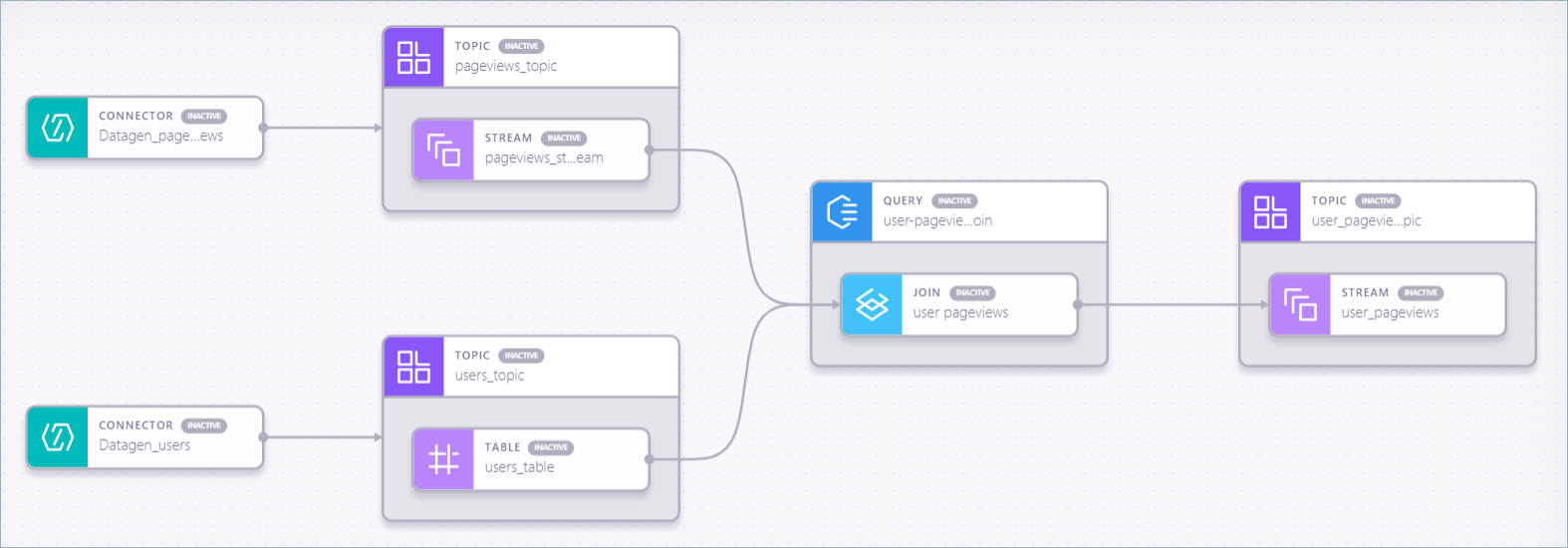
What is a Nussknacker Designer?
Nussknacker is a visual tool to run real-time business logic for event streams combined with analytical data or data served by ML models
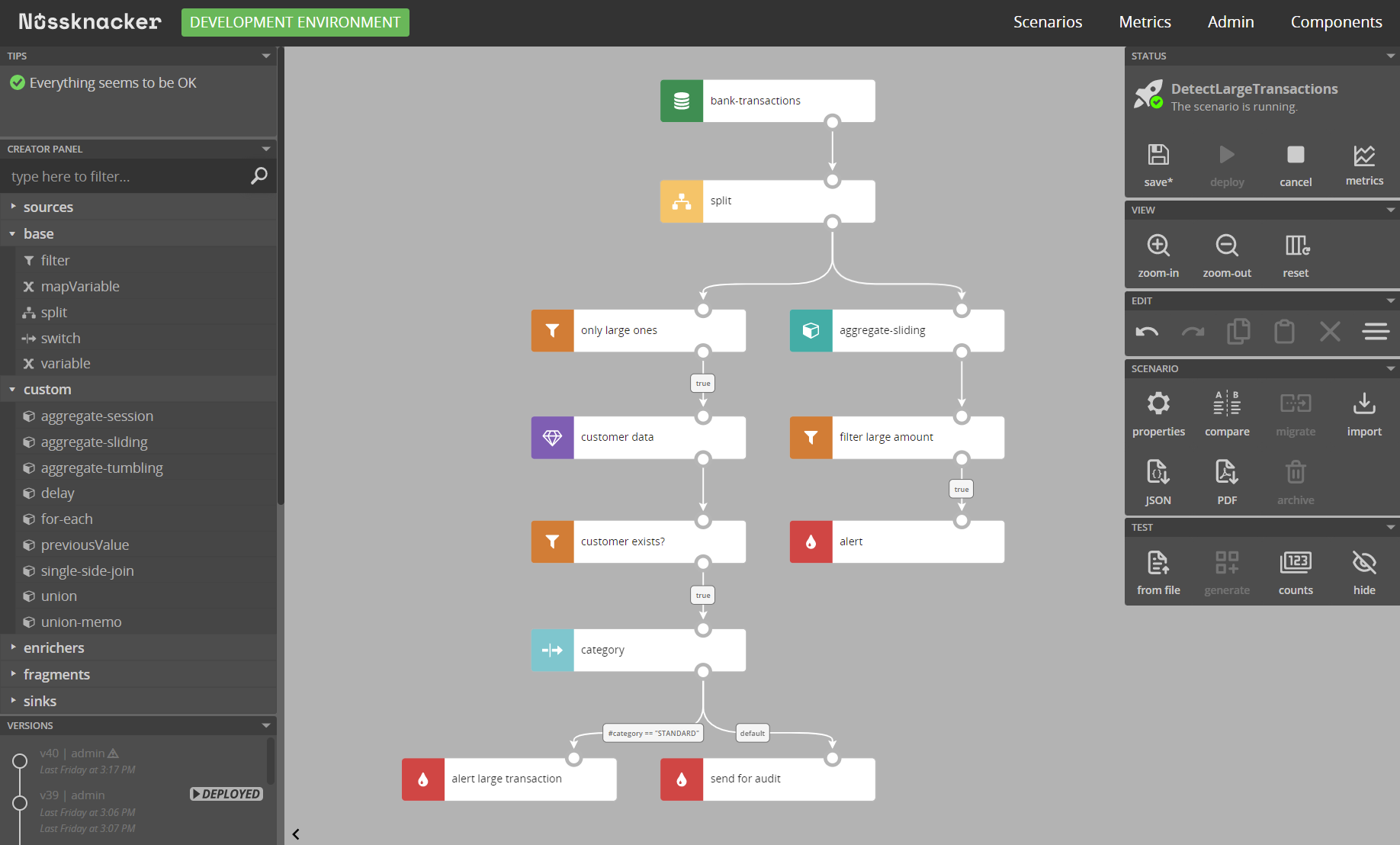
Target users
Confluent Stream Designer is targeting software developers. It makes a promise to boost their productivity by reducing the need to write boilerplate code. In this sense, Stream Designer is very developer-ish.
Nussknacker Designer's main user groups are business experts or analysts. It doesn’t mean that developers are obsolete, their role is to set up a Nussknacker environment according to the requirements provided by the business.
Target purpose
Stream Designer allows the creation of data pipelines - it's a general term meaning a set of steps that moves data from one system to another.
Nussknacker Designer allows the creation of decision scenarios on top of the data streams. Decision scenarios are pieces of business logic that require domain knowledge and may change rapidly - or at least are not steady.
Infrastructure
The biggest advantage of Stream Designer is that it gives a unified platform to work with data pipelines on the Cloud. No additional infrastructure is required, the whole platform can be set up without the need to spin up a server. Nussknacker users can both deploy it on-premise and process streams for any external Kafka server as well as there is a Nussknacker Cloud providing an easy way to get Nussknacker without separate servers.
Runtime/Deployment
Stream Designer gives a unified end-to-end view inside the Confluent Cloud Platform. Visual representation of pipelines is interchangeably translated into a set of ksql queries and then run on the ksqlDB cluster.
Under the hood Nussknacker decision scenarios are interpreted on JVM clusters running Flink or k8s-based Lite engine.
Connectors
Confluent offers a variety of connectors that can be used to ingest data from external systems. It is done with the help of the Kafka Connects underneath. For Nussknacker Kafka is the primary source of data thus the same can be achieved also with help of Kafka Connect but deployed on a separate infrastructure.
Data enrichment
Enriching your data is crucial for building valuable systems on data streams. In Stream Designer this part is done mainly by joining different streams with the help of connectors. Nussknacker Designer on top of that also adds the ability to enrich your data with HTTP calls, SQL queries, or invoking external ML models with stream events as input.
Testability
Nussknacker provides extended testing features for scenario unit testing. One can provide a scenario with sample data to see how each test case behaves. In the Stream Designer case, users can see live samples of data to dive deep into what data looks like.
Observability
Both tools provide similar capabilities in terms of monitoring. Users can see how many events passed a specific node and monitor the throughput.
Code completion
What is the strong advantage of Nussknacker Designer, for sure it's code completion. Based on the schema provided for the topic users are hinted with event fields and their data types. At this point, there is no similar functionality in Stream Designer.
Validation
Another useful feature of Nussknacker is its validation capability. Invalid expressions are marked during the designing of a scenario and users can fix them just in time. For Stream Designer many errors come up after pipeline deployment and thus need to be fixed afterward.
Stream Designer vs Nussknacker
| Feature | Stream Designer | Nussknacker Designer |
| Target users | Developers | Business users / Analysts / SME |
| Target purpose | Data pipelines | Decision scenarios on real-time data |
| Features | ||
| Runtime/Deployment | Executed ksqldb on Confluent Cloud | Executed on separate JVM - Flink cluster or k8s based Lite engine |
| Infrastructure | Confluent Cloud | Nusskacker Cloud / On-premise |
| Connectors | Variety of connectors for external services | Kafka or HTTP as main input source |
| Data enrichment | Stream joins with external services | Stream joins with external services + OpenAPI + SQL + ML |
| UI/UX | ||
| UI | Collaborative, no data pipelines savepoints | Single user at a time, advanced back in time scenario history |
| Testability | Users can peek at their data streams to see what data is inside | Each scenario gives the ability to unit test the flow |
| Observability | Embedded metrics | Integrated Grafana metrics panel, each node counts |
| Code completion | No completion at UI level | Full completion for data streams |
| Validation | User errors come up after deployment eg. ksqldb conditions in filter | Tries to eliminate users mistake with validation |
| Additional | ||
| Documentation and examples | Broad documentation and examples | Broad documentation and examples |
| Complexity | Includes technical complexities | Tries to limit technical complexities |
| Logic separation | Data stream is only building block | Two level: scenario and fragment (part of common logic) |
Democratising stream processing via low-code
To sum up, it looks as if there’s an emerging market of some visual low-code tools that are designated to help people enter the streaming world with ease. Both Stream Designer and Nussknacker Designer take similar, visual tool approaches to facilitate working with data streams. However, they diverge when it comes to target user groups. What’s most important is that both make data stream processing more ubiquitous and democratised.