It’s a data streaming world
Do the terms "stream processing" or "event-stream" sound familiar to you? We guess so, it's 2022 and we've already got used to these concepts. But it wasn't always the case. When the article entitled "It's a streaming world"[1] first appeared in 2009, the landscape was quite different.
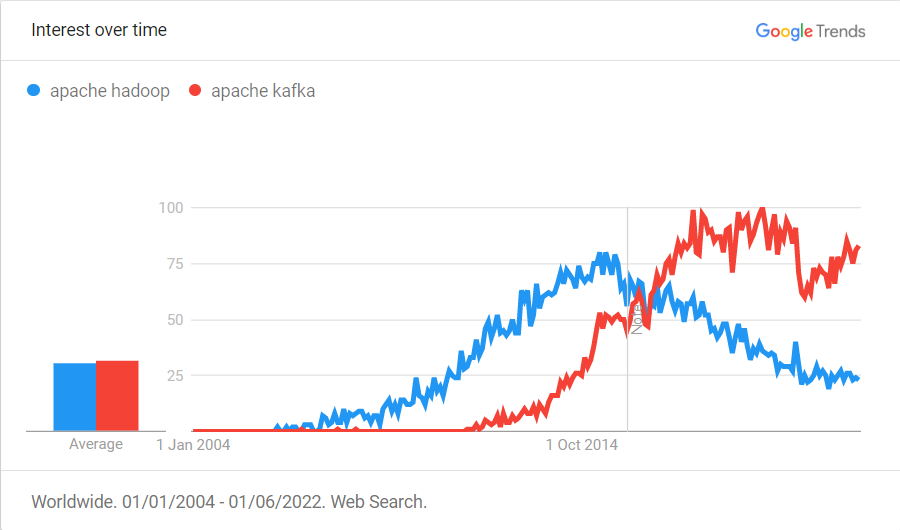
We were just starting to deal with the huge amounts of data that we generated. The MapReduce model with Hadoop as a flagship implementation was gaining popularity. It could scale-out, it could process massive amounts of data, but it wasn't a streaming architecture yet. It was batch processing at its heart. In order to achieve lower latencies, the batch size was decreased, thus micro-batches. But still, the input and output had to hit the disk in between each batch. The overhead of loading intermediate results (think: the state!) into memory on each micro-batch startup was the bottleneck that prevented further improvements in terms of latency.
So what features do we expect streaming architecture to have? Let's summarise it with these four:
- real-time (low-latency)
- high volume
- stateful computations
- highly available
These features make sense together only. Drop one or two of the requirements and you can implement the system as a side project. Achieving all of these features simultaneously is a hard task.
We believe this task has already been solved with Kafka and Flink as its base. Kafka is the backbone of stream processing and Flink - the horsepower.
Kafka. The backbone of stream processing
The 2005 paper "The 8 requirements of real-time stream processing"[2] laid out the rules a stream processing system needs to follow. The first rule, namely "Keep the data moving" is our favorite. Surely persisting data is a must-have, but it's unprecedented to think about it as a "side effect" and not the final goal per se. The fewer layers, buffers, and IO operations our data needs to cross, the better for us. We believe that this is the bottom line approach taken by the Kafka developers.
Kafka’s story begins around 2010 at LinkedIn. Apparently the amount of data produced daily forced the team to build an in-house solution. Offline batch systems were capable of processing high volumes but were not designed for real-time use.
Wait, but we already had message queues at that time, didn't we? Think RabbitMQ, ActiveMQ with its scalability and delivery guarantees. Message queues are versatile "one size fits all" solutions with a multitude of switches and use cases, but it becomes overkill when confronted with a high volume of data.
You might think the Kafka team had to introduce a bunch of fancy algorithms in order to achieve that level of performance. Actually, it's the opposite. They gave up a few of the fancy use cases that message queues offered to be able to optimize more the core functionality. (Don't get me wrong, we don't claim there are no technical advances, but we believe the crucial decision was to give up some functionality and do others better).
Luckily for us, Kafka was open-sourced in 2011 via the Apache Foundation and became the backbone of a stream processing architecture.
Flink. One streaming platform to rule them all
The origins of Apache Flink can be traced back to around the same time when Kafka was born. It all started at the Technical University of Berlin. Initially developed by a collective of research institutes became an Apache Incubator project in 2014. Some specialists were quite surprised to see Flink becoming one of the Apache Top-Level Projects later that year [3].
Flink was initially compared with the king of the era - Apache Spark, but it quickly became clear that it was a different beast. First of all, Flink was designed from the bottom up as a streaming platform. This way it was possible to achieve consistently low latency. Flink’s engine has a built-in auto-optimization feature, as well as using a pluggable state backend (like the ultra-fast RocksDB engine) helps reduce job latency. Also, Flink’s UI monitoring view provides an easy way to dig into a job's data flow, observe the backpressure on individual steps or even show flame graphs showing the CPU consumption of your code.
What's interesting is that you can still use Flink for batch processing as well. When you think about it, a batch of data doesn't differ too much from a stream - except, it has an end. It turned out it's more feasible to use a streaming platform for batch processing than the other way around (what Spark did).
Gap between streaming technology and business
Once we have the technology at hand, it’s time to look at how we can efficiently leverage the technology for business needs.
In the world of relational databases, SQL is the bridge that fills the gap between the technology and the business. There are similar efforts in extending SQL for the streaming world. It is very promising, but its main drawback is that in order to use it, you need to have all of your data in a homogenous environment. It might be a problem, especially for companies that are in the early adoption of the streaming approach.
We took another approach that allows us to integrate any existing technology with stream processing.

Meet Nussknacker. Low-code in stream processing
Nussknacker is a visual low-code tool designed for stream processing. It provides as many as possible ready to use components, with the possibility to plug in custom-made enhancements for a specific business need. In the following sections, we described the differences (and advantages) of using Nussknacker over traditional code-centric (or SQL-based) approaches to defining stream processing scenarios.
The Toolbox
The most used part of any visual application is a toolbox. In Nussknacker it brings the users easy access to components separated into clear groups:
- sources - the source of your data stream, typically a Kafka topic
- base - for typical stream processing functions: filter, switch, split, join etc.
- custom - custom components, aggregates, delays etc.
- enrichers - row-grained data enrichments from external sources (JDBC, OpenAPI)
- sinks - the place for your scenario’s results, typically a Kafka topic or database table.
The idea here is to “protect” the end-users from the detailed configuration of these toolbox elements. They can just take the “kafka-avro” component, select the topic and start to make some decision logic based on incoming data:
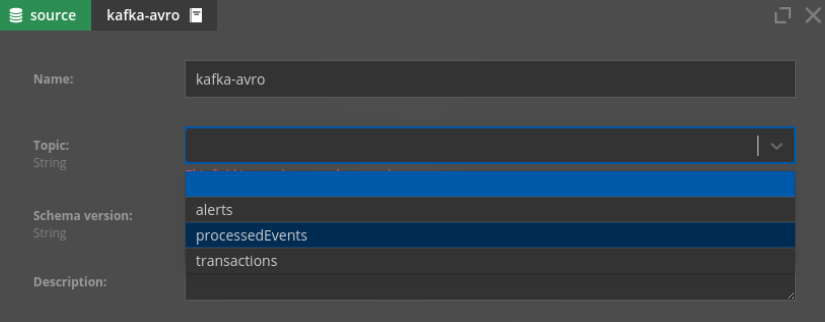
Same for enrichers - you can choose from one of the provided definitions, drag’n’drop to the diagram, and then just perform minimum configuration (join key):
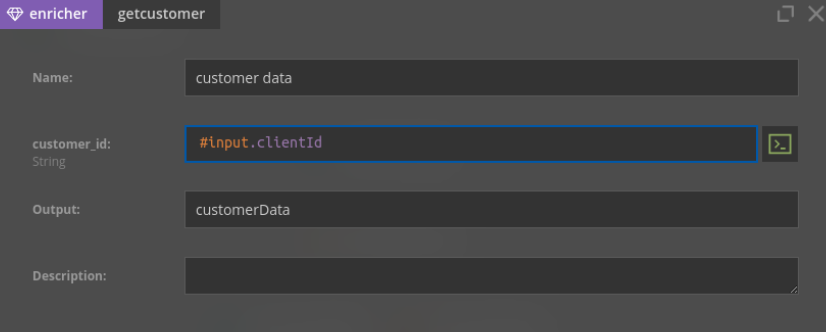
In contrast, in Flink SQL you define source/sink with CREATE TABLE DDL statement, extended by a special WITH clause describing technical details, like Kafka broker / JDBC url, data format, timestamp / watermark settings etc. This requires a bit of developer / devops knowledge, which in our vision should be out of scope for the end user describing the scenario. In Nussknacker approach, we assume that some “technical” person / team prepared the necessary definitions (called “the model”) that could be used by a “non-technical” person by drag’n’drop-ing the components to the diagram.
Type orientation
Another aspect, highly related to the above, is type orientation. In Nussknacker we rely on type safe schemas, like Avro/Json on Kafka topics, DDL of SQL tables or Open API definitions in REST enrichers. This allows us to check type correctness/validation and perform code completion at every moment during editing the diagram:
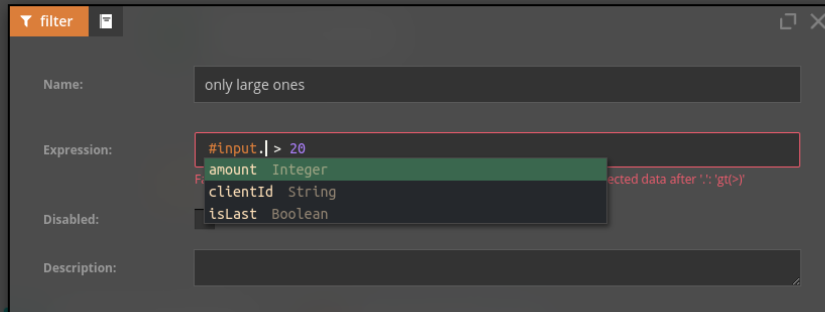
It can be annoying at first glance, but eliminates most of the bugs happening when using a code-centric approach: typos, using wrong data types, etc. These usually appear at runtime - during streaming process execution - in Nussknacker those can be found much earlier, before a scenario is deployed on the execution environment.
Observability
One of the key aspects when building stream processing scenarios is observability, meaning that you can quickly monitor your process behavior. In Nussknacker, we developed a few ways of being up to date with your data processing:
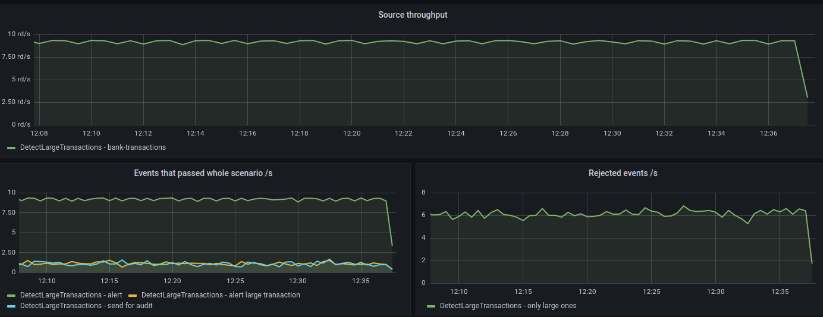
→ Metrics view - from any scenario, you can access the “Metrics” view, which takes you to a predefined Grafana dashboard, showing live view basic metrics like:
-
- source throughput
- events rejected on filters
- enricher errors and response times
- events that finished on sinks
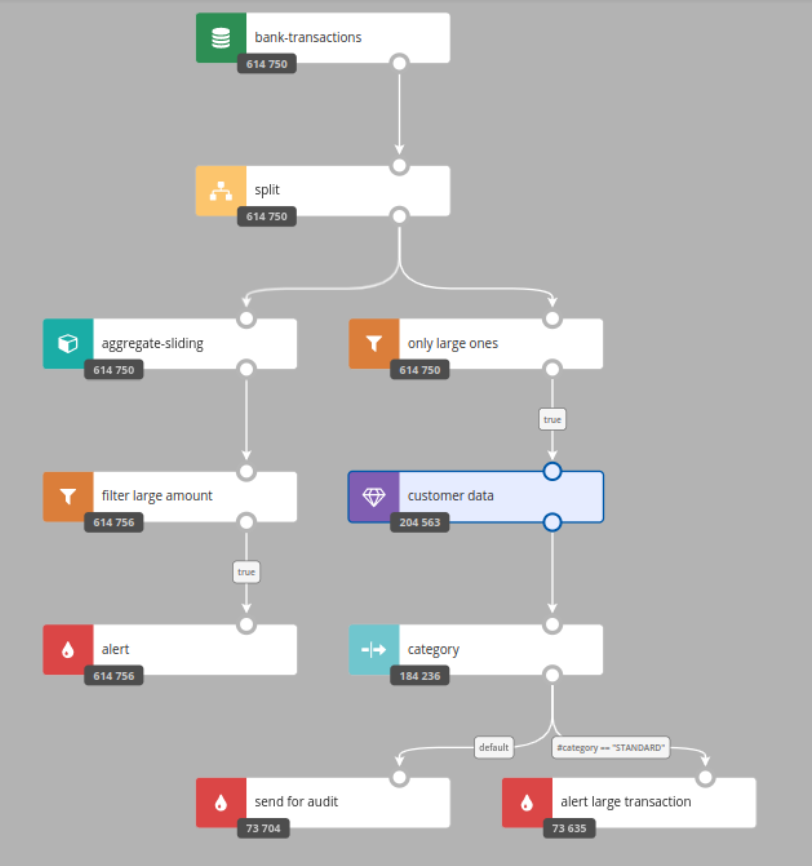
→ Counts - from any scenario, you can click the “Counts” button which shows you counters on any branch / node of your scenario (fed by InfluxDB data):
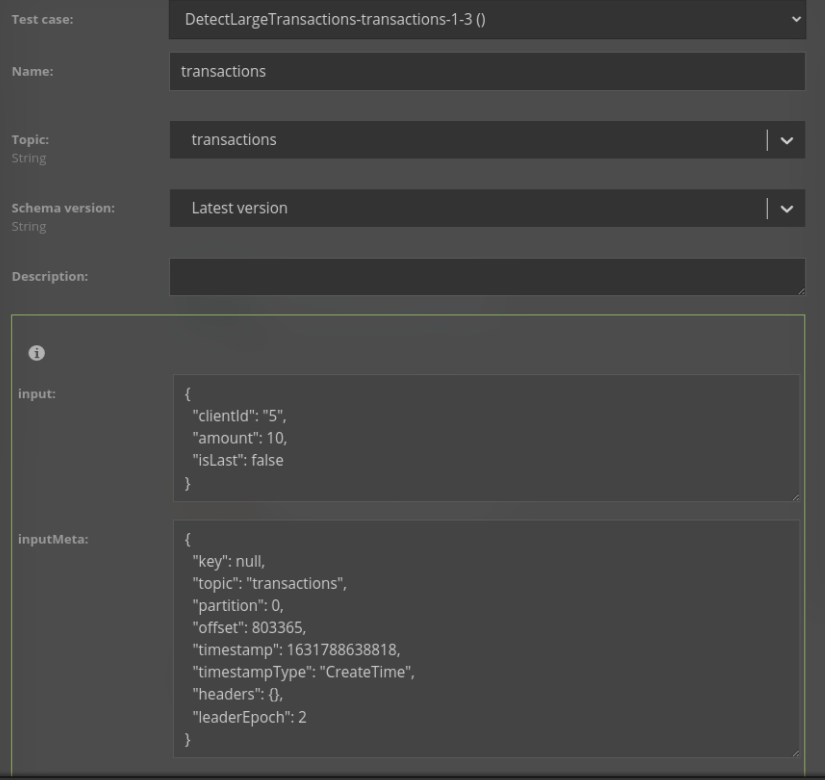
→ Testing - from any scenario, you can click the “From file” button to execute the scenario in an isolated environment with input data provided from a static file, or generated randomly, using the schema of a source component. After running, you can access a detailed view of the state on each step of the scenario:
→ Data view - every Nussknacker deployment contains an instance of AKHQ component, which lets you deep-dive into your Kafka cluster - view and compose messages, observe consumer lags and manage topics schemas.
Real-time actions on data
The article guided you through stream processing history, describing various milestones, like introducing Kafka and Flink, which changed some of the paradigms of stream processing. But the development process looks still the same - the business defines the requirements, and the developers implement these by writing stream processing code.
We believe that it will evolve into using more low-code tools, which shorten the distance between the data and business users. One such tool is Nussknacker, want to try it yourself?
Bibliography
[1] E. D. Valle, S. Ceri, F. v. Harmelen and D. Fensel, "It's a Streaming World! Reasoning upon Rapidly Changing Information," in IEEE Intelligent Systems, vol. 24, no. 6, pp. 83-89, Nov.-Dec. 2009, doi: 10.1109/MIS.2009.125.
[2] Stonebraker, Michael, Uǧur Çetintemel, and Stan Zdonik. "The 8 requirements of real-time stream processing." ACM Sigmod Record 34.4 (2005): 42-47.
[3] Wheatley, Mike. (February 9 2015). "Will the mysterious Apache Flink find a sweet spot in the enterprise?", https://siliconangle.com, Accessed 29 April 2022, https://siliconangle.com/2015/02/09/will-the-mysterious-apache-flink-find-its-sweet-spot-in-the-enterprise/