The secret ingredients of successful low-code real-time data tools
Real-time actions-on-data algorithms are rarely trivial enough to be created with no-code: just drag & drop. However, the “traditional” low-code approach, where the functionality not implementable in a no-code fashion has to be created with regular code (Python, Groovy, Java, etc) may be not a way out for domain experts.
An example of a real-time actions-on-data app is the deployment of ML models on data streams. As Chip Huyen stated in her blog:
"My dream is that data scientists should have access to an ML platform that enables them to leverage streaming without having to worry about its underlying complexities. This platform needs to provide a high-enough level of abstraction for things to just work while being flexible enough for data scientists to customise their workflows."
In the streaming world, the reason why domain experts find themselves forced to go into deep technical details of Kafka, Flink, Spark, REST, etc is that while many platforms are quite successful in abstracting Kafka, Flink, Spark, etc, they are just simple visual overlays on the (streaming) SQL and do not allow for much more. This is by far not enough to author a serious actions-on-data algorithm.
Many platforms miss one or more of the critical features needed for successful low-code actions-on-data platforms, making it almost impossible for domain experts to create anything but trivial. On the list of missed-out features, I have the ability to use no-boilerplate programming constructs when transforming data and creating conditions, access to external data and services, extendability, support for ML models inference and IDE-like development features. Only when all these features are present, one can author a fully-fledged processing algorithm.
What is special about (some of the) actions-on-data apps?
There is a subcategory of apps which we could call real-time actions-on-data apps - examples include fraud detection, IIoT monitoring and preventive maintenance, Next Best Action, computing ML features, and serving ML models. The defining characteristic of these applications is that they get typically real-time input data and take (deliver) some kind of result (decision). Examples would be deciding whether something is a fraud, whether there is emergency maintenance required for a machine or which products or services to recommend to a customer in the next step of the customer’s interaction with the company’s website.
The applications mentioned above have a set of distinctive features which make them stand out from millions of “regular” real-time applications - they require a lot of domain-specific knowledge, an ability to experiment with the decision algorithms and extremely short development cycles. In some domains like fraud detection the target is continually moving - you have to keep on adapting the algorithm endlessly.
For this reason, the core algorithm part of such applications should ideally be authored by domain experts - they have expertise and fun from building and continually improving their algorithms. If so, the development of the data processing logic in such applications would be a natural candidate for no-code / low-code. Unfortunately, this is often not possible because of the shortcomings of the tools used by domain experts.

The often missed features of the actions-on-data tools.
Ability to use programming constructs which are more intuitive and less verbose than those found in regular programming languages. We all intuitively know that it is not possible to build non-trivial applications using no-code frameworks. For this reason, there is a low-code category of tools - when the no-code approach hits the limits, one can add regular code (Python, Java, Groovy, etc) to augment no-code. As already mentioned, the problem with low-code platforms defined like this is that these are still development tools for professional developers, not for domain experts - for many from the latter group even simple code additions with all the boilerplate required by these languages may be too much. Yet some form of programming would be handy to specify two essential aspects of the algorithm:
- data transformations
- conditions - these are needed to decide when the current algorithm step can be finished, what is the next step of the algorithm and what conditions need to be met for the data transformations.
An alternative approach is needed where domain experts could use programming constructs which do not require boilerplate of Java, Python and can be used to “produce” values (conditions and data transformations). The obvious candidate for such “programming constructs” are expression languages: millions of non-professional developers use expressions in spreadsheets - all formulas that we enter in Excel or Google Spreadsheets are expressions.
The success of spreadsheets is proof that non-professionals are not afraid of coding - just the constructs they use must be easier to learn than regular programming languages. To start, expressions do not require the boilerplate and “environment” of the regular programming languages (like import, include, esoteric keywords in declarations, classes, etc). Expressions can range from very simple ones like =2 + 3 and =isNumber(24) to pretty complex ones - all this without any boilerplate. Expressions always produce a value: string, number, boolean, etc - this is exactly what is needed to express data transformation or a condition. The fit is perfect.
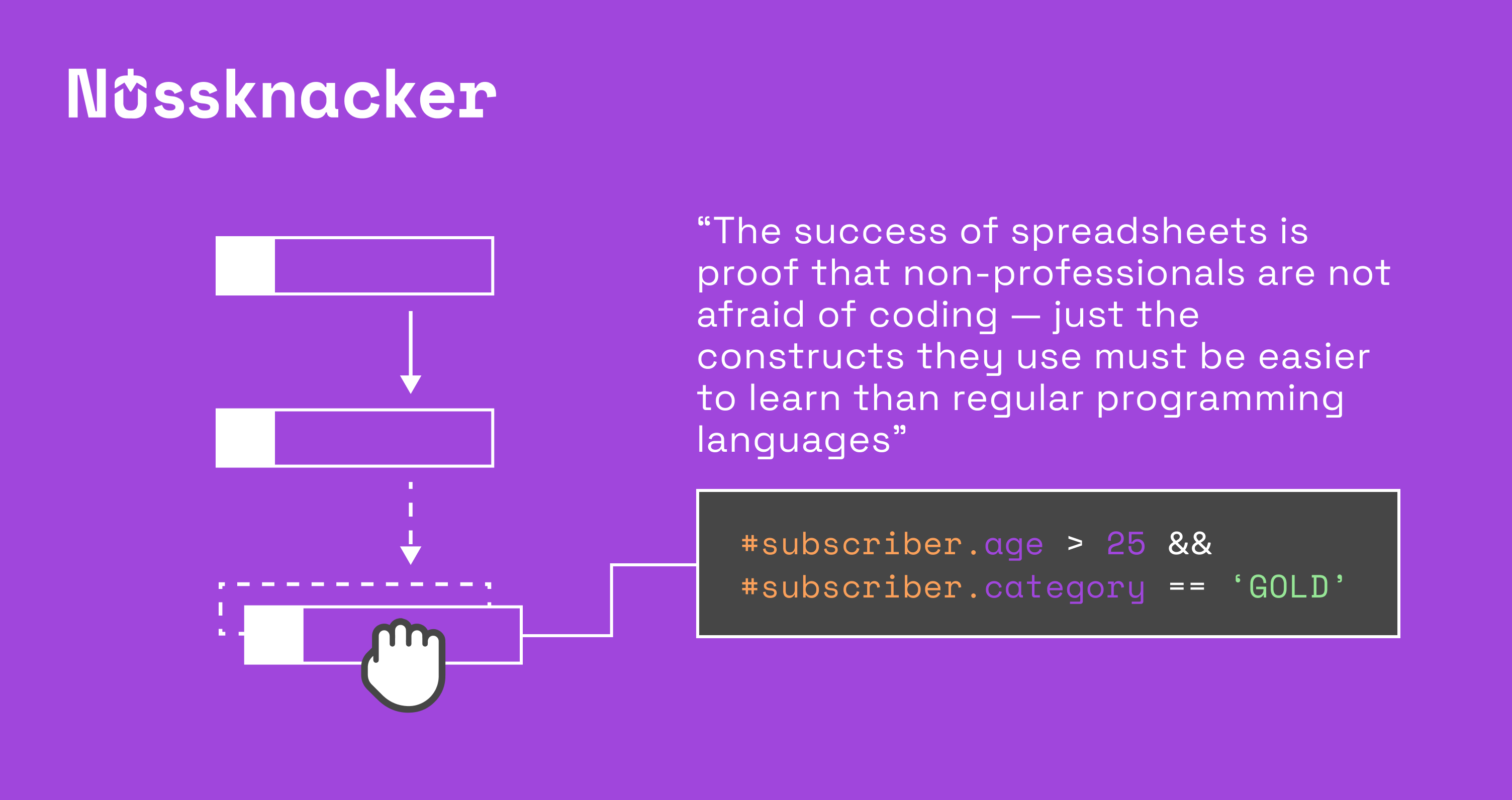
Enrichments. The use of expressions as a “programming construct” opens a whole set of new possibilities typically missing in no-code and available only through “regular code” - namely enrichments. With expression language, one can easily transform data to obtain input values as required by the enrichment component and similarly transform the data received from the enrichment to adjust them to the needs of our algorithm. The reason we need enrichments is that rarely does the data at hand contain all the data required for the algorithm - we need to enrich it with data coming from external sources. An example could be getting customer details based on the customer id. There can be different types of enrichers - database look up’s and calls to external services like REST API - the platform should support both.
Support for different architectural styles. The tool should allow designing algorithms for different architectural styles Ideally when switching between architecture styles (like from request-response to batch) one should not need to change anything other than input and output specification - at the very end, it is irrelevant whether input data come from the on-line request, data stream or file. The tool should abstract out the differences and let the domain expert focus on just the data and the algorithm to be applied. This is of particular importance in ML context, where the same algorithm needs to run in multiple architectural settings: batch for training, real-time for models serving. As a result, the requirement is that the following architectural styles should be supported in a uniform way:
- Request-response
- Data stream
- Batch
Extendability. All tools have limited functionality and this is even more so for low-code tools. Being able to extend the tool makes it possible to overcome tool limitations. Moreover, if the tool is extendable, it is possible to add new functionality without the (potentially expensive and slow) involvement of the tool vendor. Two types of extensions should be possible: user-defined functions (UDFs) and custom processors. UDFs are just functions which can be used in expressions; an esoteric statistical function which did not make its way to the set of functions supported by the tool could be an example. Custom processors on the other hand are higher-level building blocks - they need to deeply integrate them with the platform and most likely their development is more involving than in the case of UDFs.
Syntax assistance. Using expression language as a configuration language means that features we know from IDEs (Integrated Development Environments) and Excel + Google Spreadsheets are needed to assist those who write expressions and prevent them from making errors. The minimum set of required features includes syntax validation and hints. There is nothing more annoying than discovering that there are some syntactical errors only after the application is deployed. Specifying data transformations and inputs to enrichers or ML models by means of yaml configuration files (yes, there are such platforms) should be unheard of.
ML models inference. Executing an ML model is often part of the decision algorithm. This could be achieved in several ways - by calling a REST service or extending tool functionality. The first approach may be too slow in high volume environments, the latter not so easy and slow to deliver for organisations with limited IT development staff. Ideally, the tool should deliver ML inference out of the box.
On a side note - similarly, as in the enrichments case, expressions will make it easy to transform the data at hand to the input values required by the ML model and create conditional logic defining which model under what conditions to call.
Conclusion
The push of low-code application platforms, citizen automation and development platforms and similar is unstoppable - the market will grow 20% yearly according to this Gartner report. The emergence of actions on data category of low-code tools will transform the way organizations build real-time actions-on-data applications which require deep domain knowledge. More and more of these applications (or just their components) will be authored by domain experts, rather than armies of developers. As the result there is a potential for a revolution similar to the one caused by the emergence of spreadsheets - the key question is which tool will come up with the best mix of features. We at Nussknacker believe that with our vision of what is needed, we are far, far ahead of all the competition.
Recommended reading
- Chip Huyen, Introduction to streaming for data scientists
- Chip Huyen, The self serve feature platforms architectures and APIs
- Gartner Forecasts Worldwide Low-Code Development Technologies Market to Grow 20% in 2023
- Stream Designer and Nussknacker Designer comparison
- ML models inference. Non-trivial processing algorithms built and deployed in an easy way