In this article, we’ll show you what’s the case for using Apache Ignite in a Nussknacker environment, which open-source components you can use in that case, and what to pay attention to in Ignite cluster configuration and monitoring. This is based on experience from one of our latest Nussknacker deployments.
TL;DR
You can check our quickstart repository showing a simple scenario of using Ignite with Nussknacker.
The case for a fast distributed database in streaming
We had a few distinct use cases where a need for some kind of distributed database was involved: event level data enrichment, on-line access to aggregate values and analytical queries on historical aggregates. These use cases generated very different load/operational/configuration patterns, which are discussed below.
Event level data enrichment
Let’s discuss a diagram with typical Nussknacker deployment:
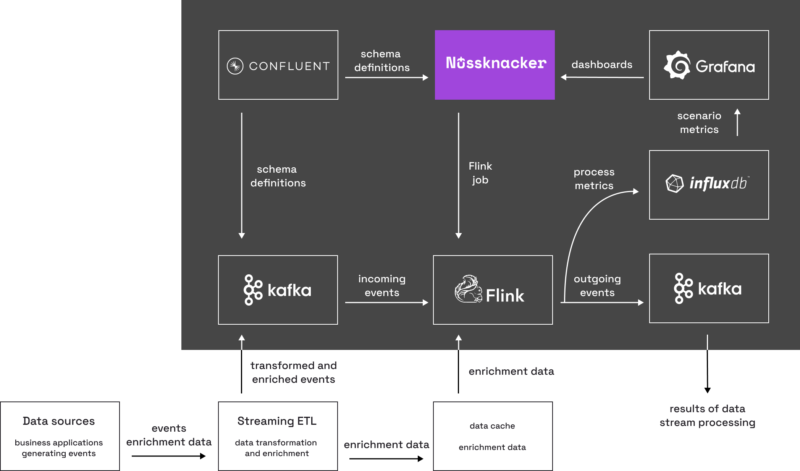
It is a common requirement to enrich incoming event records. For example, we often have some customer id (like phone number) in the raw records and many business cases are based on additional customer data: a contract, segment etc. That’s why a data cache allowing fast access by key is a must-have when dealing with a stream of thousands of records per second.
Aggregates persistence
Very often streamed data is used to compute aggregates in time windows; Flink and Nussknacker excel in this. Aggregates for a given key value are constantly updated by the incoming data. In Nussknacker scenarios user wants to perform some actions based on the total value (eg. for the whole day) of the aggregate:
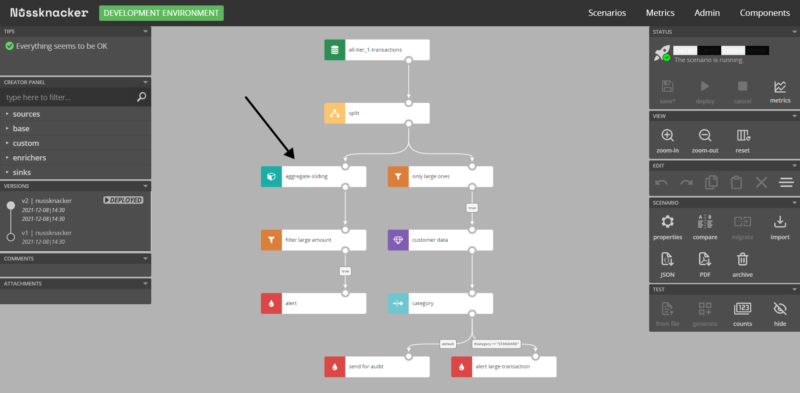
On the other hand: we often need on-line access to the most current aggregate value. The aggregates are internally stored using Flink’s state abstraction, in RocksDB. This is a really good and fast storage, but it’s meant to be locally embedded into your application, so it’s not distributed and lacks an API to easily access data, like REST/SQL. Finally, we need to perform some analytical queries on historical aggregate values (eg. for threshold tuning). The time span for this analysis can reach serious values (example: 30 days back), which ends up with the need to store hundreds of millions of rows with aggregates.
Why Ignite?
We can sum up the above requirements with this list:
- Fast access by key for enrichment (thousands of queries per sec)
- Fast upserts of current aggregate value (hundreds/thousands of upserts per sec)
- Persistence of aggregates to analyze historical data (n-day persistence for millions of records)
Apache Ignite started in an “in-memory data grid” category, but now, with its native persistence feature and SQL interface, it has truly become a distributed database; also advertised as having ”in-memory speed”. We also had some experiences during previous deployments and made some extensive performance tests, which showed that Ignite’s DataStreamer could be a good fit for our massive upsert scenario in aggregate persistence use-case. We also knew about Ignite SQL capabilities, featuring analytical queries, but didn’t have any production experience with it.
Implementation
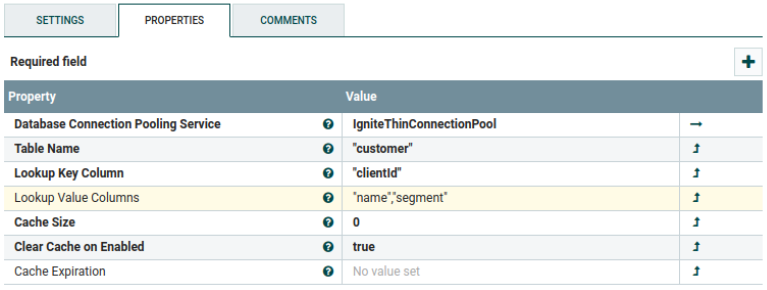
We had two approaches for enrichments in our scenarios. The first one was implemented using Nussknacker enricher abstraction. Since Ignite implements JDBC, we were able to use a standard databaseLookupEnricher and configure it straight from your Nussknacker Designer:
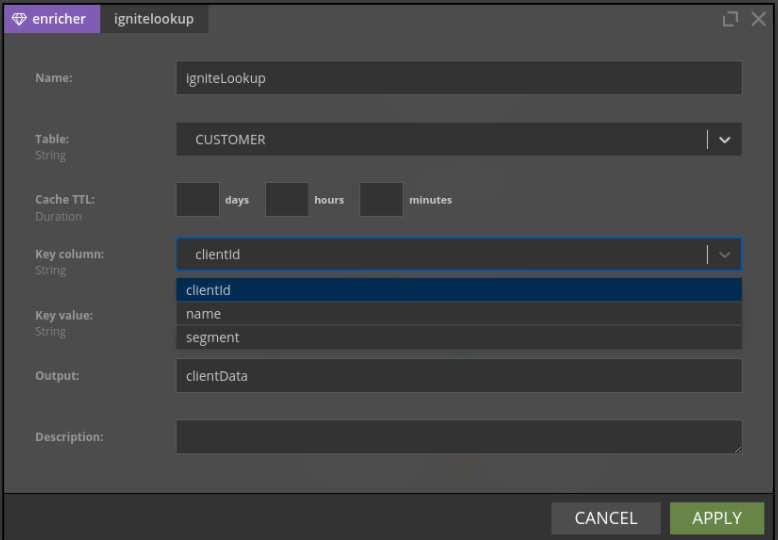
The second approach performed aggregation during the ETL phase, which in our case was based on NiFi. Again, we used a standard NiFi’s LookupRecord processor, just had to provide ignite-core.jar like any other standard JDBC driver.
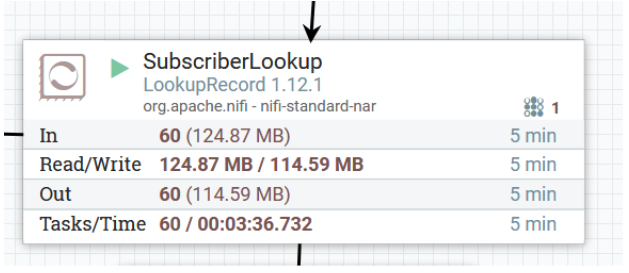
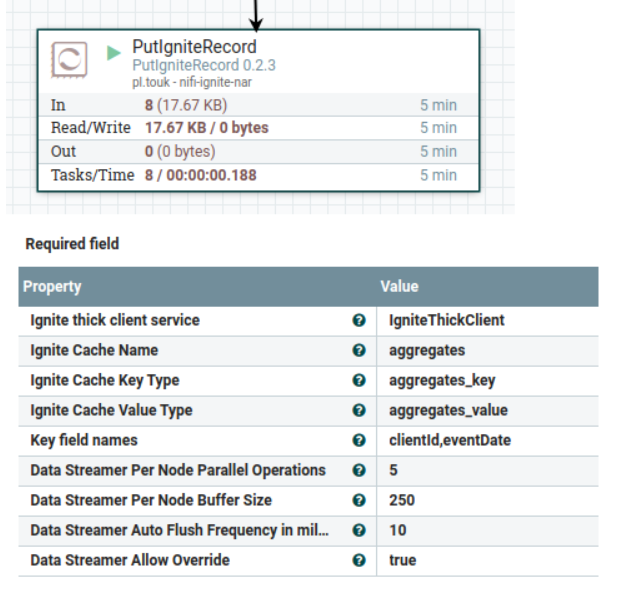
In the aggregate generation case, updates turned out to be a little tricky. Our first idea was to update the actual aggregate value on every record - which meant that the number of updates would be equal to the number of incoming events. Ignite supports SQL upsert (by MERGE INTO syntax), but it can’t be used in batch mode. That’s why we needed to use Ignite Data Streaming API. We had some issues with mixing Data Streaming with SQL worlds (eg. with composite keys). Finally, we ended up developing a custom NiFi processor called PutIgniteRecord - you can find it in our nifi-extensions repo on GitHub.
Problems & solutions
Heap starvation
After setting all the read / write parts in the semi - prod environment, we started to experience periodical heap starvation of our Ignite cluster. The actual JVM memory reached the limit which resulted in OS restarting Ignite processes:
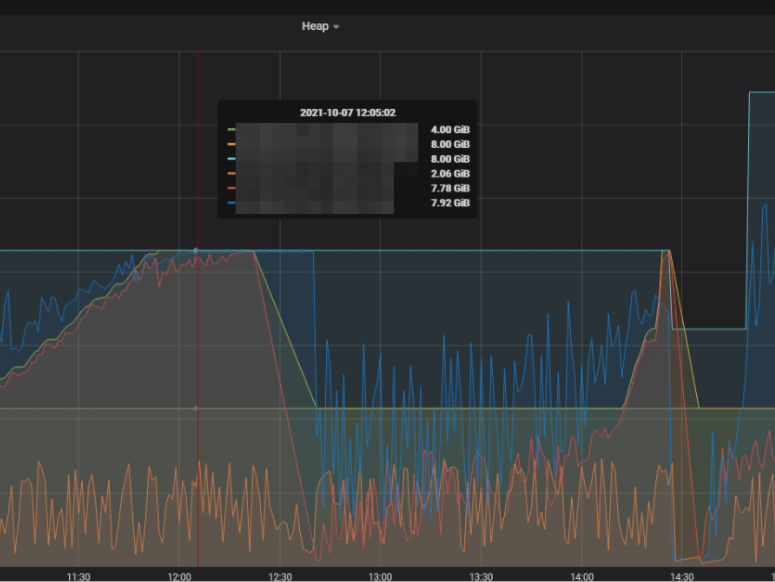
It was especially painful, because Ignite (as it even points in the official documentation) does not like non-graceful shutdowns: it can result in a need to perform some administrative task or even a data loss.
The key point in understanding this behavior is the checkpointing process. During massive updates, Ignite marks “dirty” pages in memory, which means they are selected to persist to disk during the next checkpoint. The client gets “acknowledge“, data is modified in memory, but it’s not persisted to disk yet:
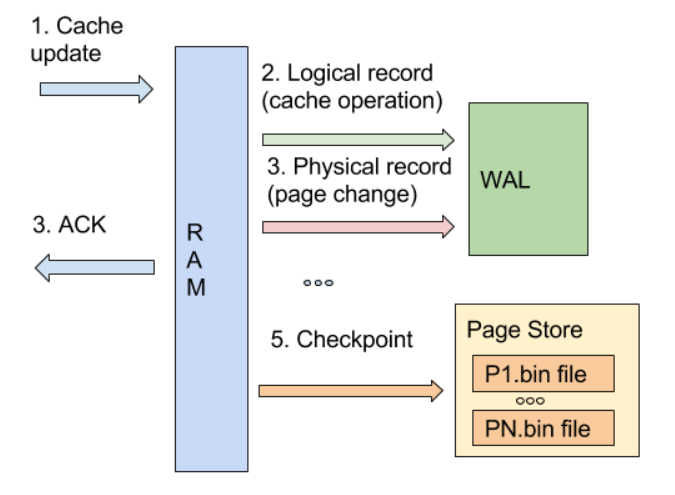
We observed that under a heavy load, our checkpointing times increased rapidly, and decided to take a look at disk performance. Ignite is especially optimized to work on fast SSD or even Intel Optane storage. This wiki page describes more details:
"Slow storage devices cause long-running checkpoints. And if a load is high while a checkpoint is slow, two bad things can happen
- Checkpoint buffer can overflow
- Dirty pages threshold for next checkpoint can be reached during current checkpoint
Since Ignite 2.3, data storage configuration has writeThrottlingEnabled property.
If throttling is triggered, threads that generate dirty pages are slowed with LockSupport.parkNanos(). As a result, a node provides constant operations/sec rate at the speed of storage device instead of initial burst and following long freeze."
So we enabled the writeThrottlingEnabled property, but also made some optimizations on the scenario side. We observed that many events for the same customer id occurred in short windows, one after another. So instead of publishing aggregates on each event, we introduced another 5 minute window, which reduced the stream of aggregates by about 30%. After these changes, the heap usage had stabilized and we no longer observed any Ignite node outage.
Analytical queries
Our first thought was that we’ll be able to use Ignite to make analytical queries on big tables - we had some experience with Clickhouse, which works really well in that case. So we wanted to keep aggregates for eg. 30 days and run queries like “give me top x customers by the amount of calls/transactions for the given day”. But we quickly gave it up with Ignite.
Getting the affinity key to work according to expectations was a major disappointment - we originally spread the data over all our nodes using customer_id as an affinity key, event date being a secondary index. We hoped to gain from parallel processing with such a setup for queries searching through records for the given date. Moreover, this setup would ease our problem with massive updates, as these would be spread over all the nodes. To our surprise, the analytical queries accessing data based on event date were extremely slow; we ended up changing affinity to the event date, speeding up massive selects, and having only one node actively updated during the given day.
We finally decided to run those analytical queries on Flink. We implemented a Flink SQL connector for Ignite, which allowed us to fetch all needed data (by day) and then query by running Flink jobs - which we know how to track. The code for the connector is available on GitHub.
Summary
Here is a short list of thoughts you can take from this article:
- In-memory data grid is important part of streaming architecture
- Apache Ignite is also a persistent distributed database
- Monitor heap size and checkpoint duration of your Ignite cluster
- Use write throttling on both Ignite configuration and your scenarios
- Allocate (more than usual) time to play with different Ignite settings - the interdependencies between subgroups of parameters were not always clear to us and documentation although very deep in some cases lacks good conceptual overviews.
- Use our open-source components: nifi-extensions and flink-connector-ignite
We also prepared a quickstart repository to show how to use Ignite with Nussknacker and let you run a simple example on your workstation.
// Thanks to Zbyszek Małachowski for a solid review of this article