The Data Lakehouse architecture is a solid foundation for modern analytics solutions. It allows users to store data in relatively cheap and scalable storage services such as HDFS or Amazon S3. Stored data can be processed by multiple compute engines thanks to open specifications. This extends the possibilities of applications in business use cases and reduces the risk of vendor lock-in. In the latest release, Nussknacker added support for Flink catalogs. Thanks to this feature, it is possible to add Nussknacker on top of solutions such as Apache Iceberg and use it for various purposes such as data ingestion, transformation, aggregation, enrichment and implementation of business logic based on this data. In the blog post, I'll show how to implement an example business use case by combining Nussknacker and Apache Iceberg.
1. Introduction
2. Example use case
3. Setup preparation
4. Use case implementation
Introduction: Apache Iceberg
First, let me explain what components Apache Iceberg consists of and how it benefits users. The main part of Apache Iceberg is an open metadata specification that describes where a piece of data is, in what schema, and how to read it efficiently. This abstraction is called the table format. This concept was already available in earlier solutions, for example, Apache Hive. However, modern table formats such as Apache Iceberg offer many more benefits than the previous one, such as row-level updates, schema evolution, hidden partitioning, ACID, time travel and many more.
Another important abstraction is a catalog abstraction. The catalog is a service that allows managing multiple tables described in table format. Apache Iceberg table definitions are typically stored in the Apache Hive Metastore, Nessie Catalog or JDBC storage. In 0.14.0, Iceberg also exposed the REST Catalog OpenAPI Specification, which can be implemented by service providers.
The final piece of the puzzle is the catalog connector. The catalog connector allows compute engines to understand how to communicate with catalogs and how to read tables described in table format. Apache Iceberg provides connectors for Apache Flink, Apache Spark and Apache Hive but there are also connectors maintained by other projects, for example, Trino. There are higher-level applications that are built on top of compute engines. One of these is Nussknacker or Flink SQL.
The architecture that combines these concepts is the Data Lakehouse. You can find other implementations of this architecture such as Apache Hudi, Delta Lake or Apache Paimon.
Now let’s look at potential business use cases for Data Lakehouse and where Nussknacker can help in their implementation.
The application of Nussknacker in Data Lakehouse architecture
The Data Lakehouse can be used in various business use cases. Some of them are:
- Reports
- Batch marketing campaigns
- Customer scoring
- Revenue Assurance
It can also be used in places where relatively low latency is important, such as near-real-time marketing campaigns or for backfilling for streaming pipelines.
Each use case requires some common tasks:
- Data ingestion/egression
- Data discovery
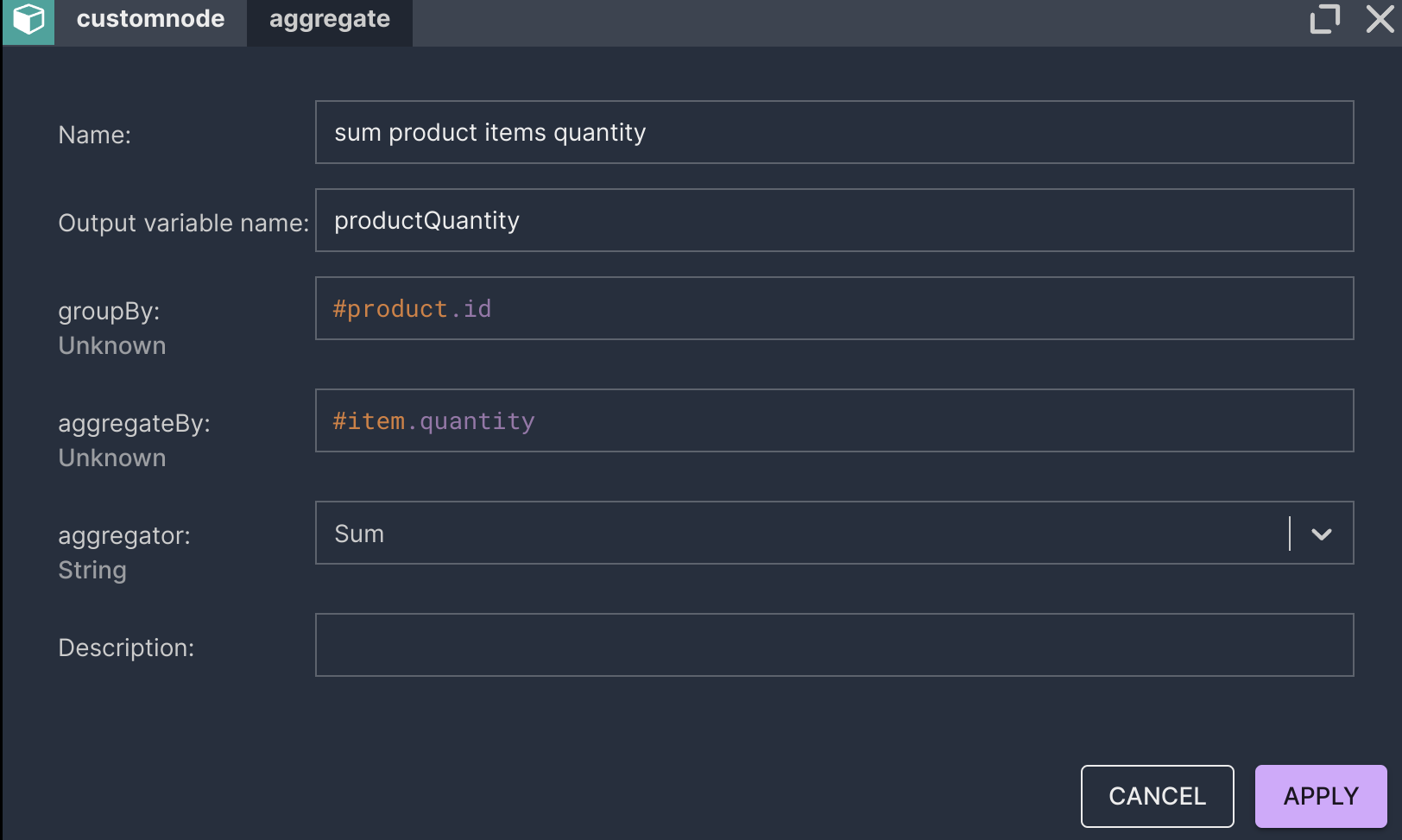
- Data transformations such as unification, deduplication, cleansing, aggregation, enrichment
- ML model feature extraction
- ML model training
- ML model inference
- Applying business logic to prepared data
Nussknacker allows you to realise tasks related to data ingestion, egression, transformations, feature extraction, business logic application and model inference. Let’s take a look at it from the perspective of these tasks.
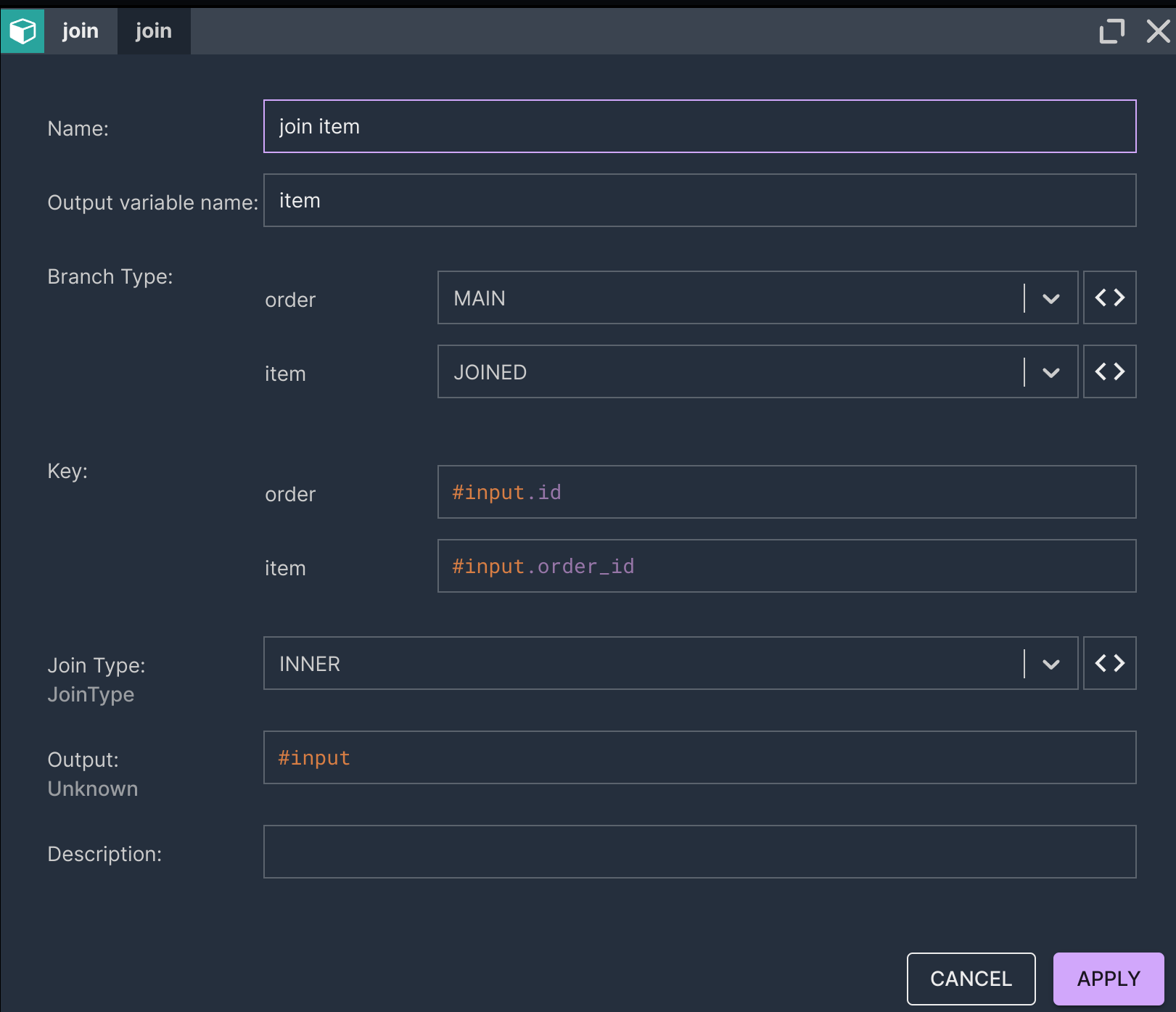
Unlike with compute engines such as Apache Flink, Apache Spark, with Nussknacker, you don’t need to use additional tools: Version Control Systems, Building tools, Integrated Development Environments or Continuous Deployment Platforms to prepare and deploy your solution – you can do everything in one tool. You also don’t need a strong coding background – it uses a similar semantic as SQL queries but in a less restrictive form of graphs. Moreover, it contains components (building blocks of the graph) that allow you to easily model decisions in the flow: filter, choice, split, union, join, decision table, etc. These things help you to focus on business needs and make it perfect for business logic modelling.
Thanks to the rich set of stateful components, enrichers and the SpEL expression language, it allows most data transformations to be handled with ease. It also has a dedicated component for ML model inference, which you can read more about in this blog post. The components and functions available in the expression language are pluggable - you won’t hit a wall when a specific transformation is required.
Data ingestion/egression pipelines are possible thanks to the Flink Table API connectors that are used by our table components.
In addition, Nussknacker, much like Flink SQL, unifies stream and batch processing. Picture a marketing team that wants to implement a batch marketing campaign. It occurs to them that this campaign will perform better if the data is processed in real-time, as then they won’t have to rewrite everything from scratch; they can just reuse the same concepts. Nussknacker takes this a step further. Let’s say that the same marketing team wants to implement a Next Best Action use case. They don’t need to rewrite the architecture either – they can simply use a request-response processing mode that is also available in Nussknacker.
To better understand the role of Nussknacker in this ecosystem, I’ll show how to implement the reporting use case. Nussknacker will be used to define the business logic of the report.
Example use case - periodical report
The use case is straightforward. Additionally, I’ll make some simplifications to ensure that the essential elements are not obscured. As a user, I want to prepare a report for a specific audience. The report will be sent to them once a day. In our company, we have two systems which hold data that I’m interested in:
- CRM (Customer Relationship Management) – which stores orders of products
- CCMS (Component Content Management System) – where we have our model of products that changes over time; new products are added, old products are marked as withdrawn from production, attributes of products are changed, etc.
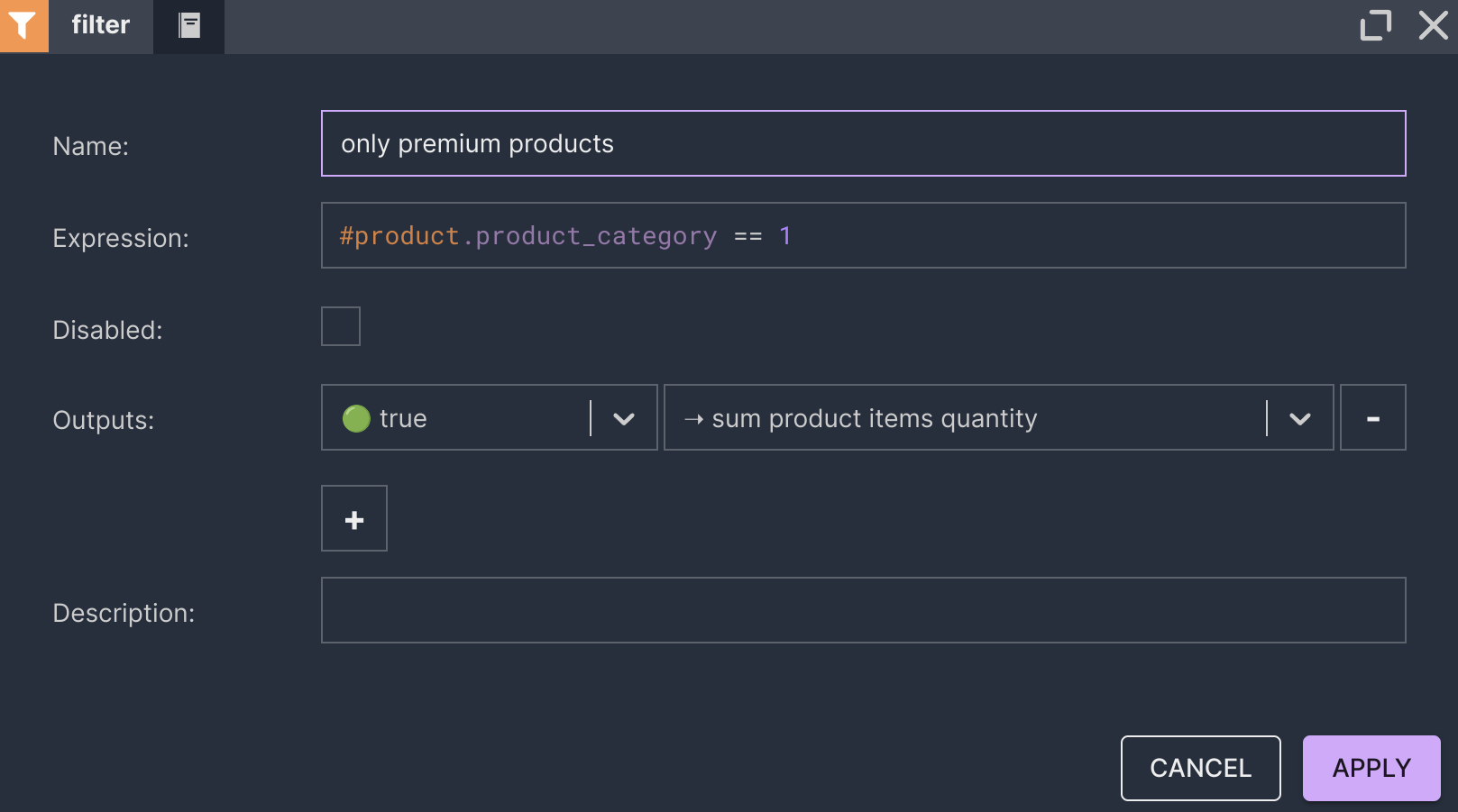
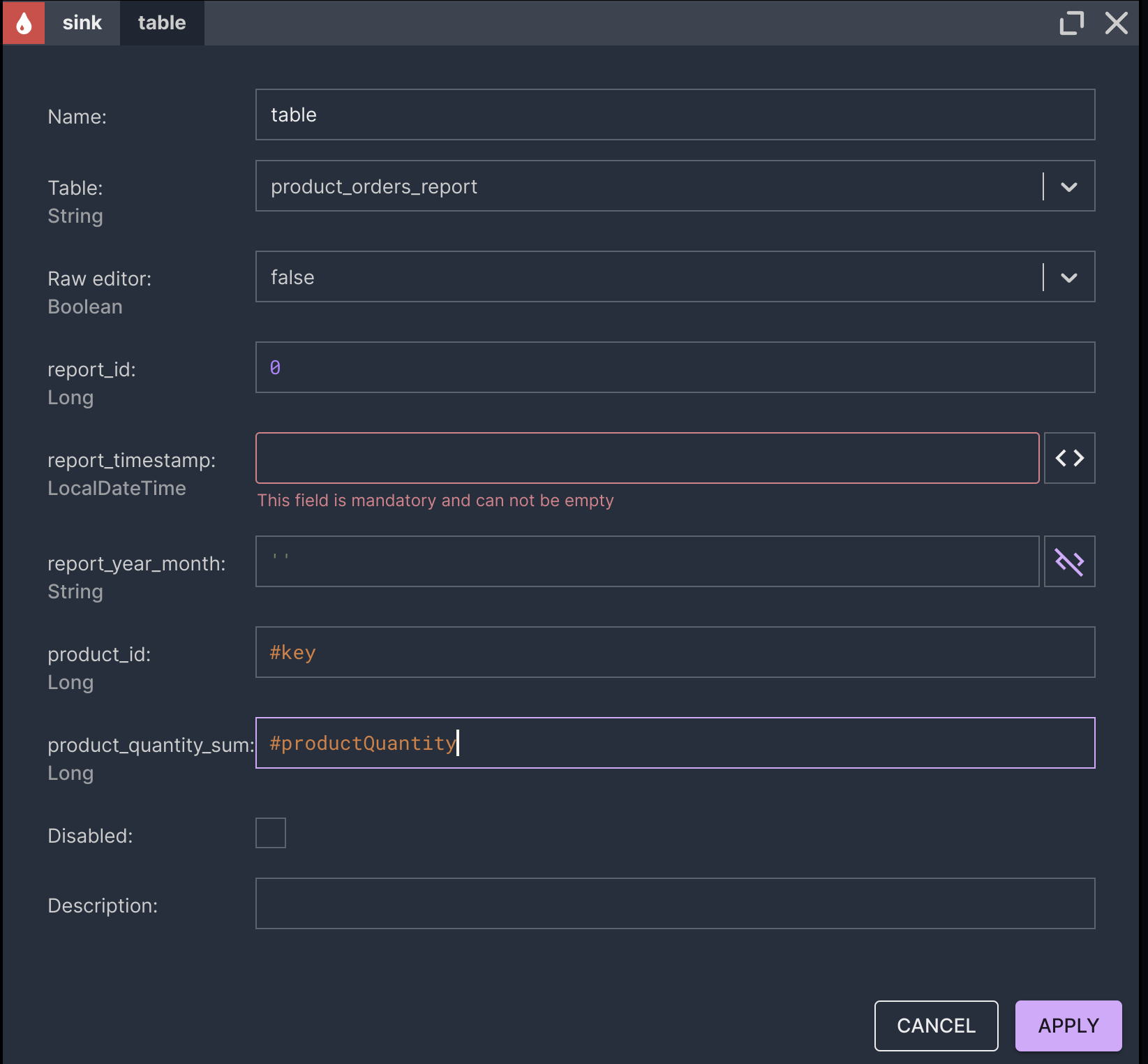
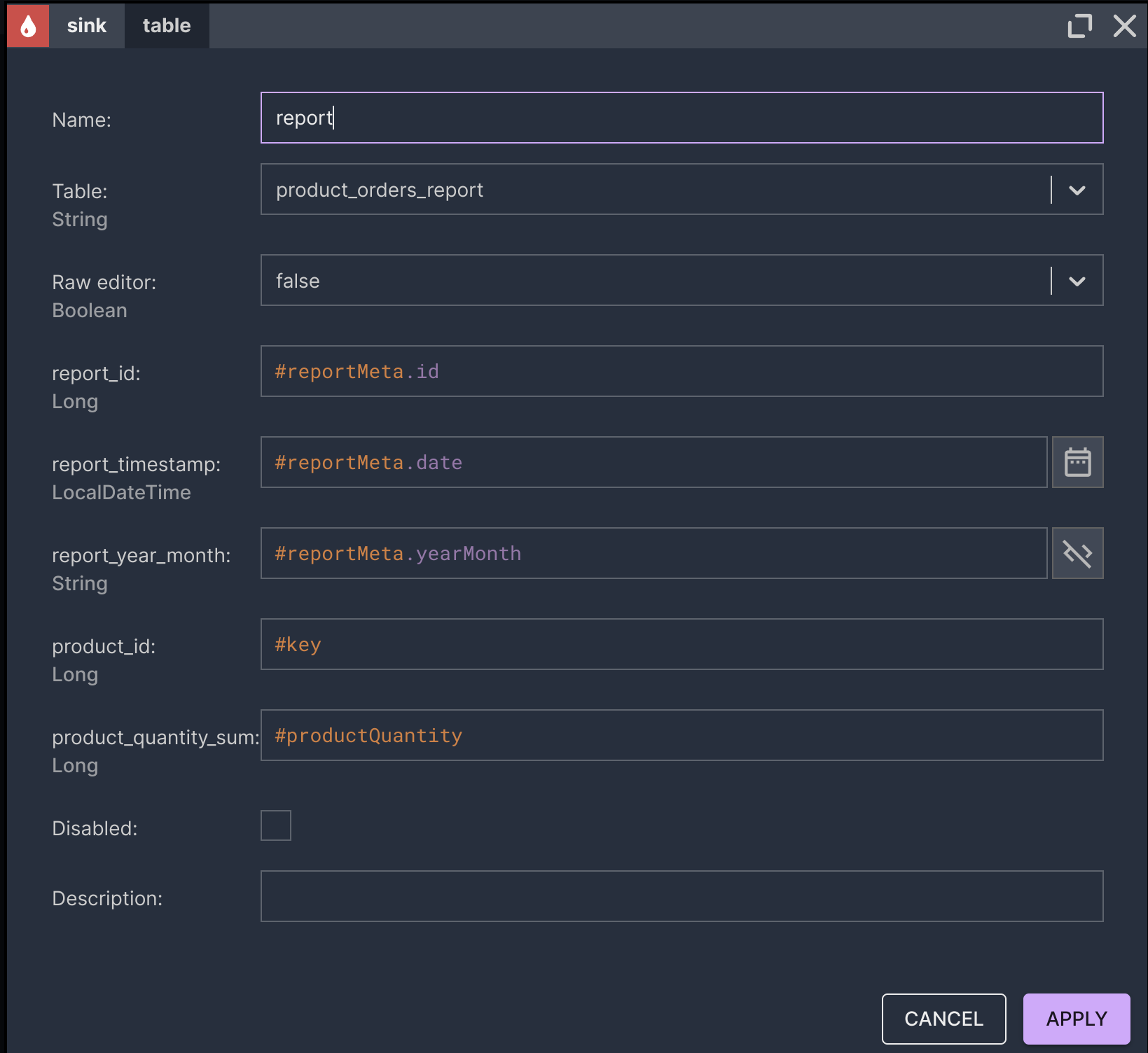
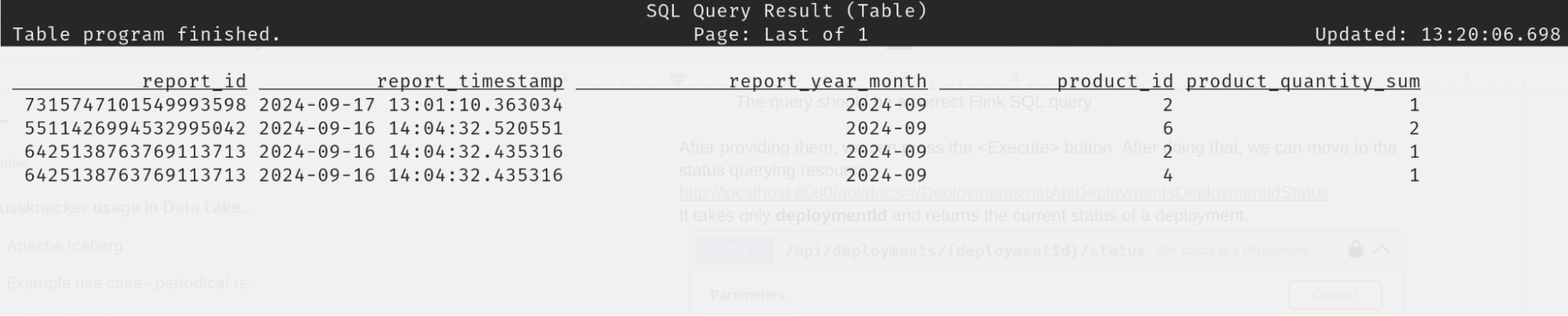
The report should show how many items of each product in the premium category were ordered on a previous day.
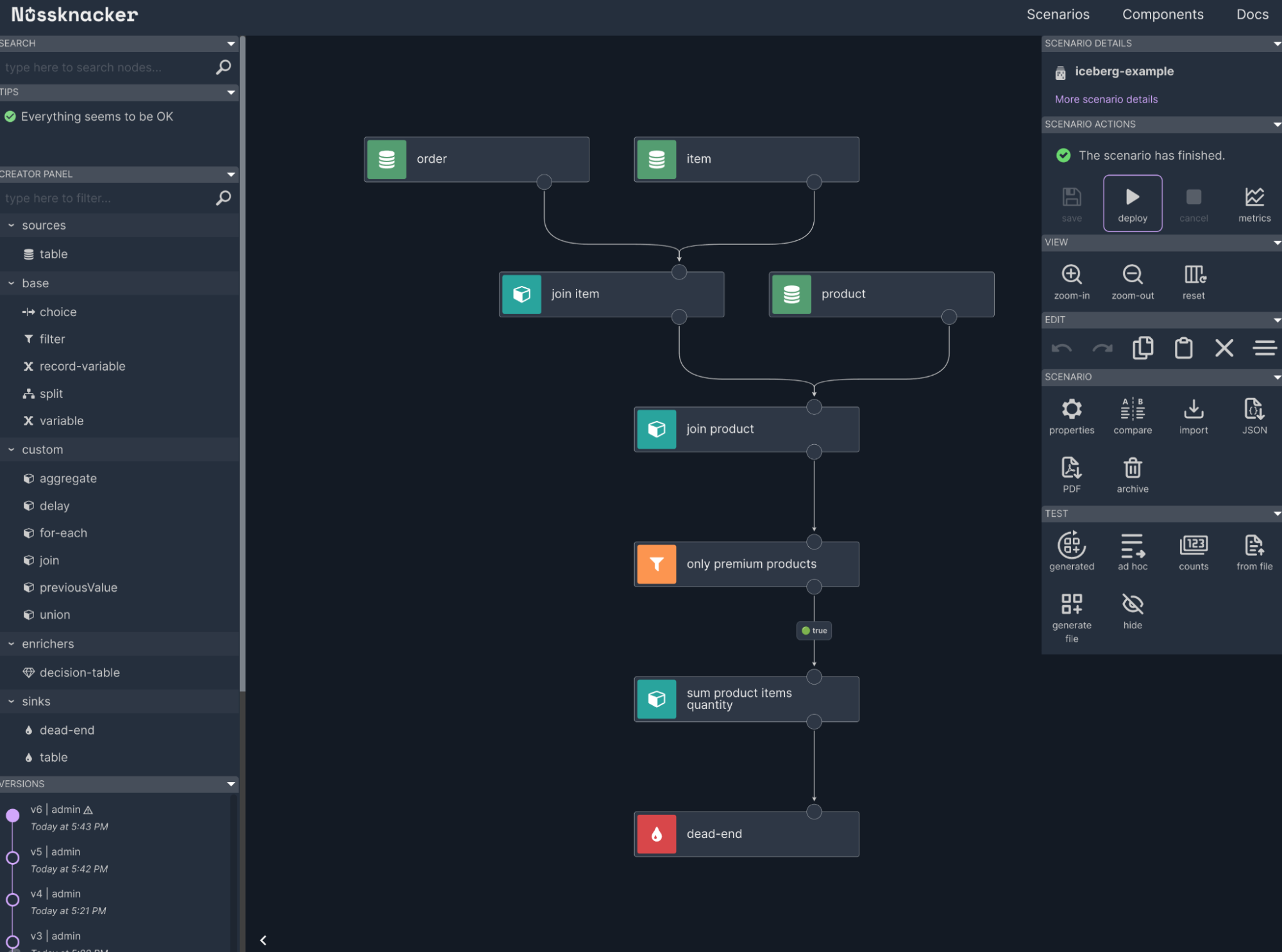
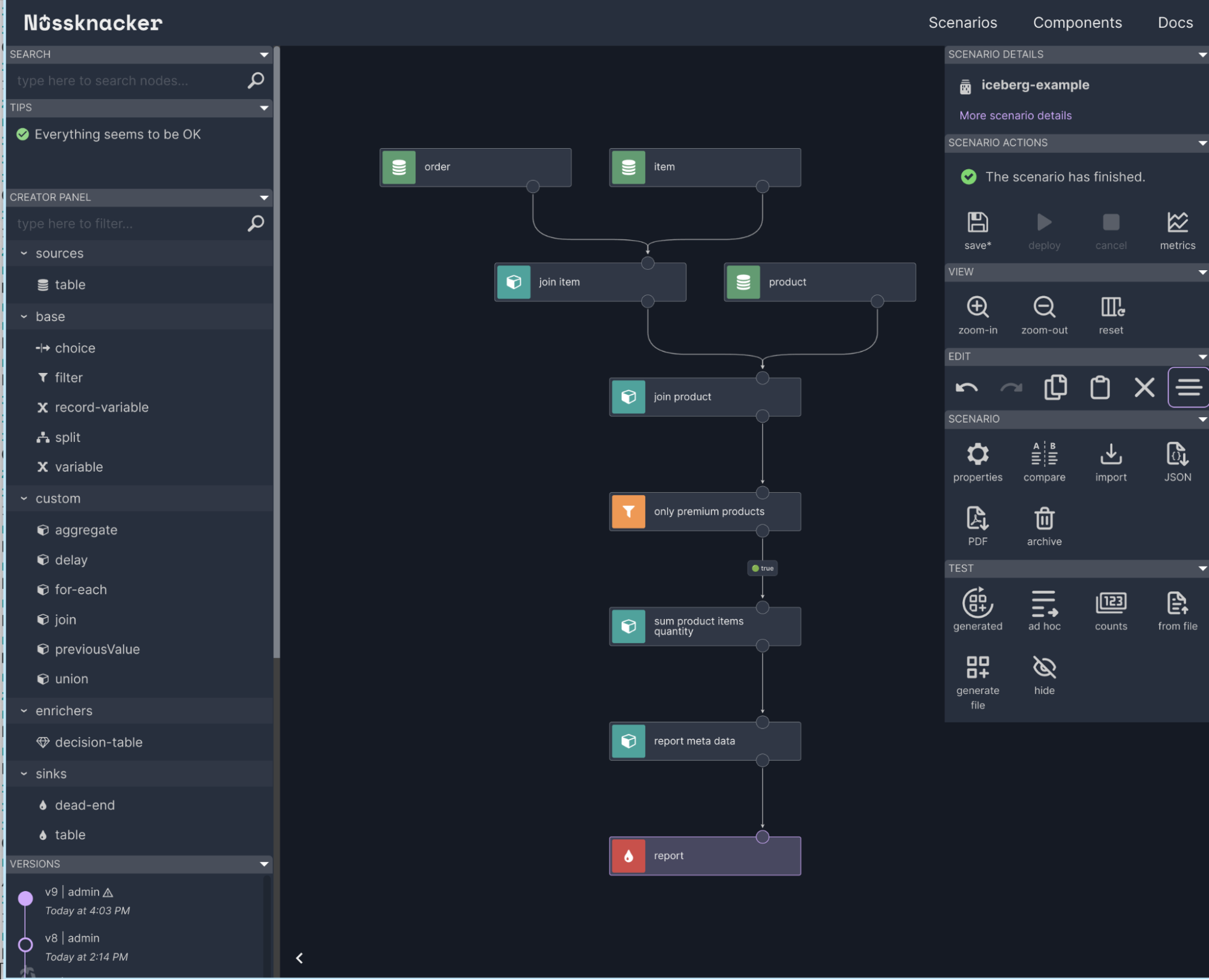
The diagram below shows the architecture that we want to simulate.

The whole process will be split into several steps:
- Data ingestion. We can’t query data from operational systems too often not to infer them. So we must ingest them into another place that can be queried without hassle. This place will be the Data Lakehouse.
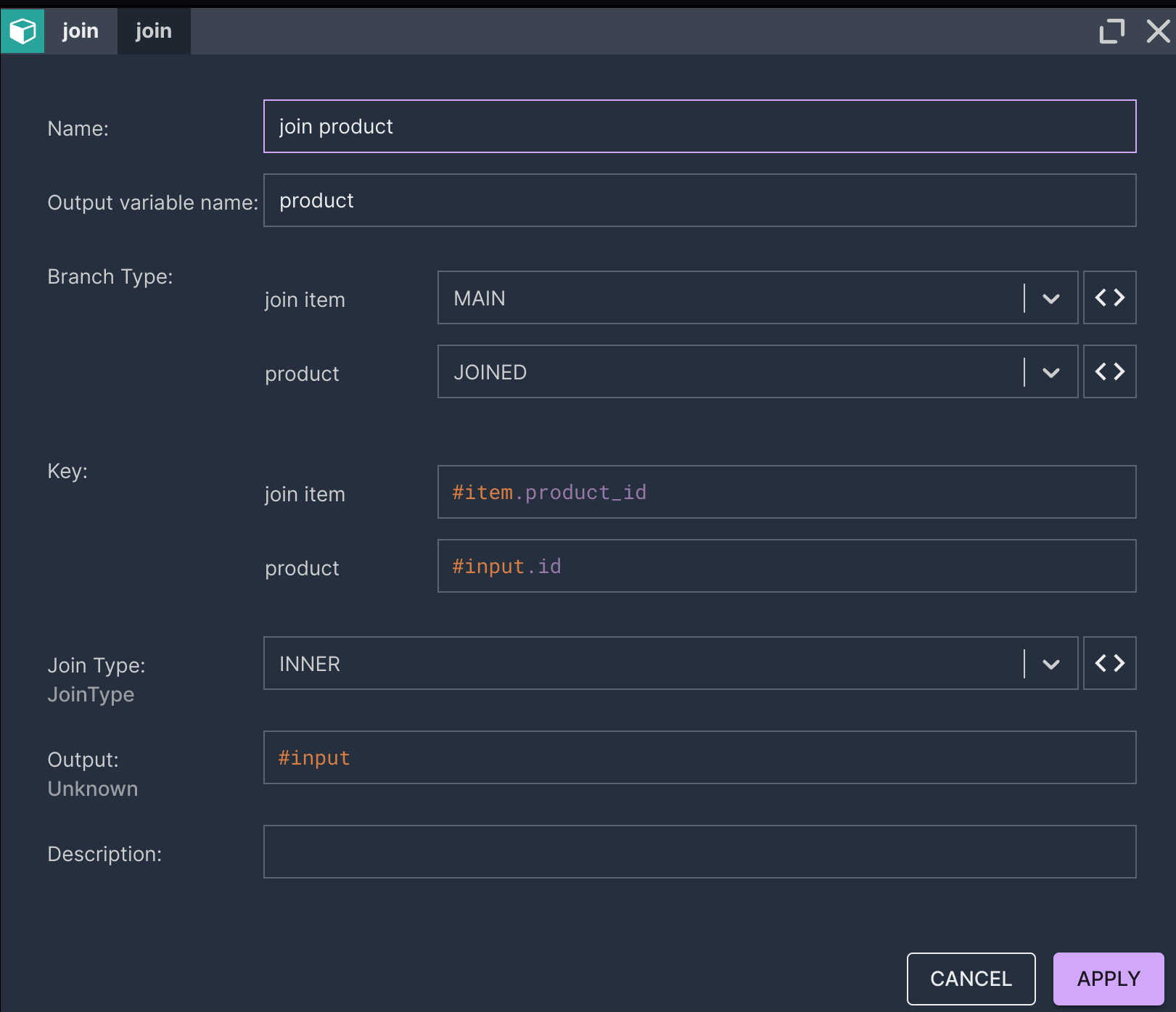
- The user defines the core logic of the reporting scenario in Nussknacker.
- The user defines the schedule in a scheduling system.
- The scheduler triggers a report computation in Nussknacker. Nussknacker produces a report. The report is stored in the Data Lakehouse for record-keeping purposes.
- The report is passed to the mail delivery system. This is a reverse process to ingestion. It can be called egress.
Simplifications
Shortcuts that will be applied:
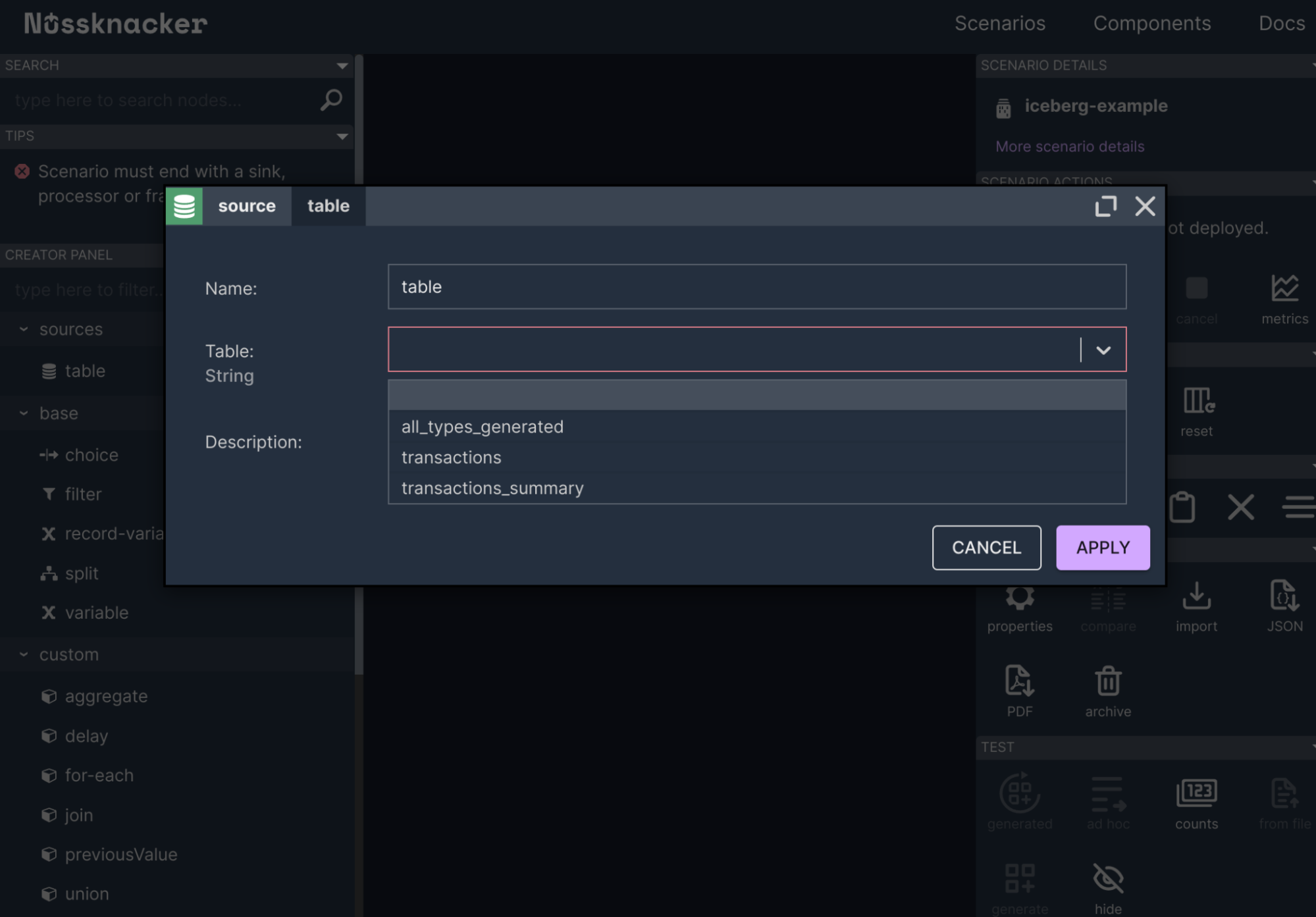
- Data ingestion – we’ll mock external systems by inserting queries written in Flink SQL. In a production environment, we would have jobs that do these ingestions. These jobs could be defined, for example, in Nussknacker.
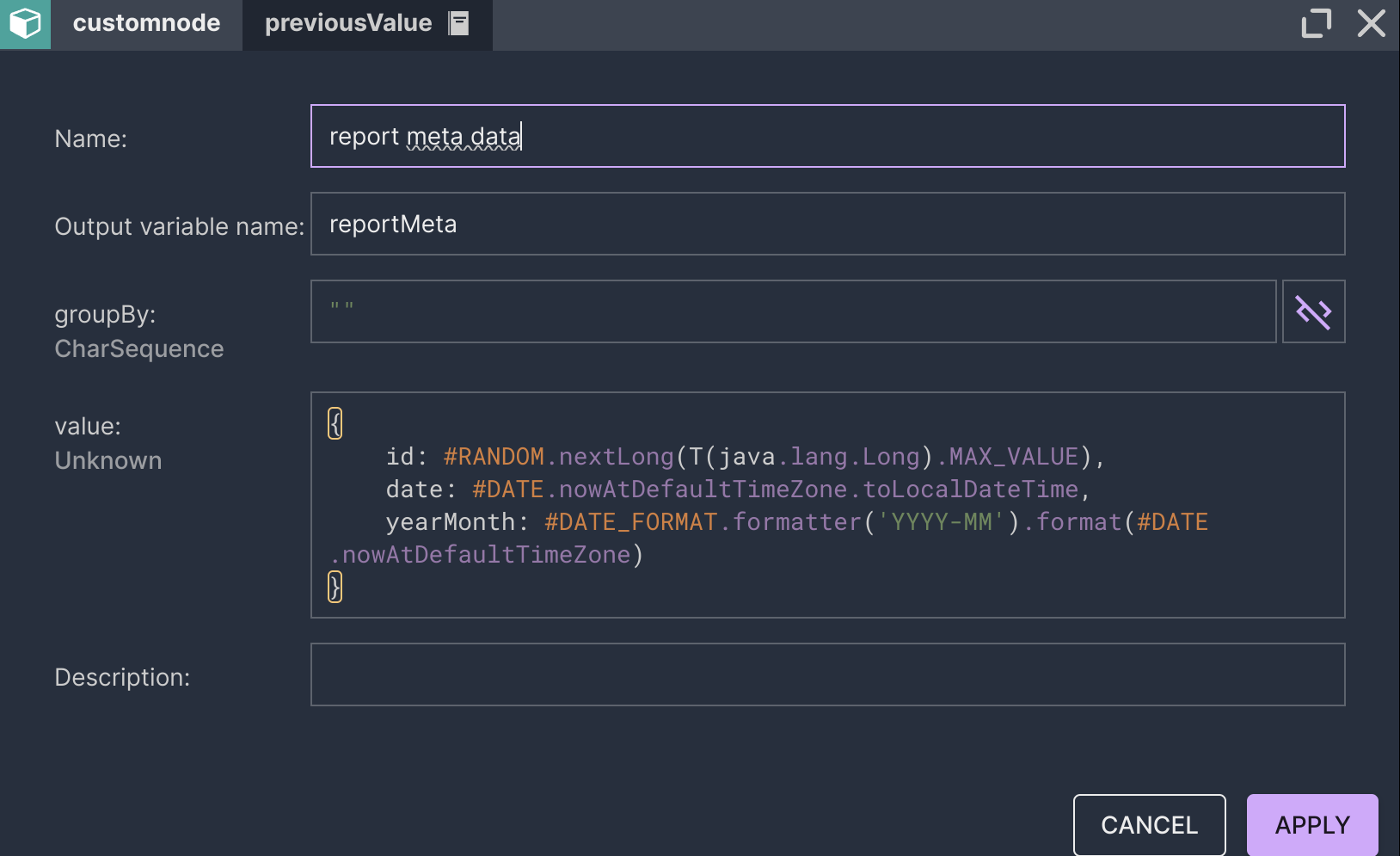
- We won’t process product changes. Instead, we’ll use a materialised form of products for a certain moment in time. In a production environment, we would process CDC (Capture Data Changes) to get the full advantages of time travel.
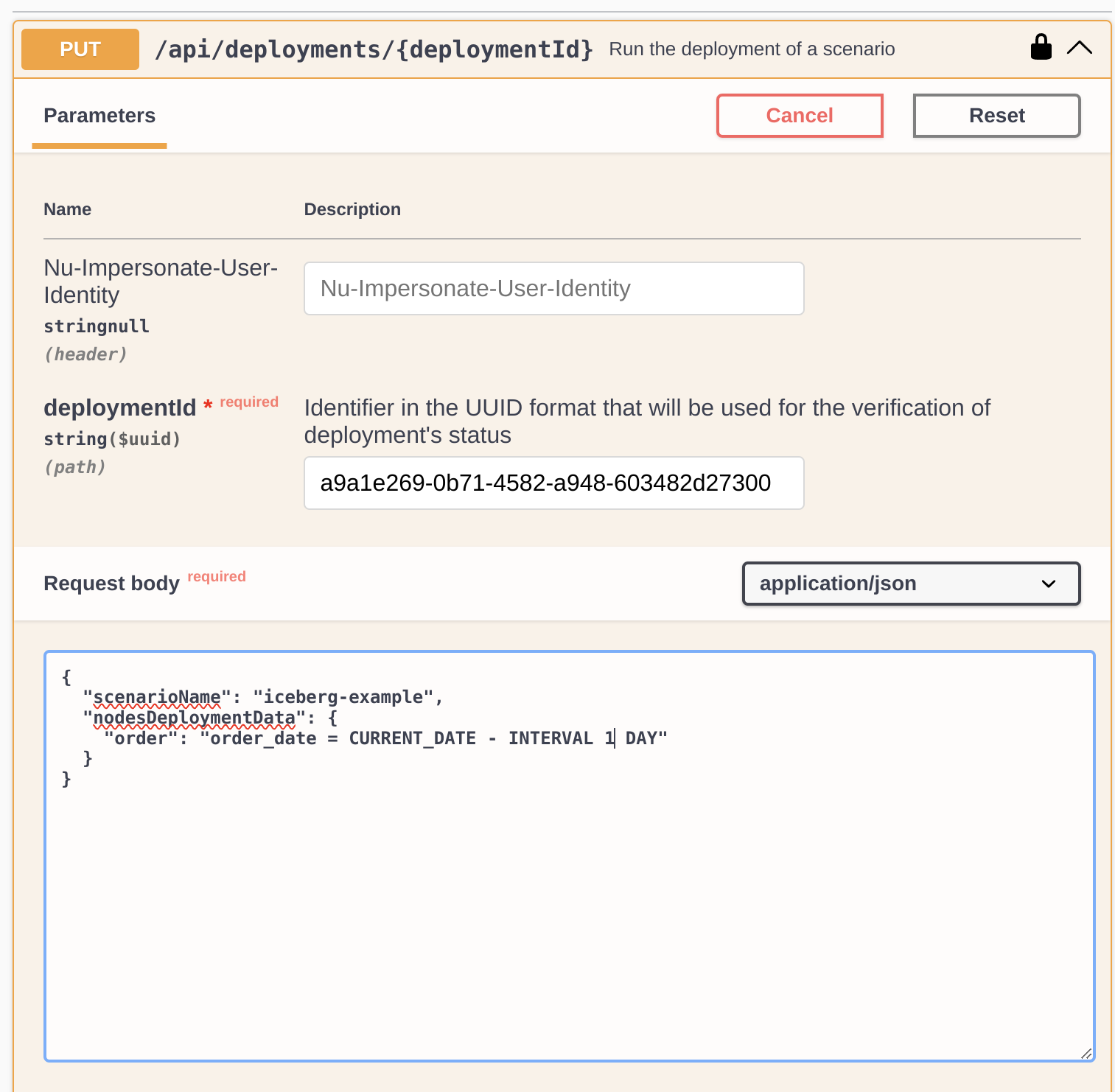
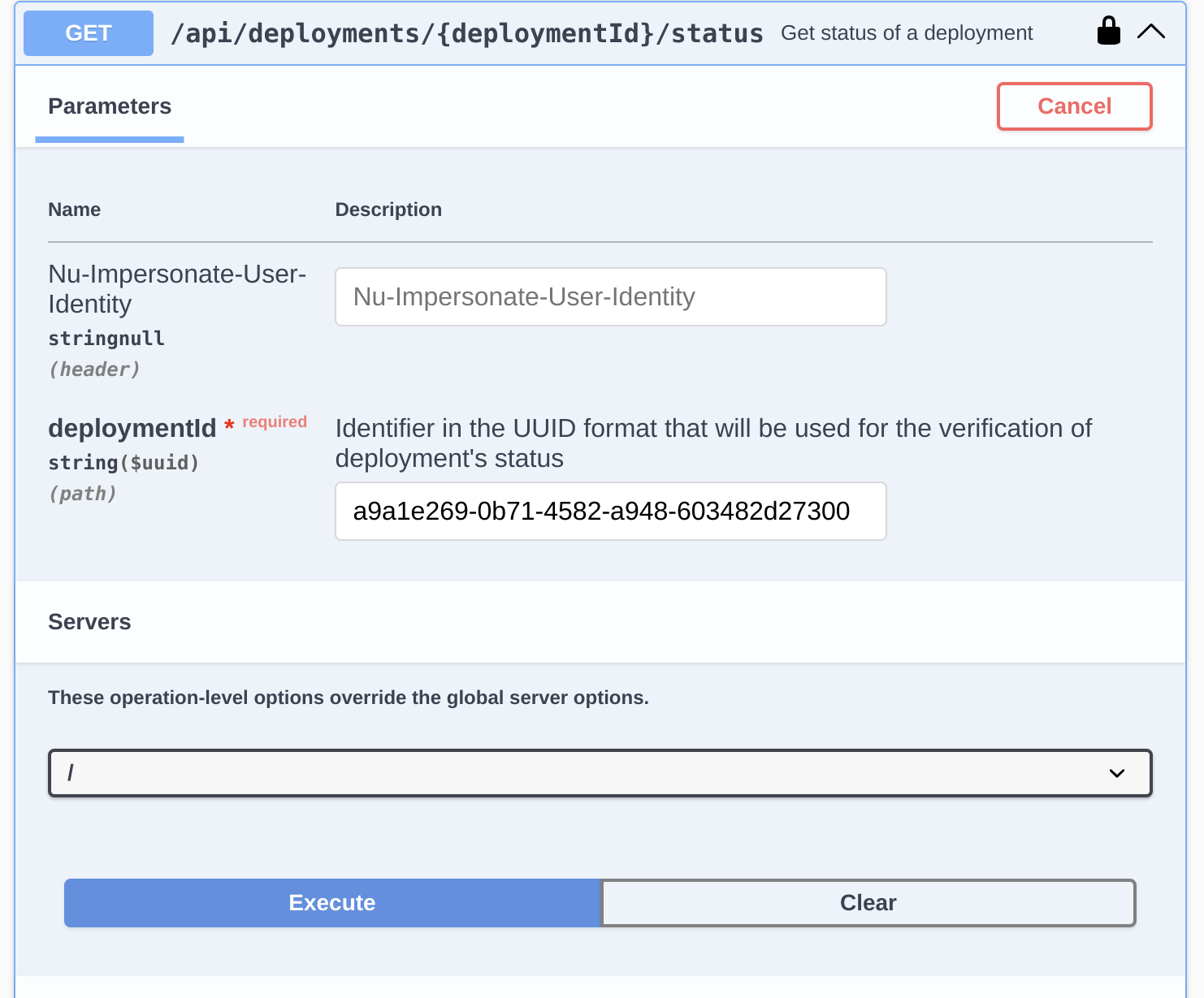
- We omit the scheduler step. Instead, we’ll show what the invocation of Nussknacker deployment’s API would look like. In a production environment, we might use an application such as Apache Airflow or crontab for that.
- We will also skip the egress step – as was the case with ingestion, it can be done by combining Nussknacker with a connector handling email delivery. We’ll only check the result by querying the result table with Flink SQL.