Batch processing with scalability and fault-tolerance
Nussknacker was developed as a tool to enable domain experts to express the domain logic without having to code and it originally supported only stream processing. The complexity of operating on streams within infrastructure based on Apache Flink and Apache Kafka was not suitable for all our users’ use cases. This led to creation of the Lite Engine, which enabled Nussknacker scenarios to be deployed in the Request-Response paradigm.
Seeing the merit in the growing trend of unifying different paradigms, formats and technologies in the Big-Data ecosystem the development team behind Nussknacker took it as a priority to deliver the batch processing mode to our users as part of our open-source solution. Powered by Apache Flink, your Nussknacker batch scenarios will have the scalability, fault-tolerance and guarantees to handle the requirements of big-data systems.
Sneak peek at Batch Mode
To put it all into context, let’s take a look at a simplified batch scenario within Nussknacker. As of now, batch mode integration is in the early stage of development, but we wanted to give you a taste of what’s coming. Keep in mind that basically all of the functionality featured here is not final and will be significantly improved in the near future. If you want to follow along on your own machine - the code for this example and the instructions on how to run it are within the dedicated GitHub repository.
The problem
For this showcase to make sense let’s imagine a specific problem to solve. Let’s imagine a business analyst working at some bank that needs to calculate the sum of all transactions made by each client per day from 08.05.2024 to 11.05.2024. The transactions are stored in a csv (comma separated values) format in the transactions-data/transactions folder. The files are also partitioned by date - each subsequent folder has a name referencing the date of transactions it is storing. For example, a folder named ‘date=2024-05-09’ will contain only transactions that occurred on 2024-05-09. If you’re familiar with Apache Hive, you’ll notice that this corresponds to the standard Hive format. Partitioning like this is a common practice that helps with data ingestion.
Data source
For this showcase task, inside the csv files, each transaction is represented by a row with the following structure:
| Column name |
datetime |
client_id |
amount |
| Data type |
Timestamp |
String |
Decimal |
| Meaning |
Exact moment in time of registering the transaction |
Name of the client ordering the transaction |
Amount of cash in dollars transferred |
| Example |
"2024-05-08 01:48:54.275" |
"Koda Rivers" |
291.53 |
This structure (data schema) is configured in a dedicated configuration file. Currently, Nussknacker uses Flink SQL’s DDL (Data Definition Language) – mostly ‘CREATE TABLE’ statements, You can read more about the relevant Flink SQL syntax in this Flink documentation section. Besides the data schema, the data source definitions from the configuration file specify the data format and the connector. Connectors are adapters that allow Flink to read and write to external systems. Both input and output are using a filesystem connector and pointing to their dedicated folders in the transactions-data folder. You can read about connectors in this Flink documentation section. The way these sources of data are defined in Nussknacker will change in the final release, but the main takeaway is this: integrating with external systems will be stupid-simple - no custom code required. This is also one of the improvements we plan to carry over to streaming mode.
Ingesting the transactions
Nussknacker scenario for this use case looks like this: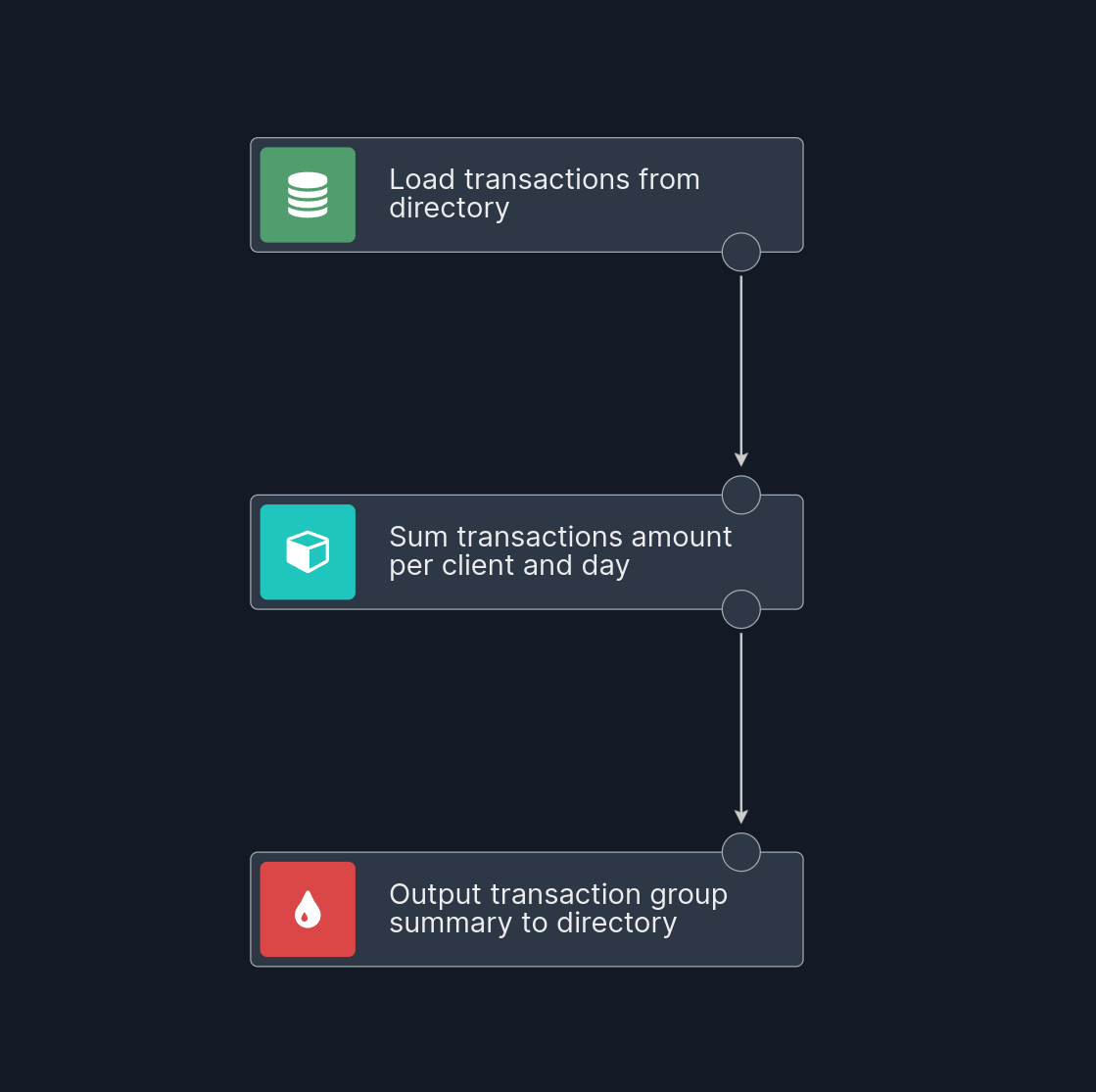
Looking at the graph, you can generally guess how it works. The top node defines the source of the input data. The scenario will ingest data from the data source defined previously with corresponding name and pass it to the nodes below. In this case, data is ingested from the transactions data source. Using the new, streamlined approach the source node boils down to pointing at the desired data source.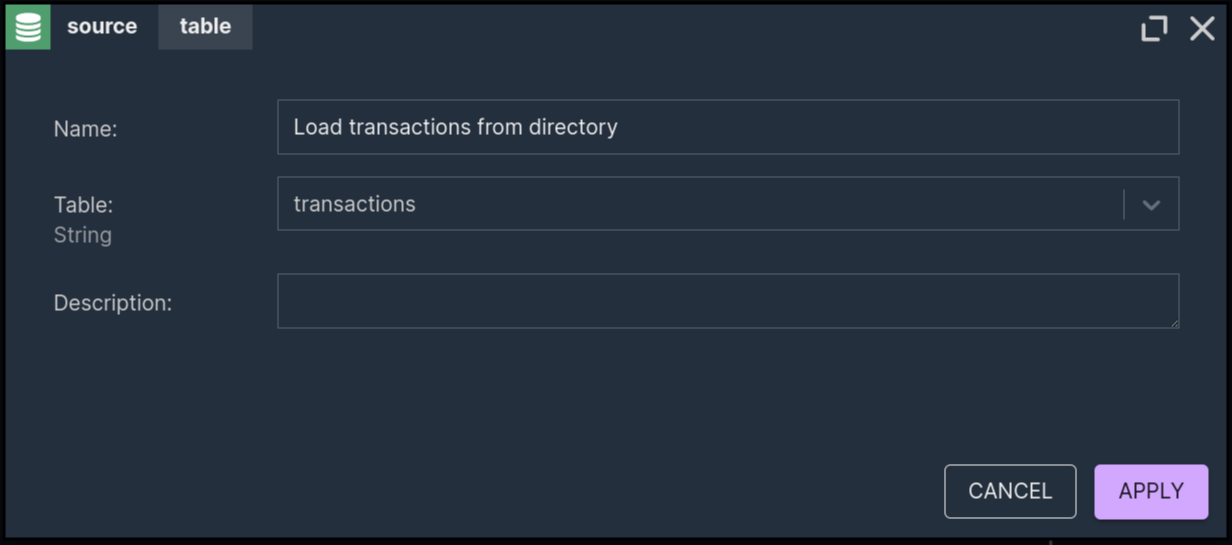
Let’s check out the heart of the scenario - the aggregation node.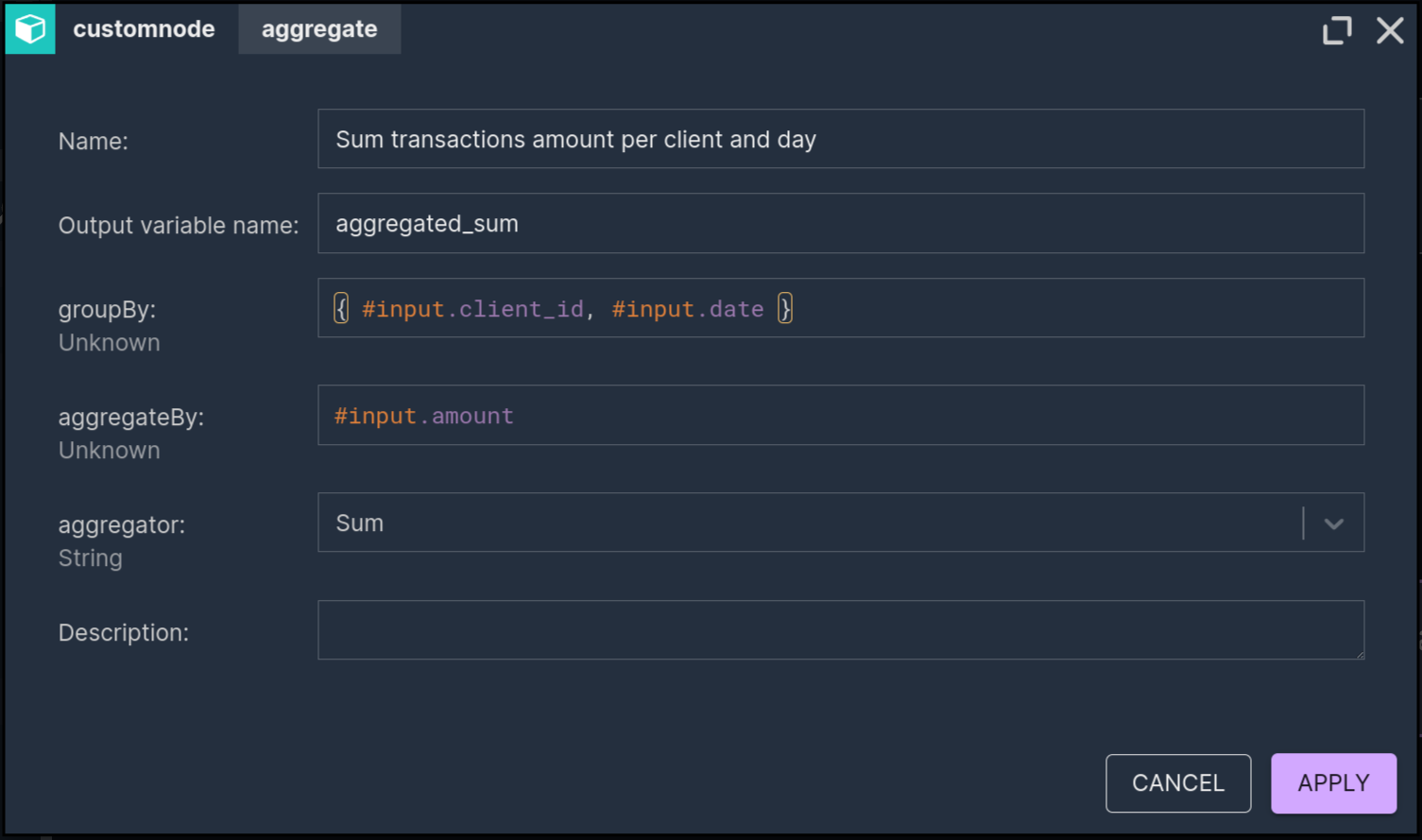
The new batch aggregation node is similar to the aggregation nodes from streaming processing mode. The main difference is that we don’t have to specify a time window (a time range) - and that is the essential difference between streaming and batch. In batch, if there’s no window defined, all of the values from the input will be aggregated. This greatly simplifies how you reason about the processing logic. You don’t have to think about window types, triggers or lateness. You could say that in this case we also need some kind of a time window, but we can do it in a much simpler way and we’ll get to that soon. Though keep in mind that the aggregation component is very bare only at this early stage - in the public release we plan to improve its usability and add some advanced features.
Let’s take a look at the final node - the sink: 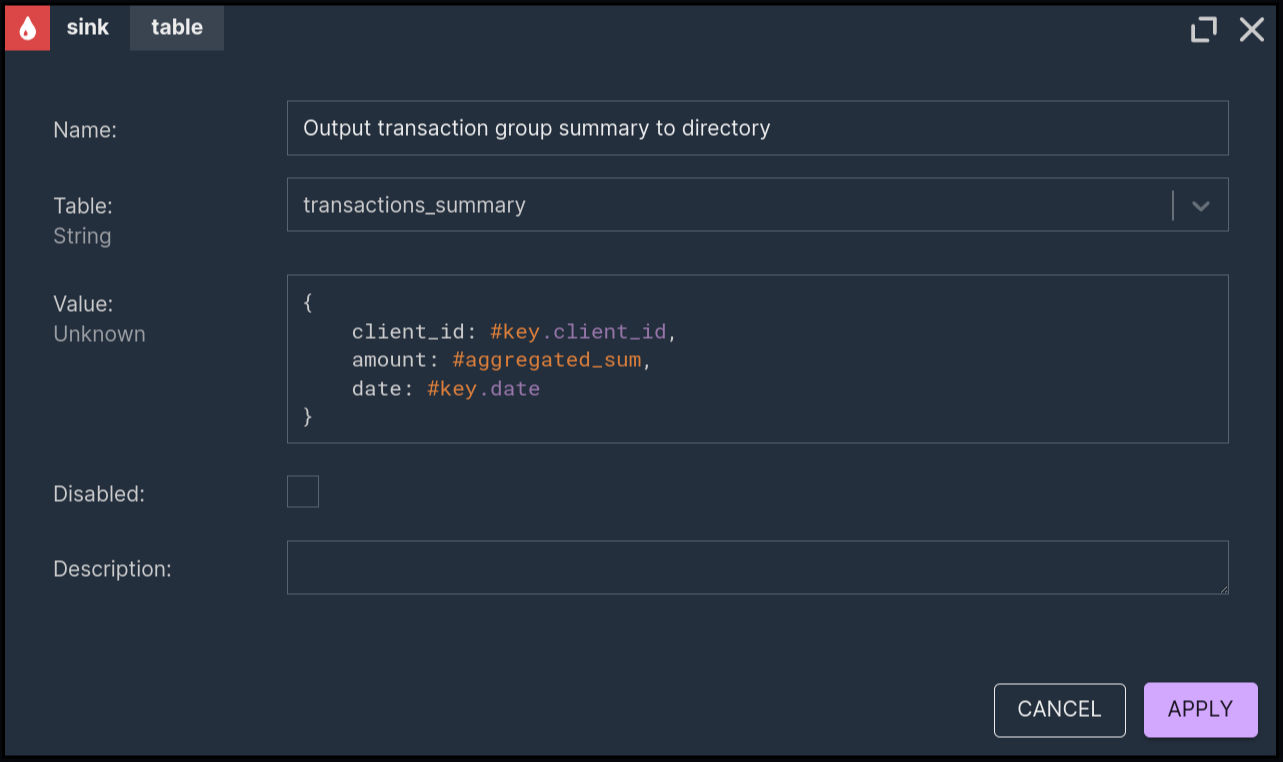
Here the results from the aggregation are transformed into records that will be written to the specified table. From the data sources configuration file, the transactions_summary table has the same schema as the source’s transactions table, just without the datetime column, containing the exact moment of the transaction with millisecond precision, which wouldn’t make sense after daily aggregation.
After walking through the scenario in detail one business requirement is still missing. The aggregation was supposed to be done in a specified time range. We could modify the scenario to implement this range as a filter node. But what if the requirements change and we have to process the data on another range? Reports such as this are usually done daily and are scheduled periodically so each time we’d have to modify the scenario before running the deployment. However, it's not hard to see that the added step of modifying the scenario each time would be frustrating and error-prone. That’s why in version 1.15 we’ve added deployment-level parameters, allowing for specifying some processing logic when requesting a deployment.
Deploying with parameters
For batch sources we can specify an SQL filtering expression at the time of deployment. For that, let’s go on a trip outside of the Nussknacker Designer’s UI into its lower-level REST API. Ultimately we plan to implement this functionality as a part of the user interface, but for the purposes of an early showcase, we can use the UI in the form of OpenAPI. If you’re following along with local deployment, you can find the relevant functionality at: http://localhost:8080/api/docs/#/Deployments/putApiDeploymentsDeploymentid.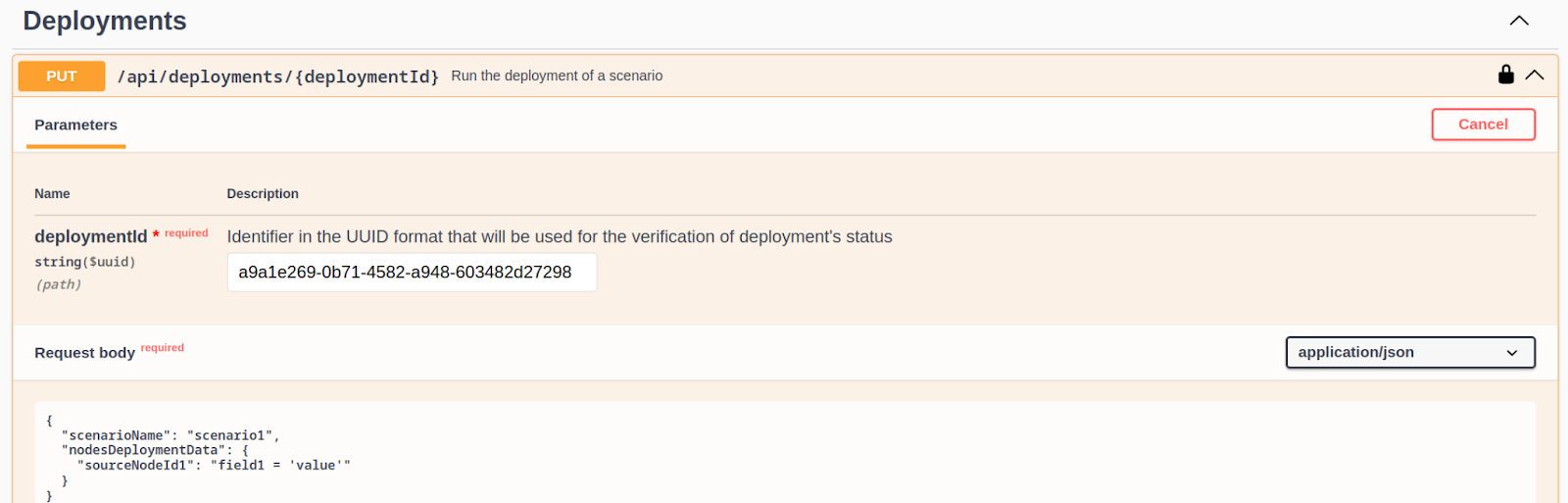
In the request body in a json format, we set the scenarioName to SumTransactions - the name of our scenario. Under the nodesDeploymentData we specify the names of the nodes and parameters to pass into these nodes. If we want to process data from the time range of 08.05.2024 to 11.05.2024, the expression to use is: "datetime >= '2024-05-08' AND datetime < '2024-05-12’".
The final request body should look like this:
{
"scenarioName": "SumTransactions",
"nodesDeploymentData": {
"Load transactions from directory": "datetime >= '2024-05-08' AND datetime < '2024-05-12'"
}
}
After a request is made, when we check the transactions-data/transactions_summary, we see the aggregated results. If you’ve followed along then congratulations - you are one of the first people to run a Nussknacker batch scenario!
If you want to experiment with it, you can check out the second scenario - GenerateTransactions. This scenario was used to generate the data for this showcase. You can experiment with the transactions_generator table by ramping up the number of generated rows or changing the column data types and the expressions to populate them. This data source uses the faker connector and you can read more about how it works in its repository on GitHub.
The Future
Why is all of this such a big deal for Nussknacker? Well, we don’t want to just slap a new way of processing data on top of everything we’ve built and call it a day. The plan is to integrate batch mode as a first-class citizen besides streaming and request-response modes. We also need to ensure that we satisfy requirements of our user groups.
For scenario authors, we want to provide a viable alternative to Flink SQL by offering a well designed interface where only business-specific concepts are exposed and no little to no knowledge of SQL is required. In the context of batch mode, we plan to do that by providing a new set of components that allow for complex operations when needed. Finally we aim to unify these components with the current streaming ones, so that transition between both processing modes becomes seamless and easy to reason about.
For technical users, we want to limit the complexity of integrating Nussknacker with external systems. This is already much improved by using the connector ecosystem of Apache Flink. As of now, in streaming mode, if you want to ingest data from a source that’s not Kafka or using different formats, you have to write your own component. Even though you can pretty easily write your own source or sink by effectively wrapping a connector, it’s still writing code. Using the connectors consistently in batch and streaming modes will lower the barrier of entry considerably.
With the upcoming batch mode and other improvements, Nussknacker will be ready to fulfill the role of a central piece in your data processing architecture that unifies business logic in one place. It doesn’t matter if you process your data as streams, in batches or if you need a request-response service - Nussknacker will fit your architecture regardless of whether it’s modelled after lambda or kappa architectures, or whether your data is in a warehouse, lakehouse or a streamhouse.
Mateusz Słabek
