
Classic recommendation approaches, such as Collaborative Filtering and Content-Based Filtering, require deep ML knowledge and sometimes specialised infrastructure. Moreover, those models need historical data to be trained - e.g., history of purchased products or other interactions with products. As a result, using the classic approach to generate recommendations may turn out to be expensive both in terms of the cost of the solution and time to deliver.
In this post, we explore alternatives that are enabled by the advancements of Large Language Models and tools used for data stream processing.
“HyDE/GAR” approach instead of RAG
Probably the most well-known approaches to work with LLMs in terms of providing context are:
- RAG - searching some storage for context that can be helpful in the given LLM invocation. Mostly using specialised Vector Stores and embedding models, but other techniques like full-text search can be used instead.
- Fine-tuning - creating pretrained models on top of existing LLM models - e.g., training a new model on the whole updated shop’s offering every day.
In the post, we will try a different approach - similar to HyDE (Hypothetical Document Embeddings) or GAR (Generation Augmented Retrieval) approach. We’ll instruct a model to think up an “ideal” product description based on descriptions of products viewed by a customer, and then to find a real product in our shop by similarity, using a Vector Store.
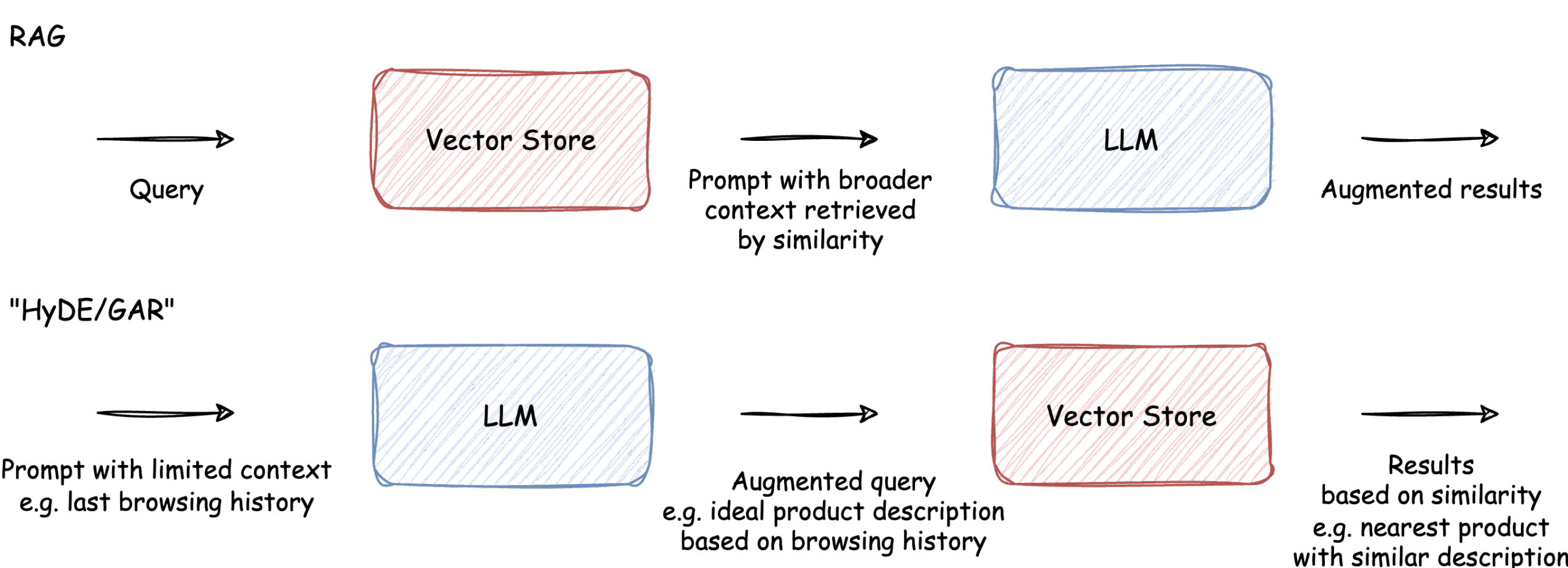
Such an approach allows us to use common knowledge already put in a given LLM without learning a model about our whole stock (like in Fine Tunning) or prefiltering products that should be taken under consideration (like in RAG).
Performing recommendations in Nussknacker
If this is the first time you encounter Nussknacker, read the following short documents to understand what Nussknacker is and how real-time decision algorithms are built with Nussknacker:
- https://docs.nussknacker.io/documentation/docs/about/Overview/
- https://docs.nussknacker.io/documentation/docs/about/KeyFeatures/
In the next sections, we will at a high level explain how Nussknacker supports building functionalities needed for the recommendation engine.
Events filtering and transformation
The event stream from your e-commerce site probably contains millions of events. You can use Nussknacker and its expression language to filter out unwanted events and transform them as required - you can find more about transforming data here.
Events aggregation
Nussknacker allows to perform various aggregations on events contained in data streams. It can help to detect situations when we want to perform some logic, e.g., call an expensive LLM or gather aggregates of data over time to calculate input to our decision scenarios.
We have at our disposal tumbling, sliding, and probably the most useful - session window.
Integrations with external systems
We can use multiple integrations with external services like databases, message brokers, ML models catalogs, and HTTP services. The following integrations are used for enrichments and as data sources and destinations. Because of that, Nussknacker can be easily used with systems already existing in your environment.
LLM and vector store support
Nussknacker integrates with various LLM models. For now, we support chat and embedding models from Mistral AI and OpenAI. Users can fully customize prompts based on data available in a Nussknacker scenario. Chat response becomes available for further computation in the scenario.
Interaction with vector stores is also available. Nussknacker scenarios can enrich data by searching Qdrant and Pinecone Vector Stores. Vector Store can be fed either from Nussknacker scenarios or directly using the given vector store API.
The Recommendation scenario
Let’s assume that we have a chain of retail stores with an additional e-commerce channel where customers can browse products (mobile app). Additionally, let's assume that we have real-time information about customers' location in the shop, from indoor positioning of an opened e-commerce mobile app or smart scanner.
We want to recommend products to such customers based on their e-commerce product browsing history.
In the following post, we will only point out the most crucial elements, like joining an e-commerce click stream with user location in a shop, detecting first visit in a store department during shopping, invoking LLM, and searching vector store for the nearest product matching the description recommended by LLM.
The whole example scenario can be found on our Cloud Demo.
Joining user visit events with clickstream from the e-commerce channel
Before we can call our model, we need some facts about the customer. Typically, companies build some kind of customer profile service as a dedicated service, database, or data lake - depending on scale and time/space requirements.
Alternatively, when working with streams, events can be enriched by joining them with events from different streams. Using such an approach, we can use more recent data (of course, it depends) and/or be more flexible - we don’t have to implement additional statistics/fields about users (e.g., in data warehouse), but we can compute them for our own in place of need from events.
Such a stream join can be done in Nussknacker using Single-Side Join component.
We enrich events about customer location in shop with information computed from the last viewed products in the e-commerce channel in a given category.
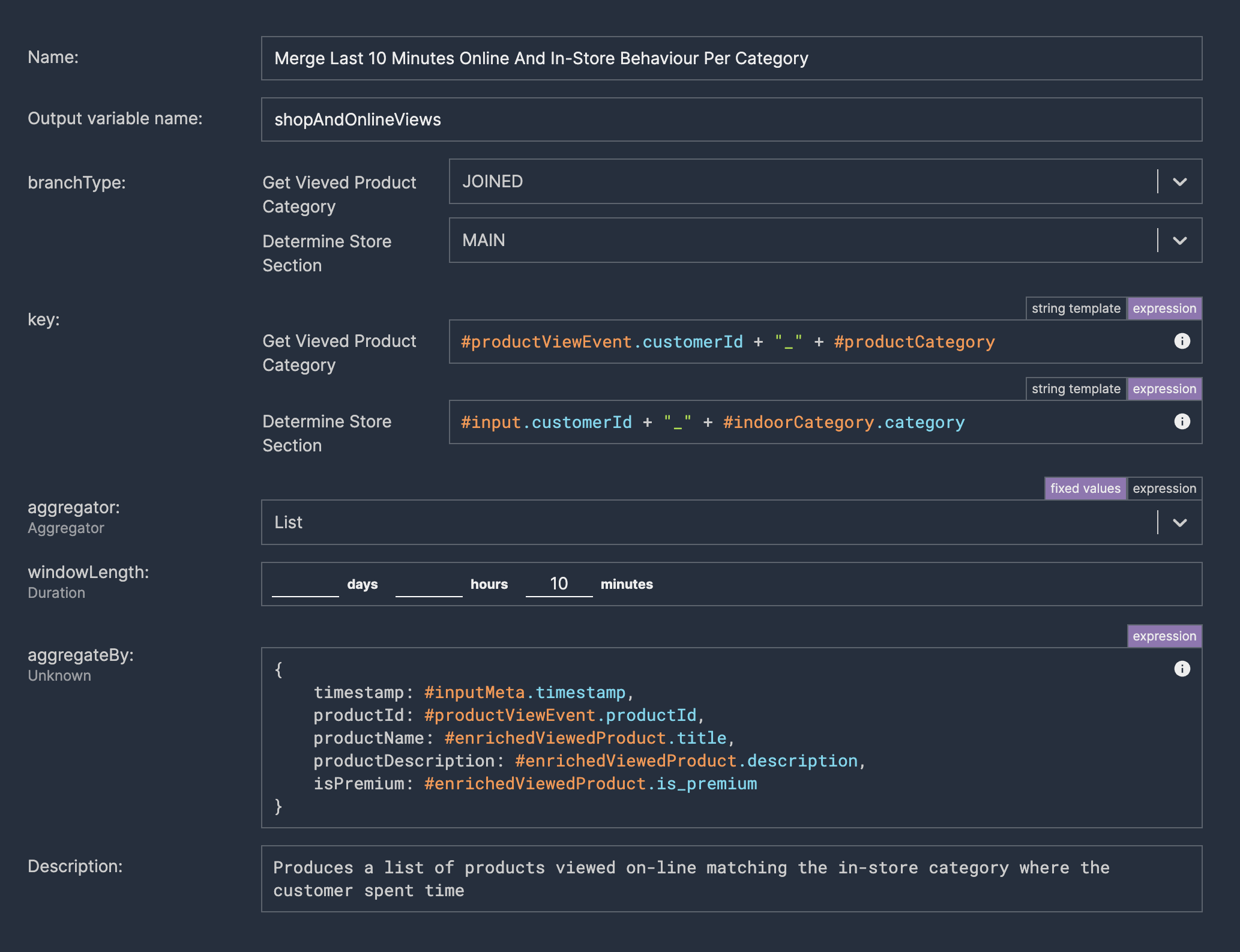
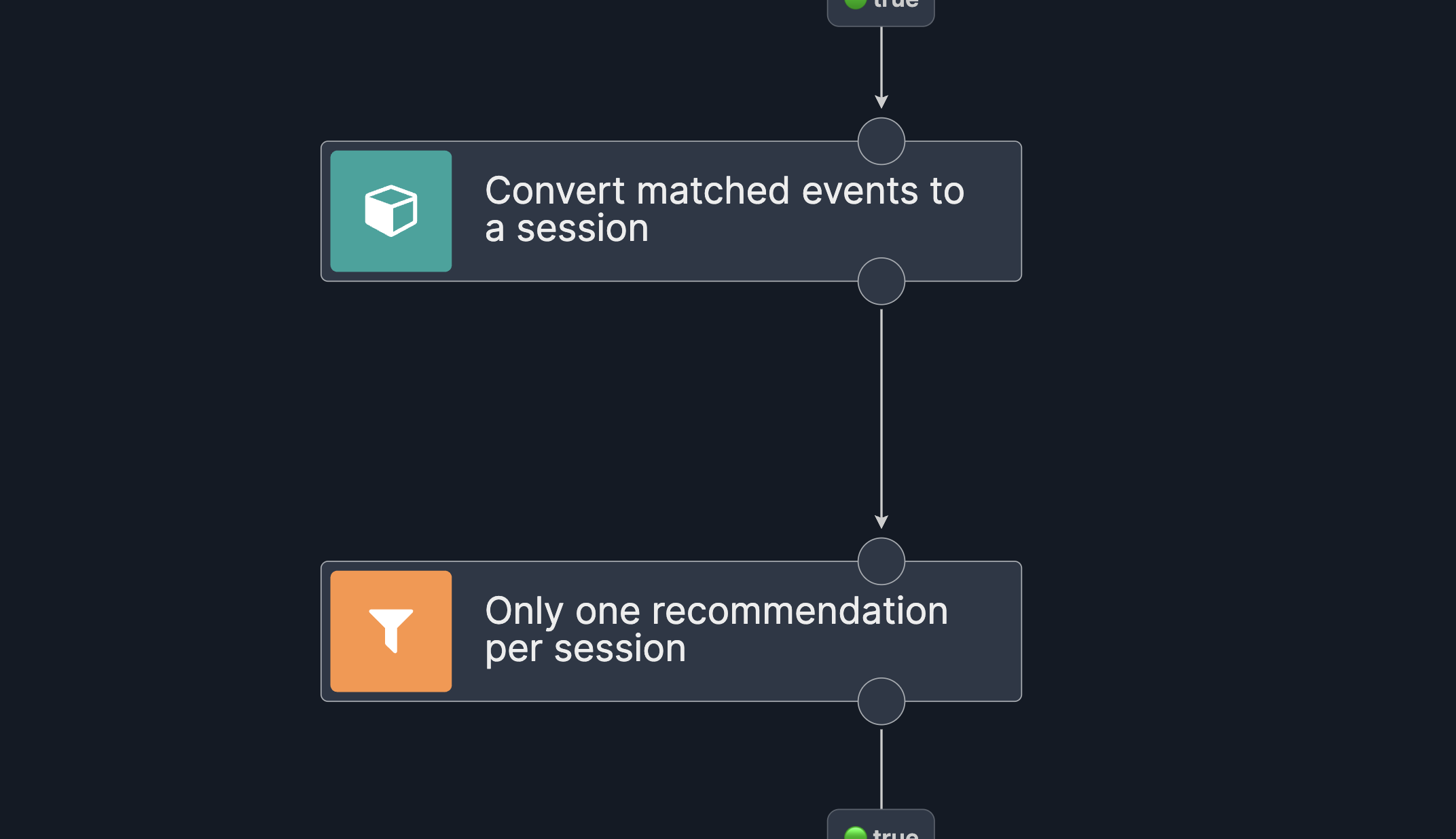
Grouping localisation events into shopping sessions
We don’t want either to spam our customers or call LLM on each incoming event (due to previously mentioned reasons). Instead, we can sessionize incoming location events into shopping sessions. All events for a specified key (e.g., customerId) will be put into the same session as long as there wasn’t a gap in events longer than the timeout.
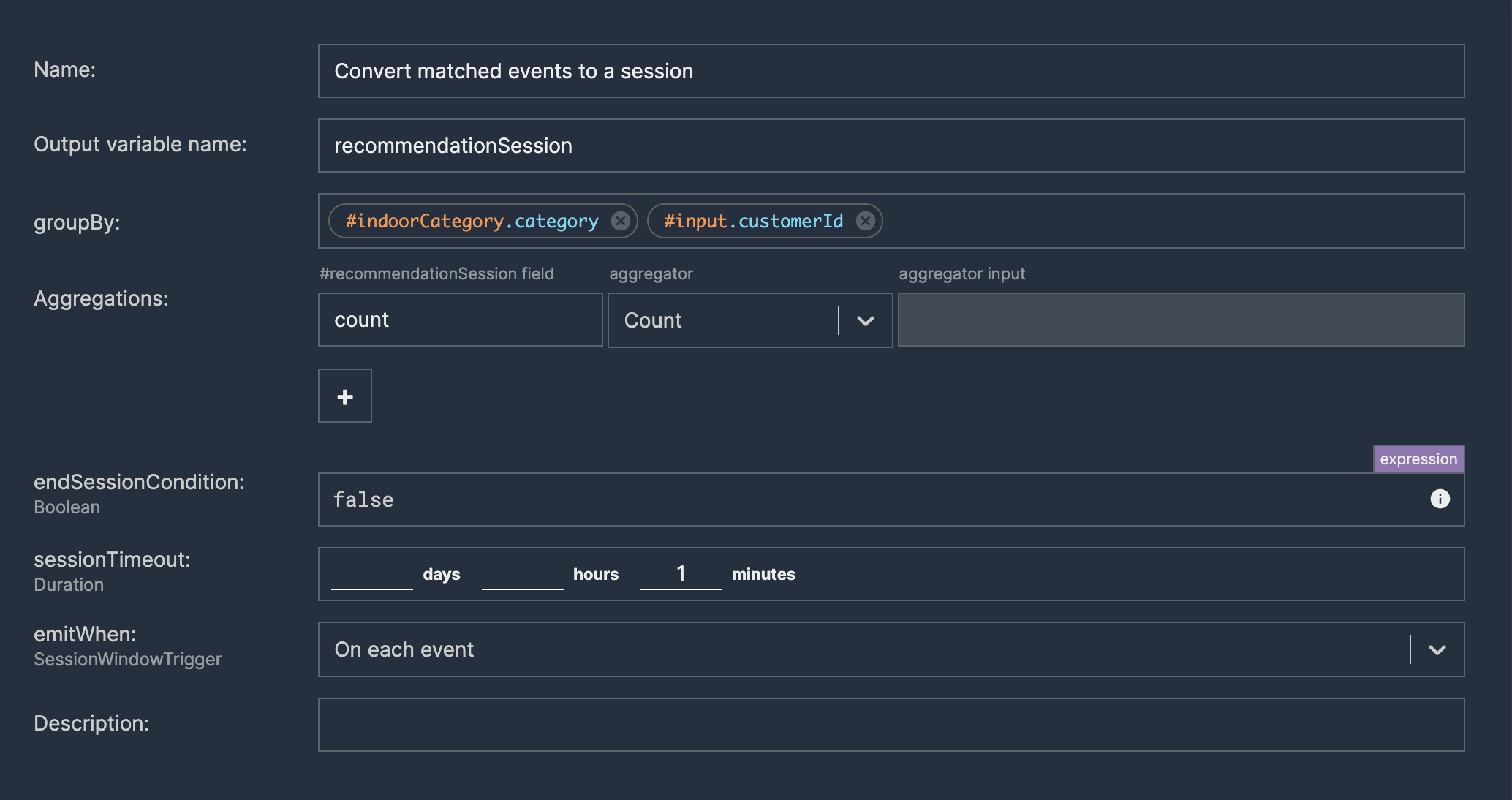
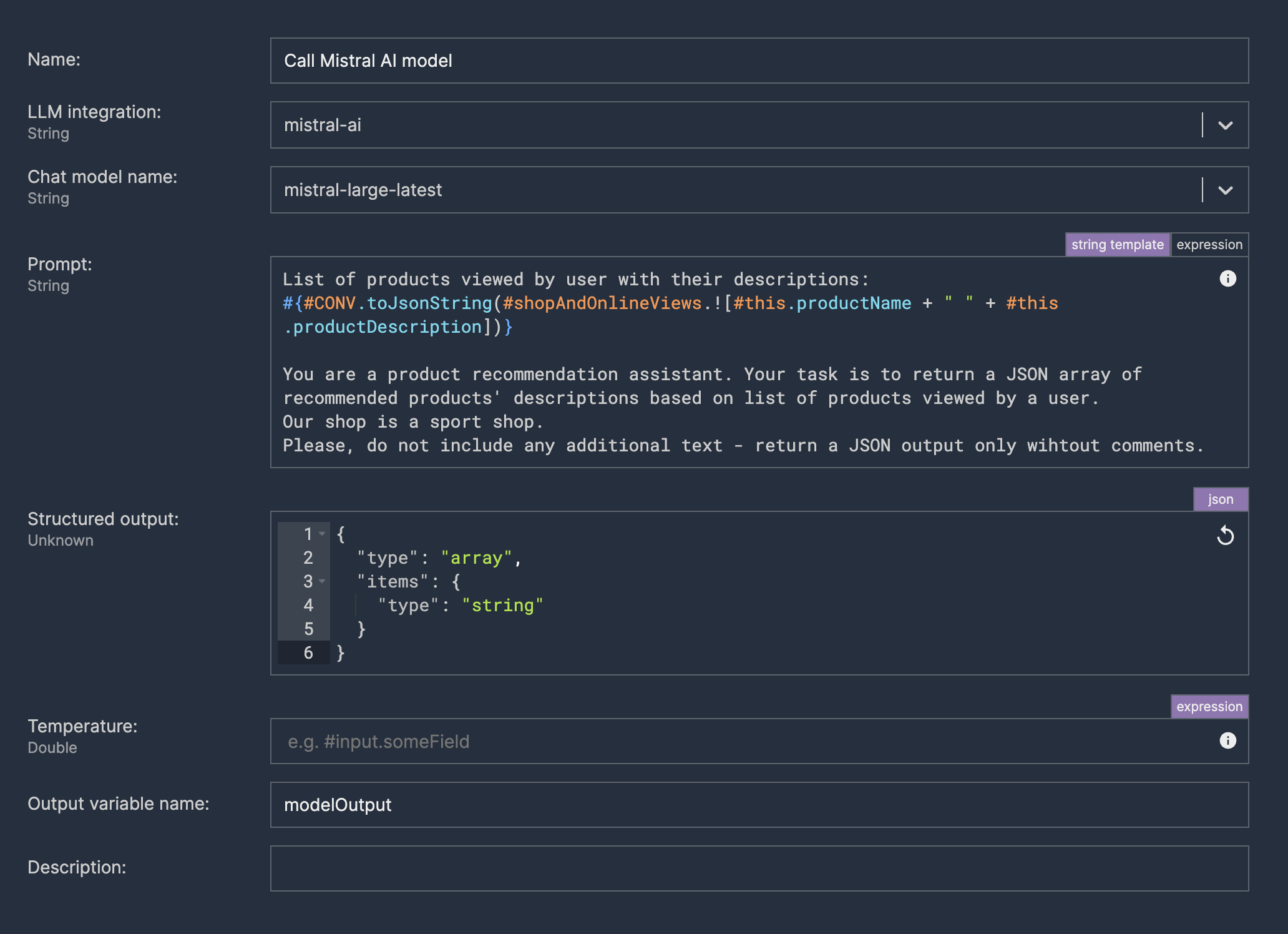
Invoking LLM chat
It is probably the most crucial part. Here, we have to select a model and create our prompt. We have to instruct LLM on what to do and give any context that might be helpful.
While creating a prompt, we can use expressions to inject any data that is available in the event context - in particular joined history of given customer products views in the e-commerce channel (clickstream).
This can be a trial-and-error journey, so we can export such invocation logic to a separate isolated part to speed up the feedback loop - e.g., to a separate fragment in Nussknacker.
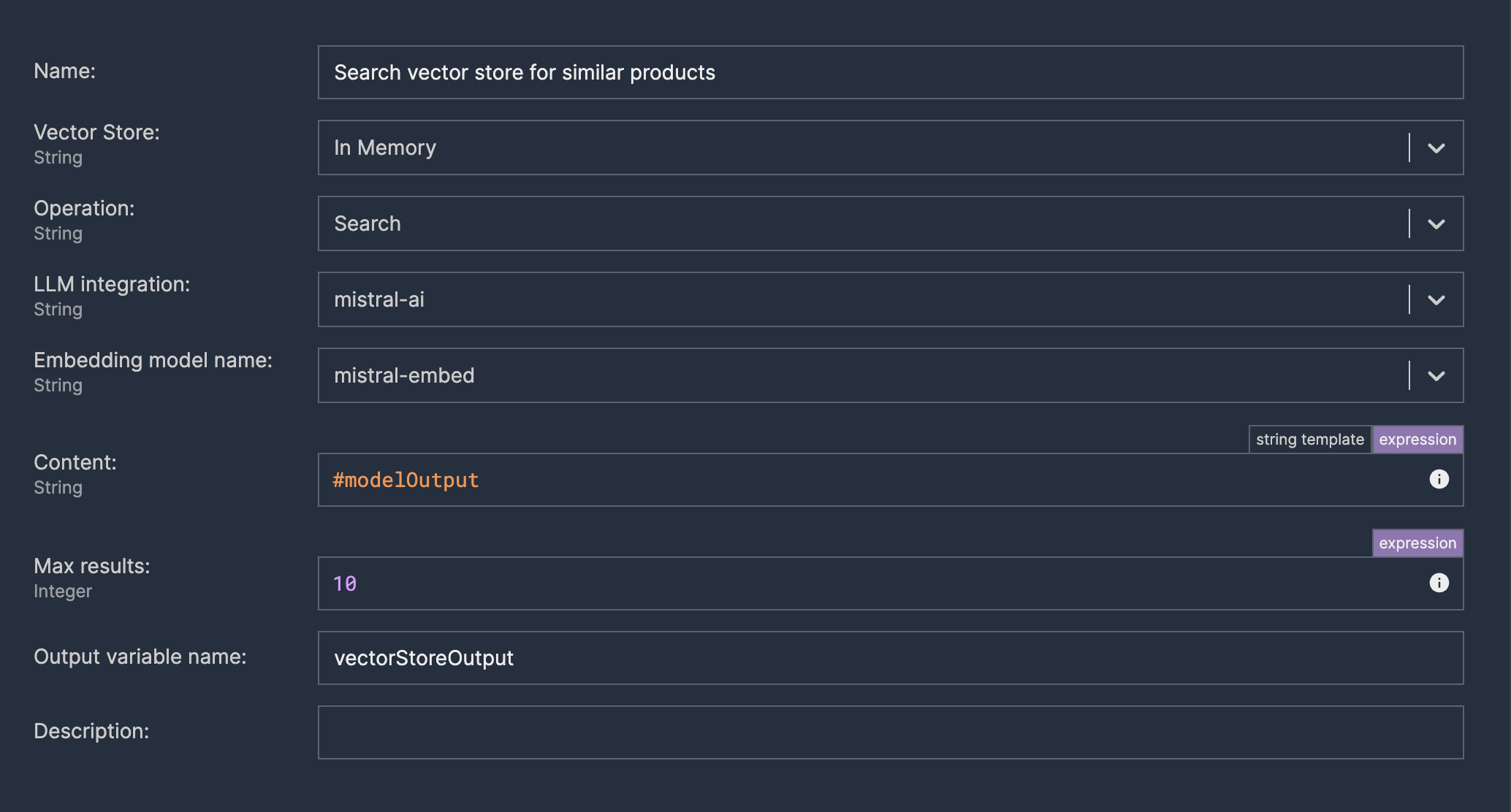
Searching a vector store
When we have an “imagined” ideal product description for a given customer based on e-commerce history, we can try to find the closest real product in our shop. To achieve this, we can use a vector store of our product descriptions.
We provide modelOutput as a Content field - text to be transformed into an embedding, which will be used to search the vector store.
Summary
The above example demonstrates that Cloud model providers like Mistral AI and OpenAI offer impressive opportunities to develop unique vertical solutions and tools on top of their general-purpose LLM models. Of course, we have to take care of prompt crafting and ensure that the LLM is not flooded with paid requests. No fancy prompt would also relieve you from measuring the impact of actions on customers, so A/B Testing and Impact Analysis still apply.
The presented LLM-first approach, where the order of augmentation with a vector store is inverted when compared to straight RAG, prevents running into any prompt size limitations. But more importantly, it allows for fitting the answer easily into a pre-defined set of items. And you wouldn’t want to recommend to anyone a trip to an island where no accommodation services exist or give an offer apparel that doesn't exist, would you?
And last but not least, with Nussknacker, you don’t have to be a Python guru to take advantage of these techniques. You can even support artificial intelligence with your natural one by combining machine learning models with rule-based domain knowledge.