A modern lakehouse helps teams move beyond raw storage in data lakes by structuring data for analysis and decision-making. While data warehouse keeps structured, analytics-ready data and data lake stores raw data for schema-on-read access and exploratory use cases, lakehouse combines these paradigms in one unified platform. Lakehouse built on table formats such as Apache Iceberg enables ACID transactions and schema evolution on low-cost object storage.
Medallion architecture is a popular design pattern for building a lakehouse by organising data into 3 layers: Bronze, Silver, and Gold. In this article, we show how you can leverage Nussknacker Cloud to implement this architecture on AWS S3 using Apache Iceberg and AWS Glue Catalog. You can check out the Nussknacker scenario in the live demo or follow along to build it yourself at Nussknacker Cloud.
Medallion architecture
The Medallion architecture is a way of structuring data in a lakehouse so that it becomes progressively cleaner, more reliable, and more valuable as it moves through the pipeline. It is built around three main layers:
- Bronze layer - the entry point of the data lake. It stores raw data exactly as ingested, often straight from streaming platforms or batch systems. The focus here is on completeness and fidelity rather than quality.
- Silver layer - the enriched, conformed layer. Data in Bronze is cleaned, validated, and enriched with relevant data (for example, dimension tables from relational databases). The Silver layer represents standardized data, ready to be used as a source for analysis by Data Scientists.
- Gold layer - the business-level layer. Data from the Silver layer is aggregated, summarized, or modeled to answer specific business questions. Gold datasets are typically consumed by BI tools or ML pipelines.

As with many architectural patterns, there are multiple interpretations of the specifics. The silver layer is sometimes limited to mostly light changes, not encompassing enrichments, but for the sake of simplicity, we’ll stick with the above definitions.
This layered approach brings much-needed order to a data lake. It’s simple, easy to understand, and supports built-in recovery - downstream tables can always be recreated from the data in the Bronze layer.
Lakehouse storage with AWS Glue and Iceberg
A lakehouse needs storage that can handle large volumes of diverse data - from raw event streams to curated analytics tables - without sacrificing scalability or cost efficiency. Traditional databases aren’t designed for this kind of workload, which is why most lakehouses rely on object storage such as Amazon S3. It provides durable, virtually unlimited storage at a low cost.
However, object storage is not enough. For a structured approach of a lakehouse, we’d preferably want some mechanism to discover and manage the structure of the datasets. For this purpose, AWS provides AWS Glue Catalog – a centralized metadata store that manages schemas and simplifies integrations with processing engines.
Still, even with a metadata store, we may miss some of the features of good old relational databases, like ACID transactions. This is where table formats come in. Apache Iceberg is an open table format that integrates with AWS S3 and Glue Catalog. It provides not only ACID operations, but also other amazing features, such as schema evolution, partition evolution, or even time travel.
Sales analytics example
Let’s see how medallion architecture can be used to solve a specific problem. Suppose we are building a data pipeline for a retail store. We have two data sources:
- Continuous stream of sales events, each representing a sale with the following fields:
- price
- sale_time
- product_id – id referencing a product in the database
- Static data table containing product data with the following columns:
- product_id
- product_name
- product_category
Even for this simple data model, we can gain some insights by building a dataset containing aggregated sales metrics like sum, average, and count of all sales for every product category in a time window – for example, every hour. This would be business-level data that could be displayed on a BI dashboard and serve as a basis for business decisions. In a real-world scenario, we’d have more data points to build business insights, and they would be much more valuable, but for this scenario, let’s keep it simple.

It makes sense to publish the sales events to a streaming queue, since we can produce and process these events continuously. Product data could be placed in a relational database like PostgreSQL.
For our data lakehouse, we’d like to store the sales events as raw data in an Iceberg table as part of the Bronze layer. For each sales event, we can query the database in order to enrich it and store it in the Silver layer. After that, we can aggregate the enriched events by applying sum, average aggregate functions to price data, group by product category, and apply a 1-hour time window.
You've probably noticed the shift to more technical streaming terms like enrichment, aggregation, and time windows. This is the point where simple data processing isn't enough – the requirements demand a dedicated streaming engine like Apache Flink to manage the complexity and continuous flow. However, integrating Flink with modern table formats like Iceberg involves significant upfront costs in the form of initial configuration and management of the technical dependencies. Nussknacker Cloud effectively abstracts these details, making the deployment process simple and effortless.
Nussknacker Cloud Setup
This section is optional. Its goal is to show how to set up external services and configure a Nussknacker Cloud instance so that you can fully reproduce the scenario on your own.
Nussknacker Cloud leverages Flink to enable stateful operations, like aggregations on your data. Out of the box, it provides components for operating on data, but Sources (components for pulling data into a scenario) and Sinks (components for outputting data from a scenario) generally rely on Integrations. Integrations are available as a tab in the Nussknacker Cloud Admin Panel. When you add an integration, Nussknacker Cloud will automatically add the associated components to the palette in your Nussknacker instance.
For our scenario, we need to integrate with 2 external systems:
- Relational Database integration, like PostgreSQL, for our static products data
- AWS Glue integration for storing output data, serving as a lakehouse
PostgreSQL integration for enrichment
PostgreSQL integration requires the database to be publicly reachable and secured with a password. If you don’t already have one, you can use some free-tier managed PostgreSQL, for example, the one available at Aiven Platform.
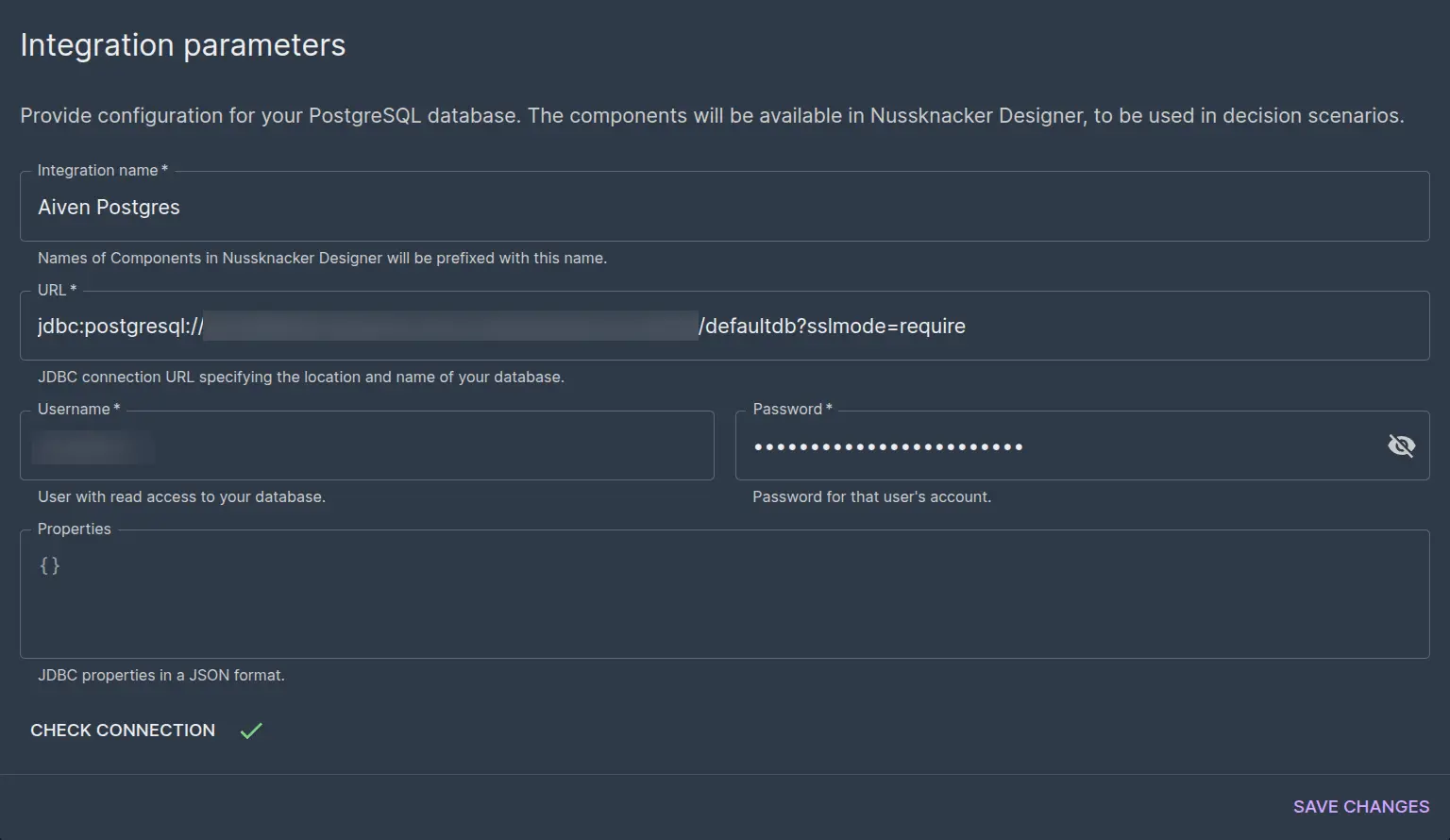
After you save the Postgres integration, your Nussknacker instance should have 5 components prefixed with your integration name. The component we will be using for enrichment is the Lookup component.
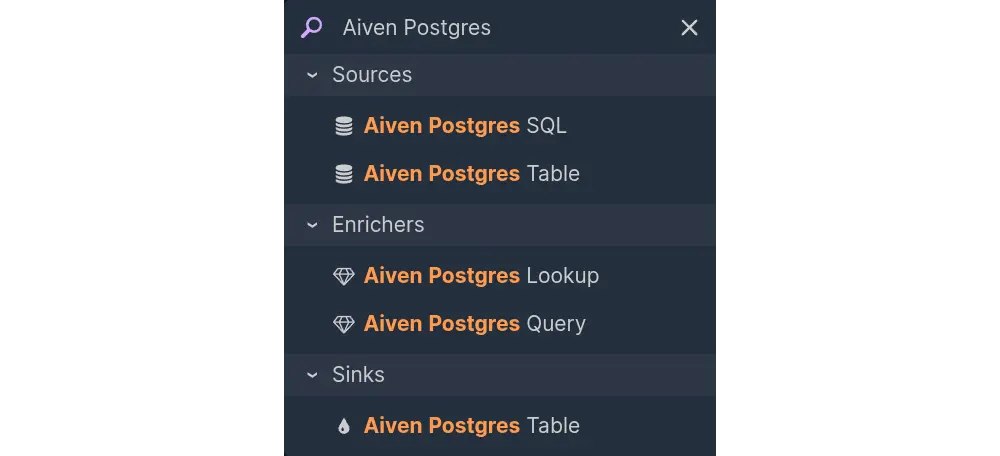
The component only sees the existing tables, so before we use it, we need to create a products table and populate it. To do that, connect to your database with psql or some database admin tool like DBeaver or pgAdmin and execute the following statements.
AWS Glue integration for Iceberg lakehouse storage
AWS Glue integration allows reading from and writing to Iceberg tables registered in AWS Glue and stored in S3. An Iceberg table is essentially a dataset in an Iceberg format. This format consists of a data folder, which stores the actual data in Parquet, Avro, or ORC format, and a metadata folder, which stores data about schemas, snapshots, and partitions. The metadata layer is what enables such unique features as time travel or tracking schema evolution.
Besides the Iceberg format, the architecture of this whole integration may seem confusing, but it comes down to 4 parts:
- S3 – stores data in Iceberg format
- Glue – tracks Iceberg tables, allows for discovery
- Lake Formation – governs access for Glue and S3 (controls what data users can query inside the lake)
- IAM – authenticates users

The integration connects to Iceberg tables governed by Lake Formation and Glue. For this, AWS Lake Formation documentation on creating Iceberg Tables may be useful. For these tables to be available in Nussknacker, they need to have a schema, and they need to be accessible by an AWS IAM user.
For our scenario, we will need to create 3 Iceberg tables:
| Table name | Schema |
| sales_raw |
[
{ "Name": "sale_time", "Type": "timestamp" },
{ "Name": "product_id", "Type": "string" },
{ "Name": "price", "Type": "decimal(10,2)" }
]
|
| sales_enriched |
[
{ "Name": "sale_time", "Type": "timestamp" },
{ "Name": "product_id", "Type": "string" },
{ "Name": "price", "Type": "decimal(10,2)" },
{ "Name": "product_name", "Type": "string" },
{ "Name": "product_category", "Type": "string" }
]
|
| sales_aggregated |
[
{ "Name": "product_category", "Type": "string" },
{ "Name": "total_sales", "Type": "decimal(10,2)" },
{ "Name": "avg_price", "Type": "decimal(10,2)" },
{ "Name": "sales_count", "Type": "bigint" },
{ "Name": "window_start", "Type": "timestamp" },
{ "Name": "window_end", "Type": "timestamp" }
]
|
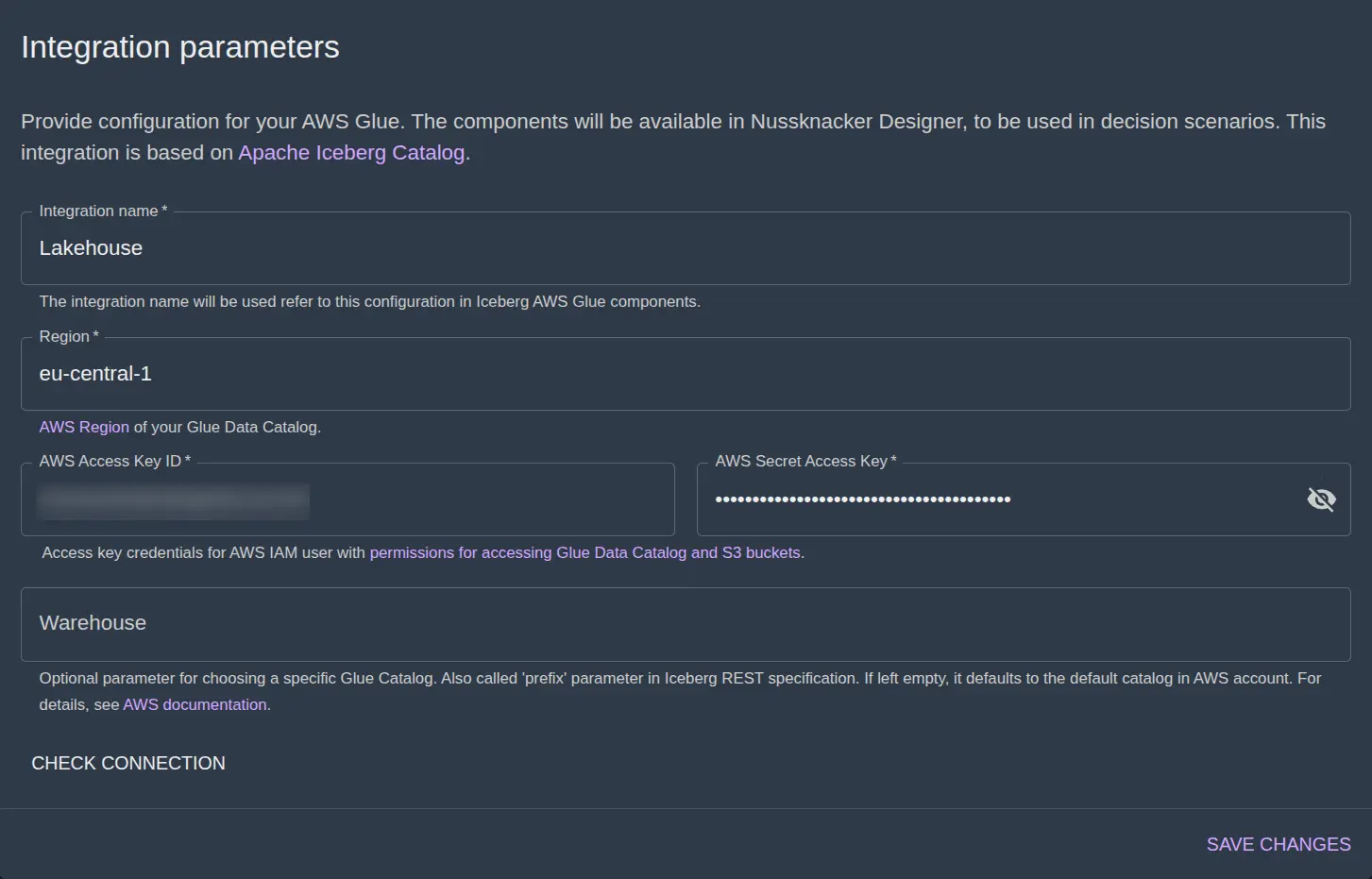
In Nussknacker Cloud Admin Panel in the AWS Glue integration creation form, you will also need to pass Access Key credentials for an IAM user with necessary permissions. You can view them by clicking in the link in text under the credential fields in the form. After you save the AWS Glue integration, your Nussknacker instance should have 2 components prefixed with your integration name.
Nussknacker Scenario
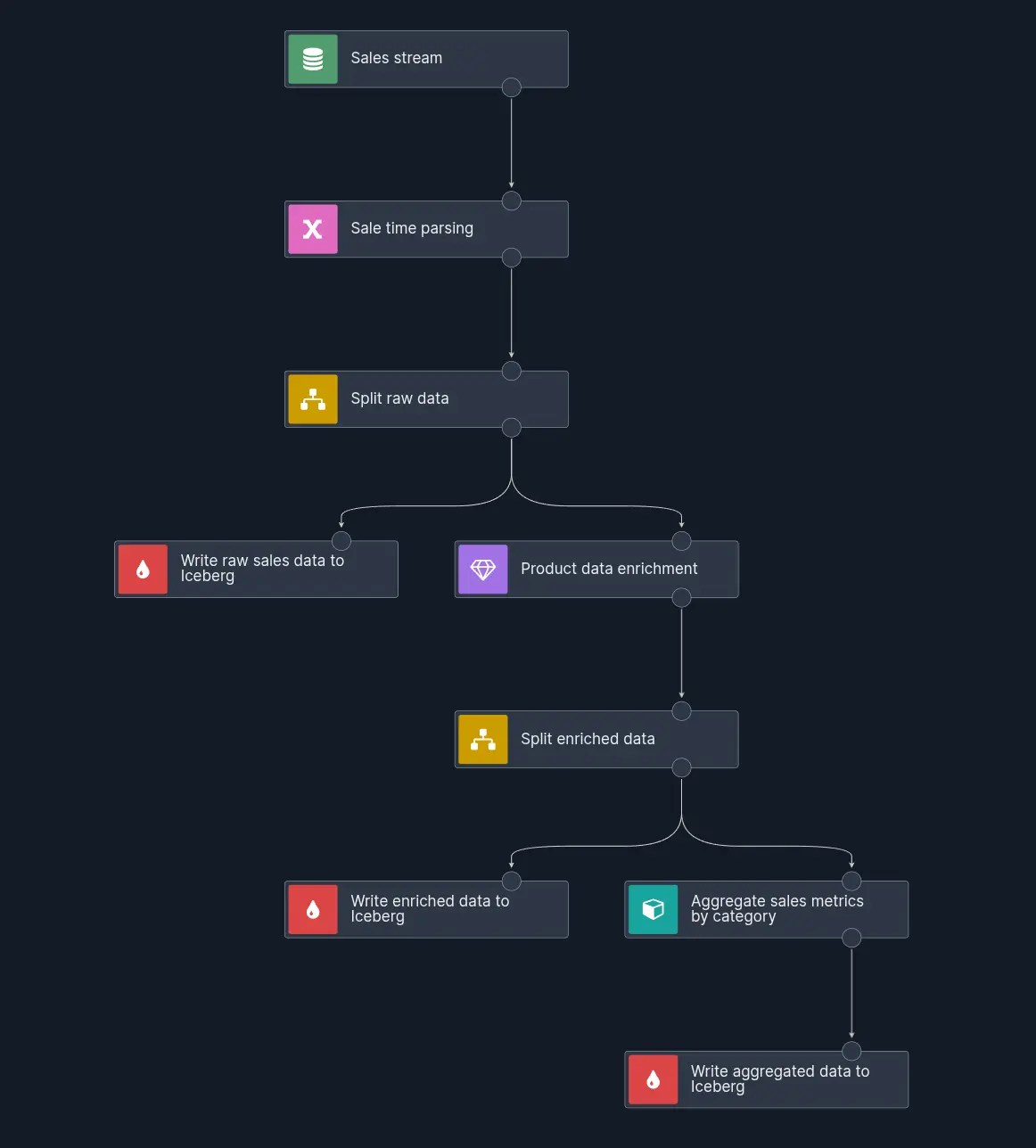
After we’ve set up all required integrations, let’s build the scenario. It’s mostly going to mirror the architecture diagram from before:
- HTTP Endpoint source for continuously ingesting sales events
- Iceberg Sink for writing bronze layer raw sales records to Iceberg
- Postgres lookup enricher for getting product data
- Iceberg Sink for writing silver layer enriched sales records to Iceberg
- Aggregate component for stateful computation of real-time sales metrics
- Iceberg Sink for writing gold layer sales aggregates to Iceberg
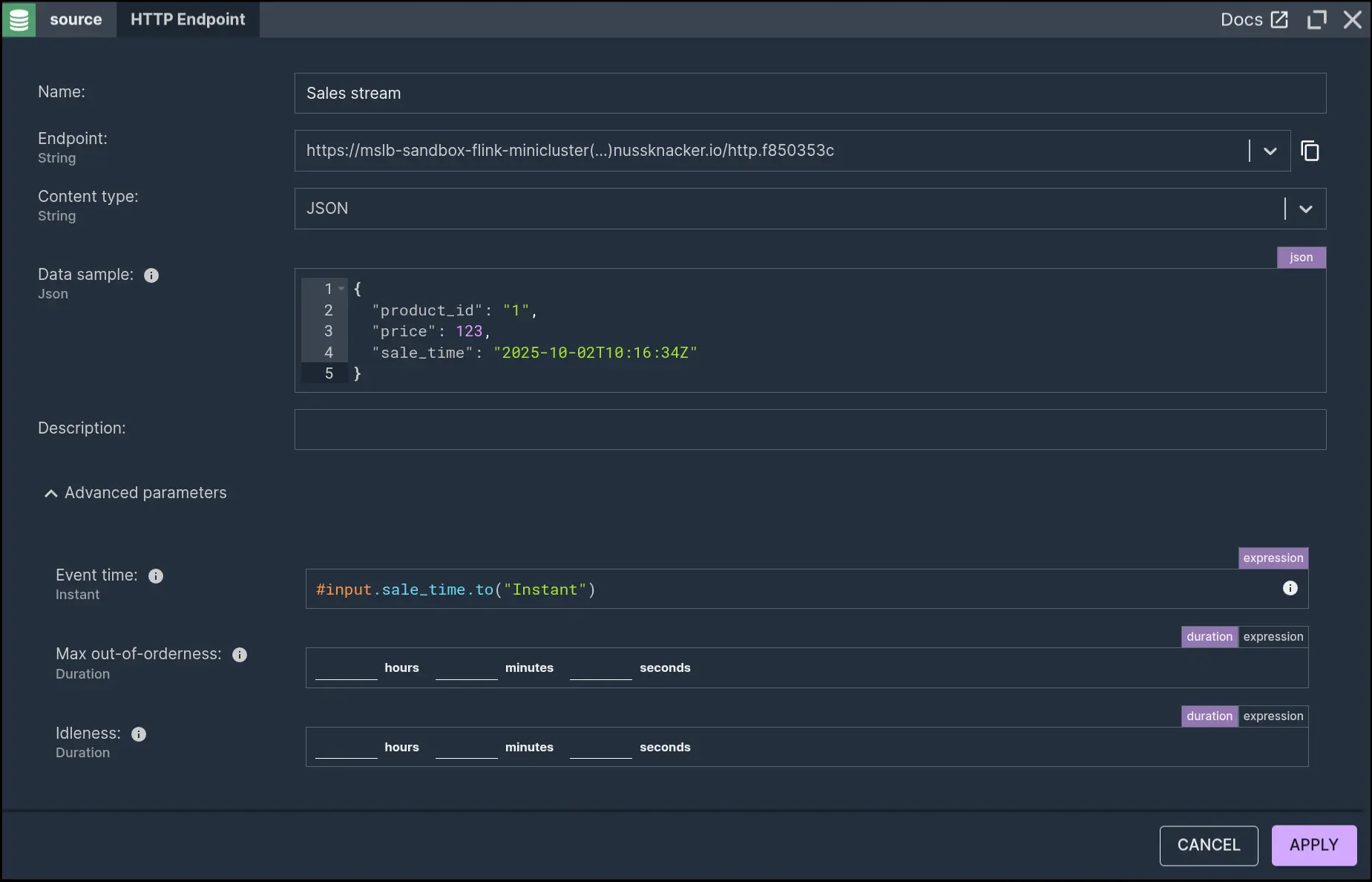
 Ingesting a stream of events over HTTP
Ingesting a stream of events over HTTP
The HTTP Endpoint component allows for continuous ingestion of events sent to an HTTP endpoint. The body of each POST request sent to a given endpoint will be ingested as an event in the scenario downstream. JSON in the data sample parameter will make referring to event fields easier by enabling suggestions in expressions. For purposes of later aggregation, event time is taken from the 'sale_time' field. For a more comprehensive exploration of event time, check out Arek Burdach's Understanding Event Time blog.
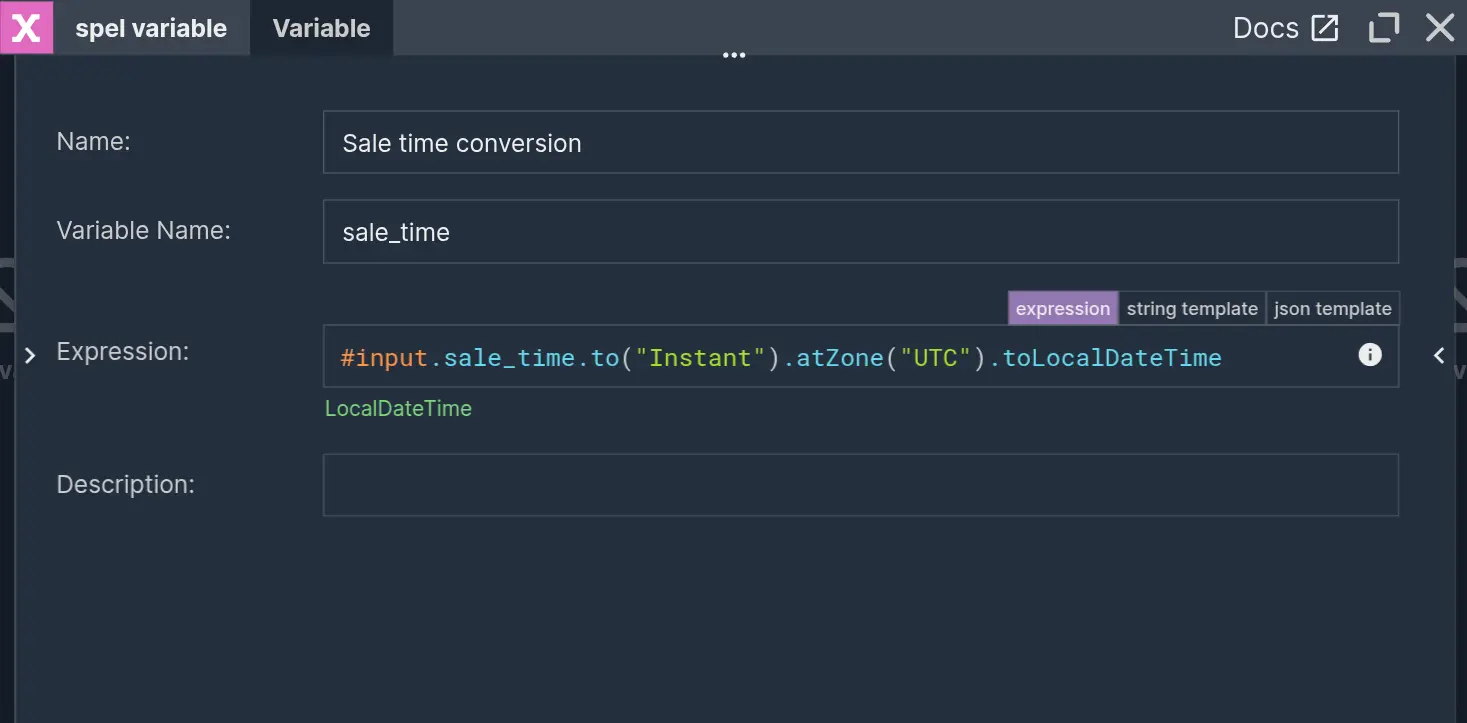
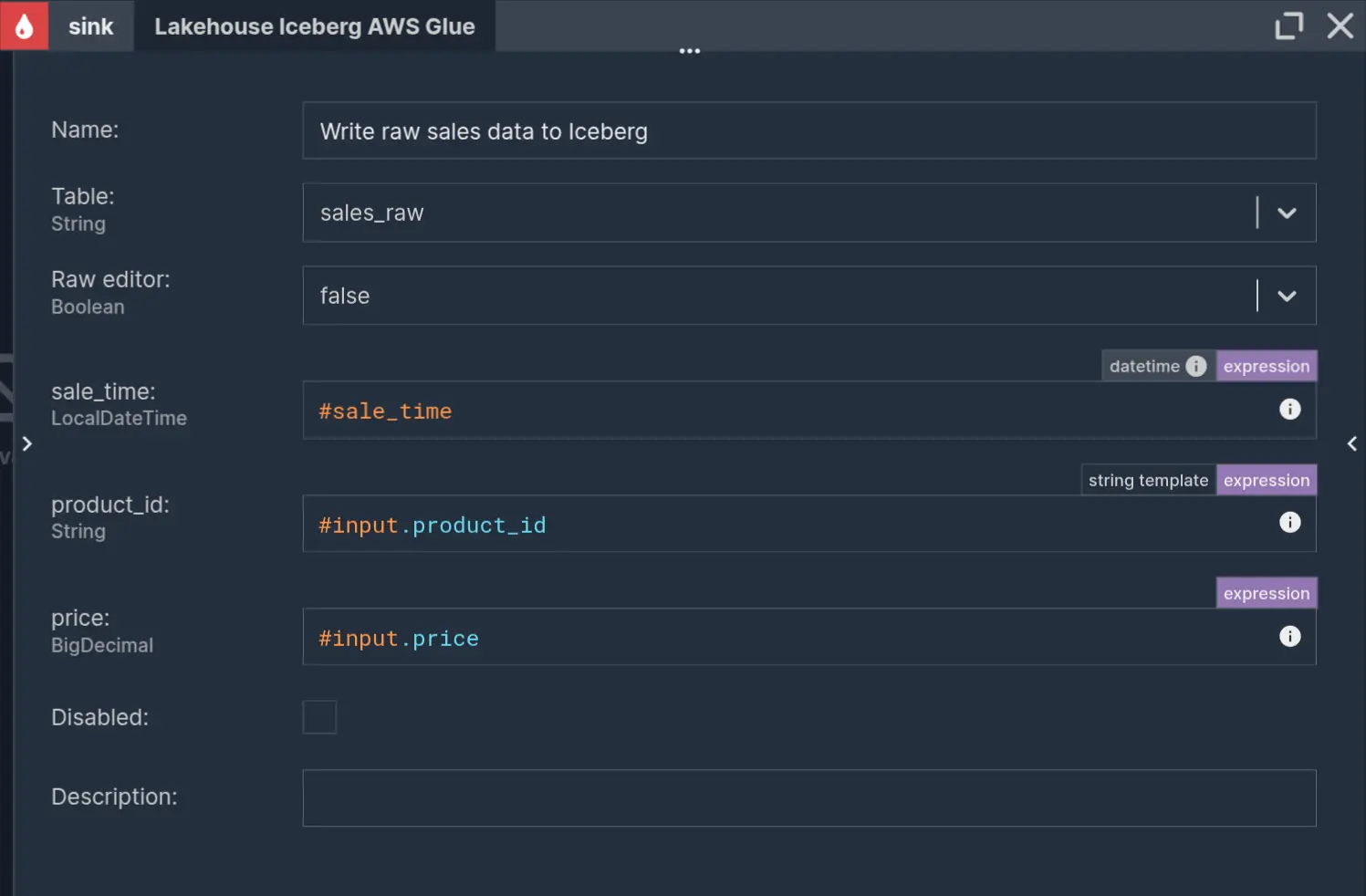
Writing data to Iceberg
This raw stream of sales events will be written to Iceberg as Bronze layer data. The schema of Iceberg tables expects a 'LocalDateTime' event time type. Nussknacker doesn’t automatically recognize the 'sale_time' from the incoming request JSON body as a date type, so it has to be explicitly processed. Data validation, cleaning, and parsing, such as in this situation, can be done in a separate Variable node. This will allow later reuse of this value in other downstream nodes.
Enrichment from Database
For further processing, the stream can be split into parallelly processed branches using the Split component to process it further into Silver and Gold layers. Nussknacker provides multiple enrichment integrations. If you have an HTTP service you want to use for enrichment, you can use OpenAPI integration. For that, check out Maciek Cichanowicz’s blog “A guide to OpenAPI components”. For the current scenario, a database lookup enricher will be fitting. Lookup component based on the previously configured Postgres integration can be used to enrich sales events with product data.
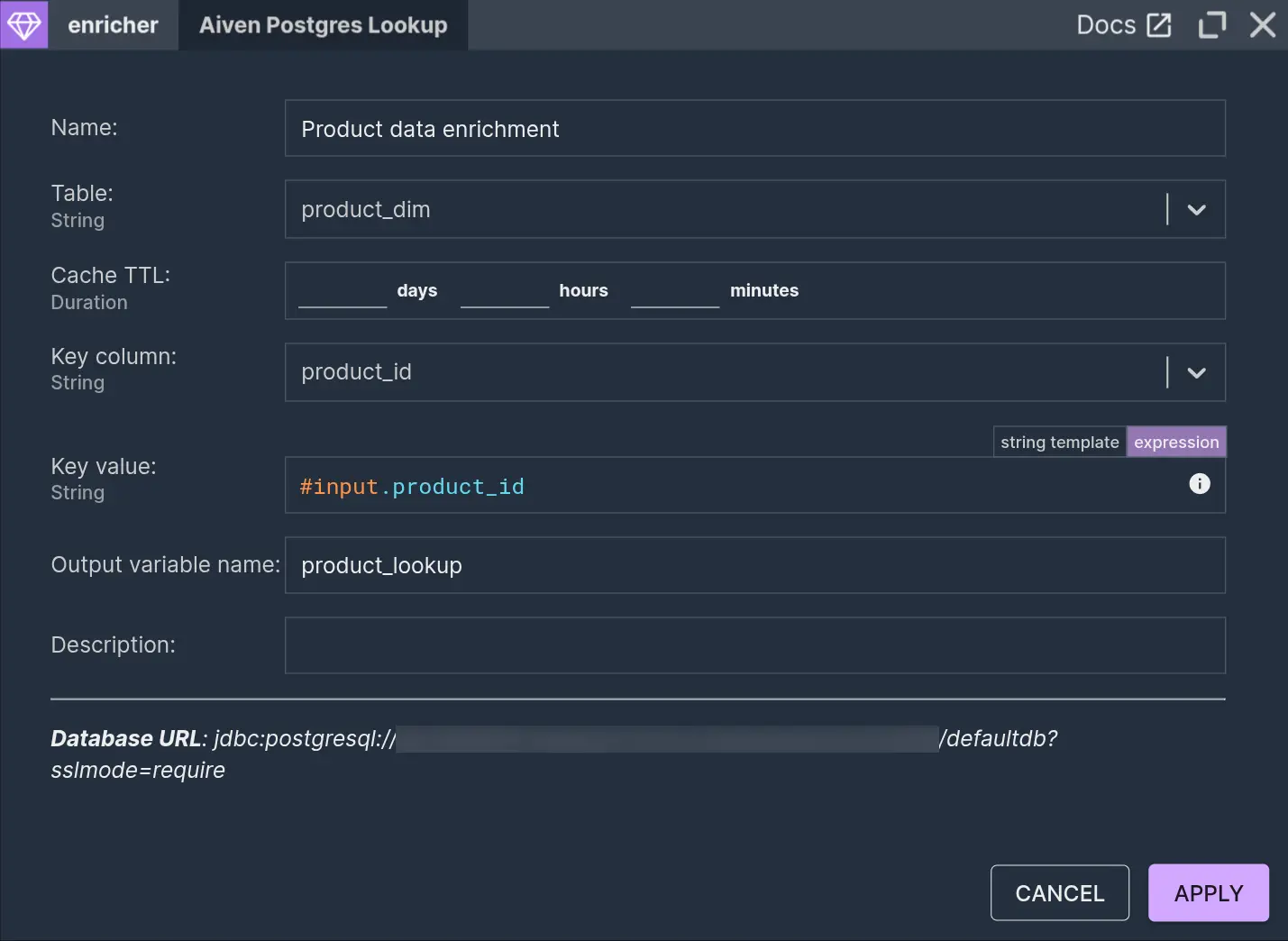
The table created and populated in that previous section should be available in the ‘Table’ parameter. This node looks up a record from the table based on the ‘product_id’ field in the incoming event and adds it to the stream. The record is then available under the ‘product_lookup’ output variable, which can be referenced downstream.
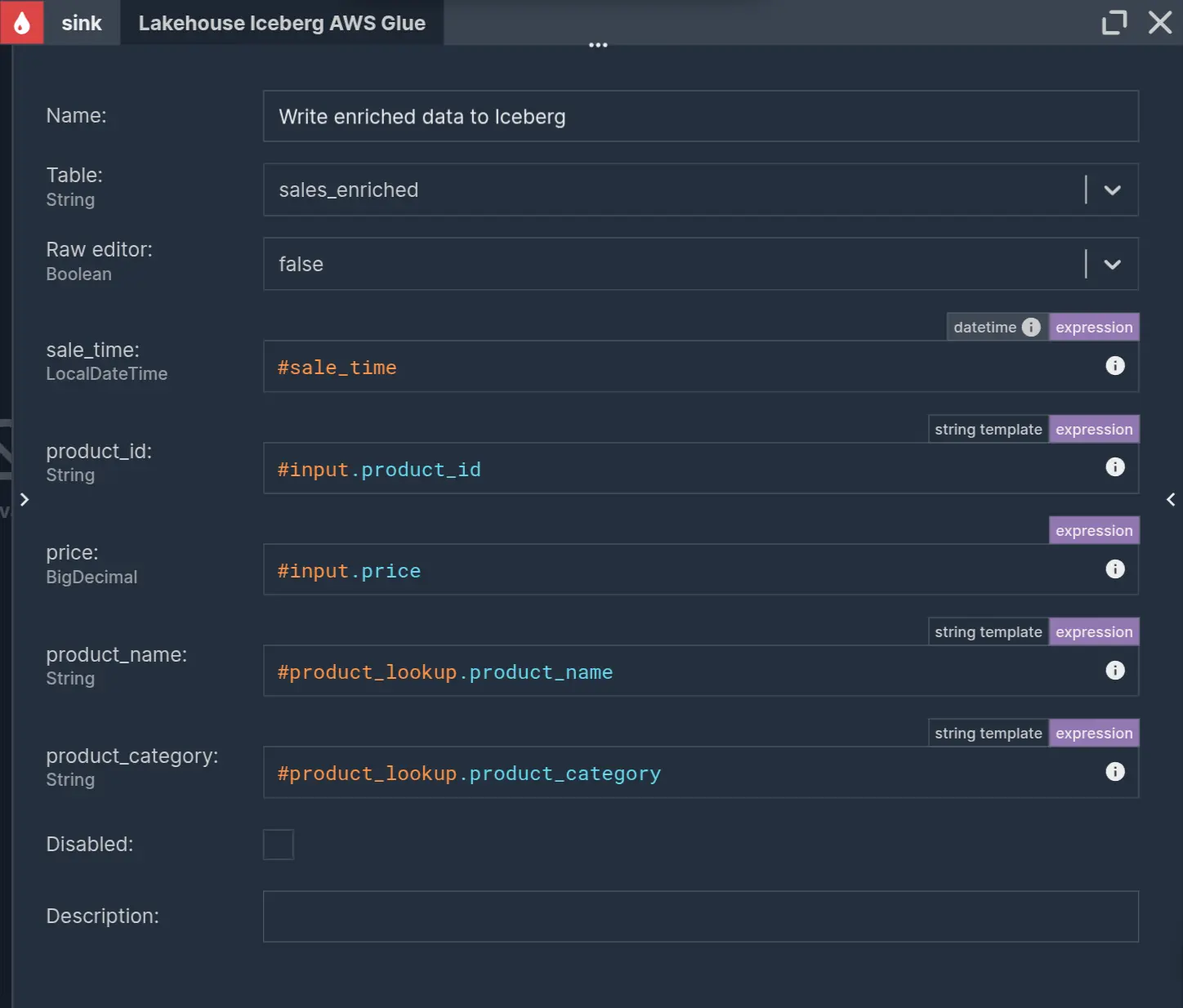
Going along with the medallion architecture, enriched records can be written to Iceberg as part of the Silver layer.
Aggregating sales metrics
An aggregate component is essential for turning the enriched sales stream into actionable metrics. Usually, extracting valuable insight from continuous, real-time streams requires taking into account the time aspect. Fortunately, Nussknacker excels in this area.
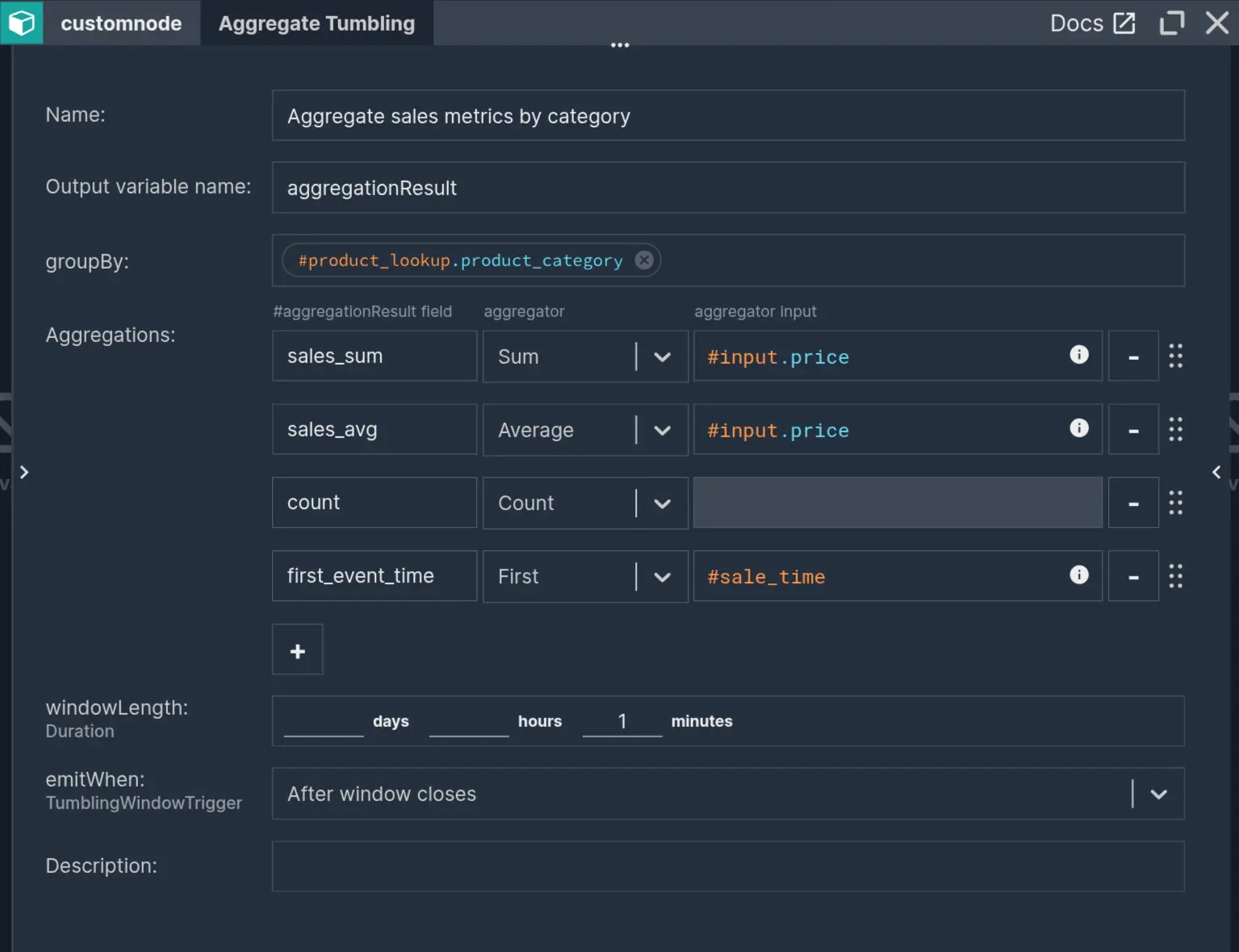
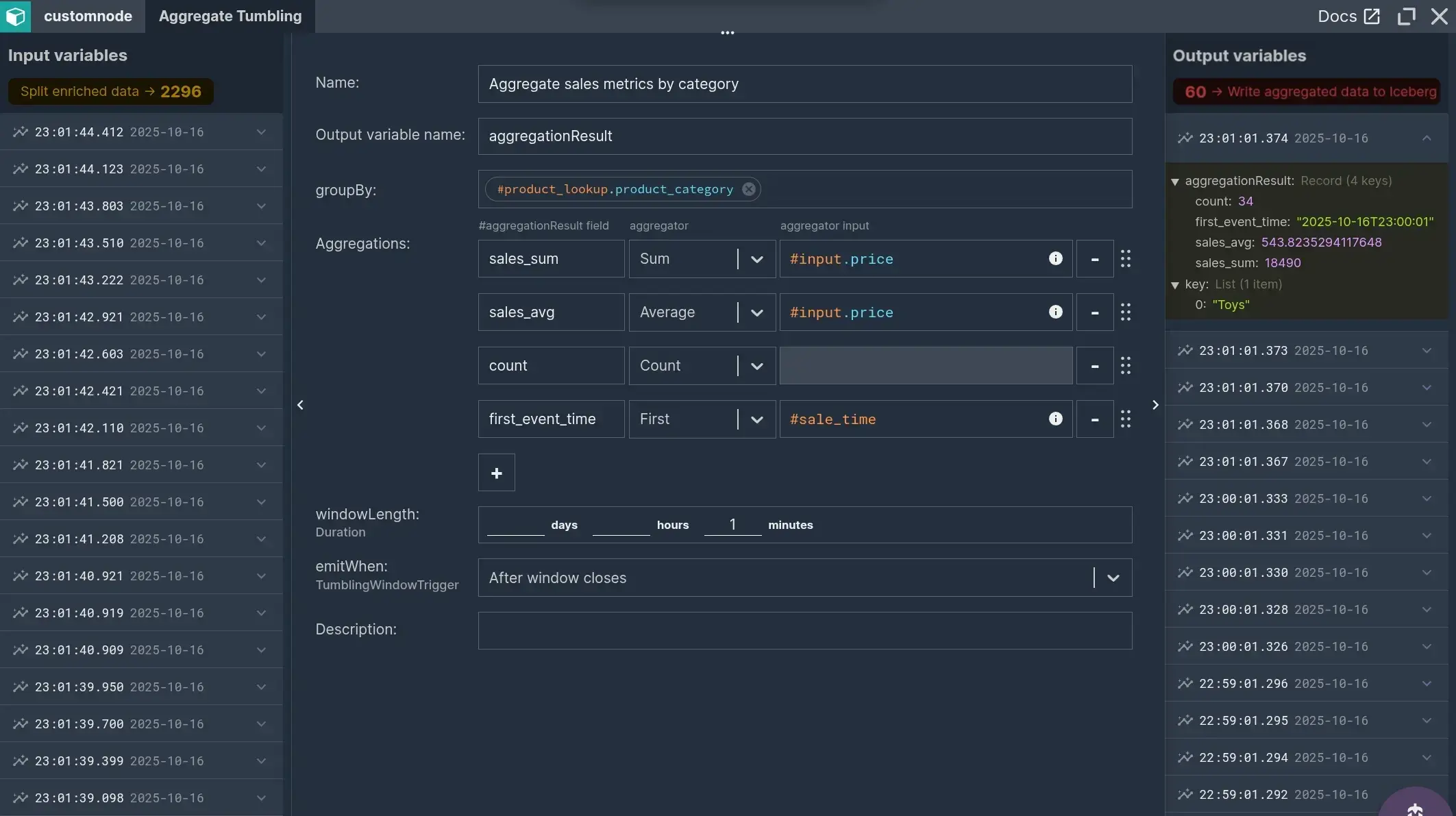
The ‘Aggregate Tumbling’ component performs aggregation in time windows that don’t occur one after another with no overlap. The windows are aligned to full time units. In configuration as visible on the image with the 1-minute window length, each window begins at the 0th second of each minute and ends at the end of each minute.
Within each window, the records are grouped by ‘product_category’. Within each group, we take:
- sum of prices,
- average of prices,
- count of all events,
- first sale time.
The aggregation emits the result for each window after it closes.
All that’s left is to write this data to Iceberg into the ‘sales_aggregated’ table.
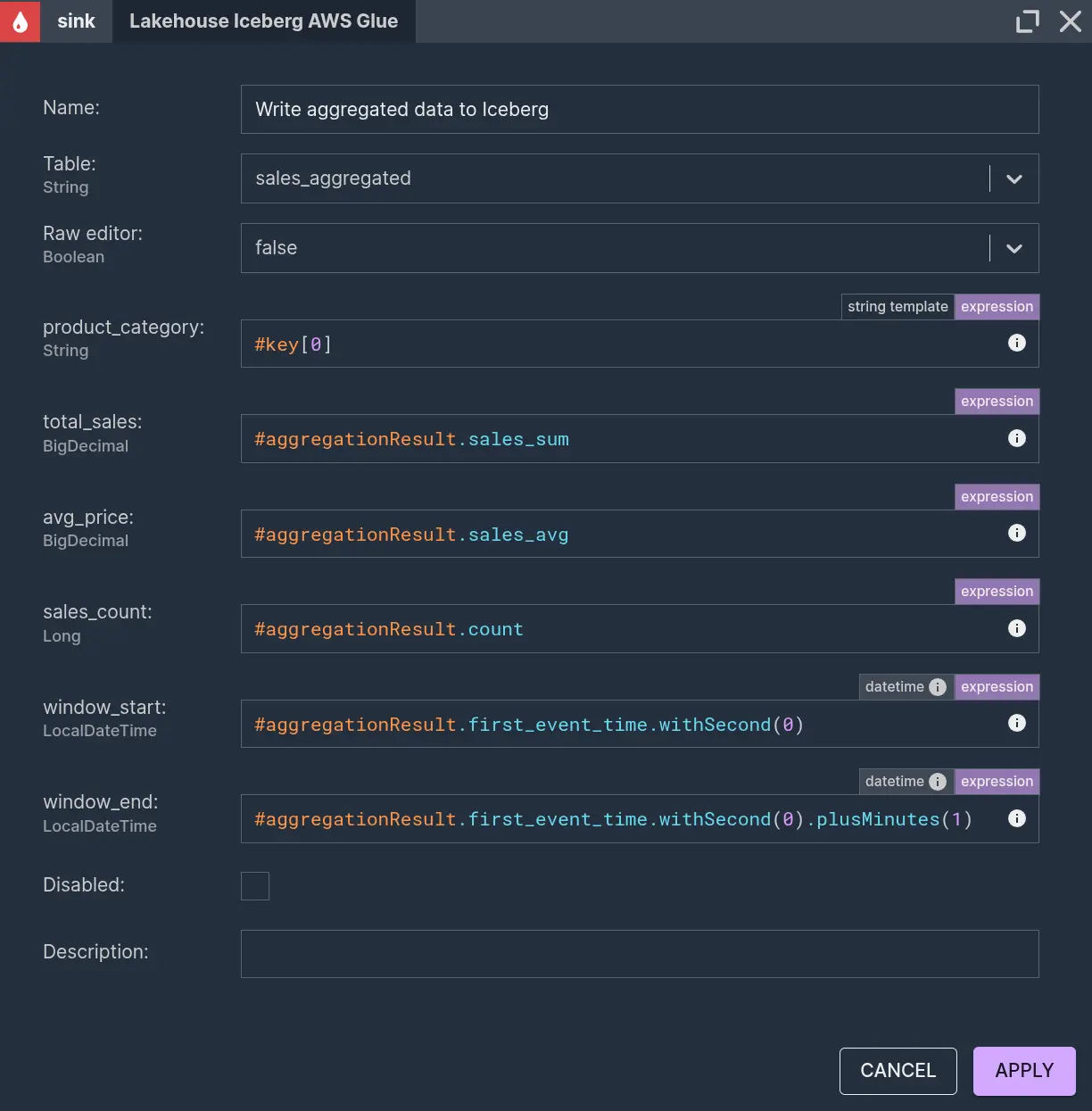
The key variable is the list of values given in the ‘groupBy’ parameter in the aggregation node. In our case, it's a one-element list, where this element is the product category, so it can be accessed through the 0’th index. The window start and end time can be easily calculated, knowing that windows are aligned to full minutes and remembering that our window length is 1 minute.
Scenario deployment and checking the results in Athena
Let’s deploy the scenario and observe the flow. After deploying the scenario, we’ll launch a script to generate and send data continuously to the source endpoint.
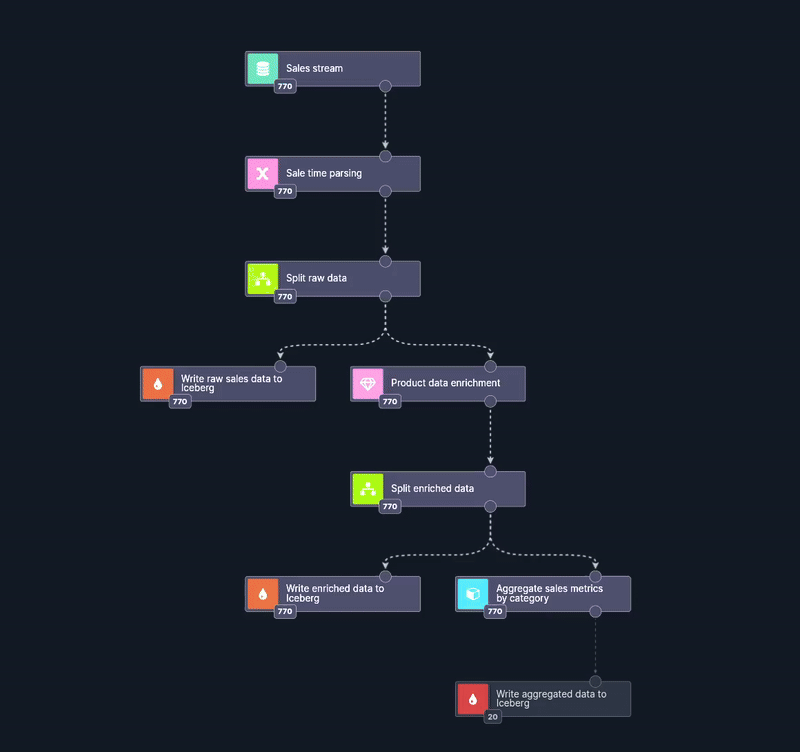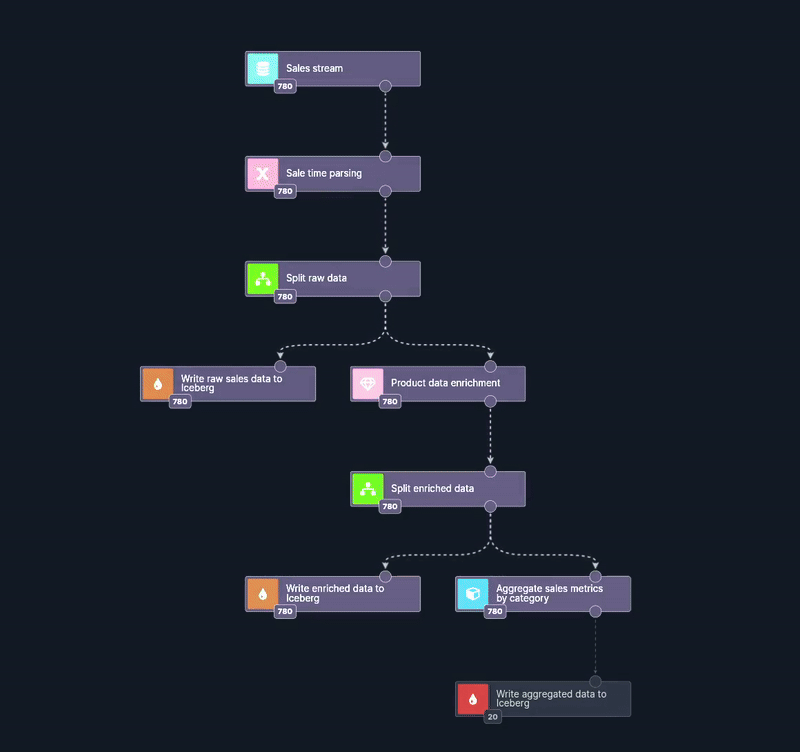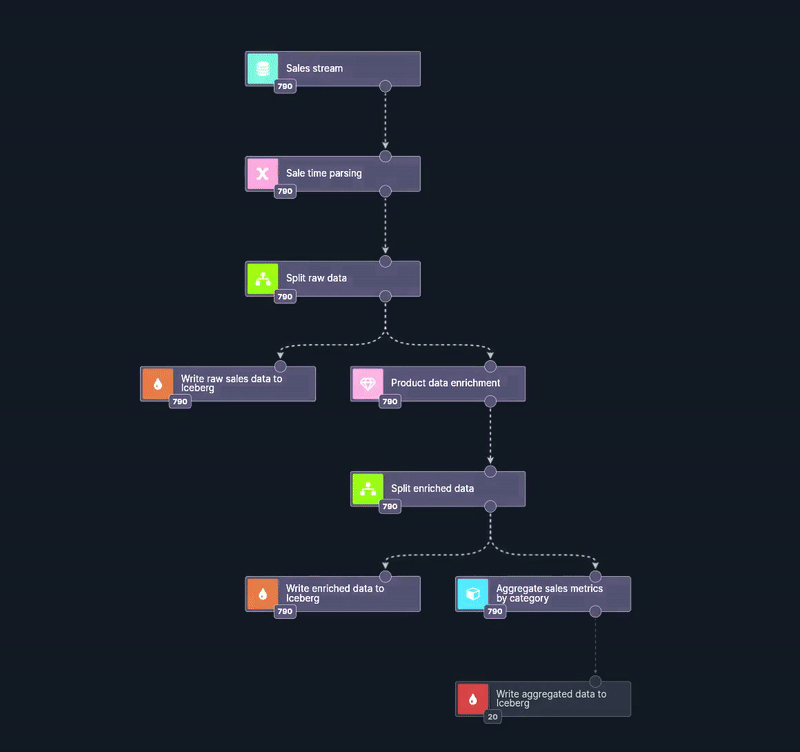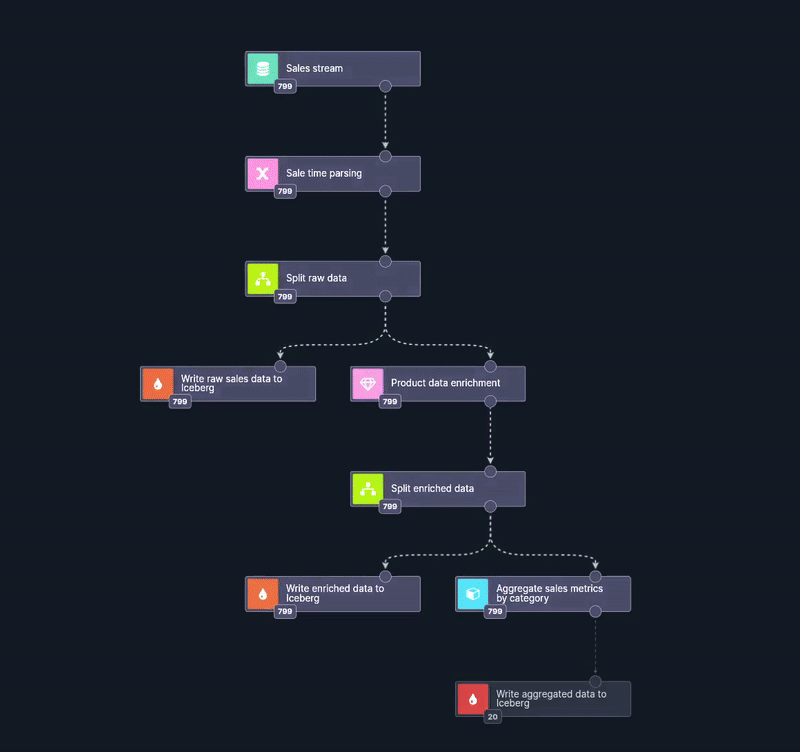
The event flow is visible in real time. Each event can be inspected in detail when entering any node.
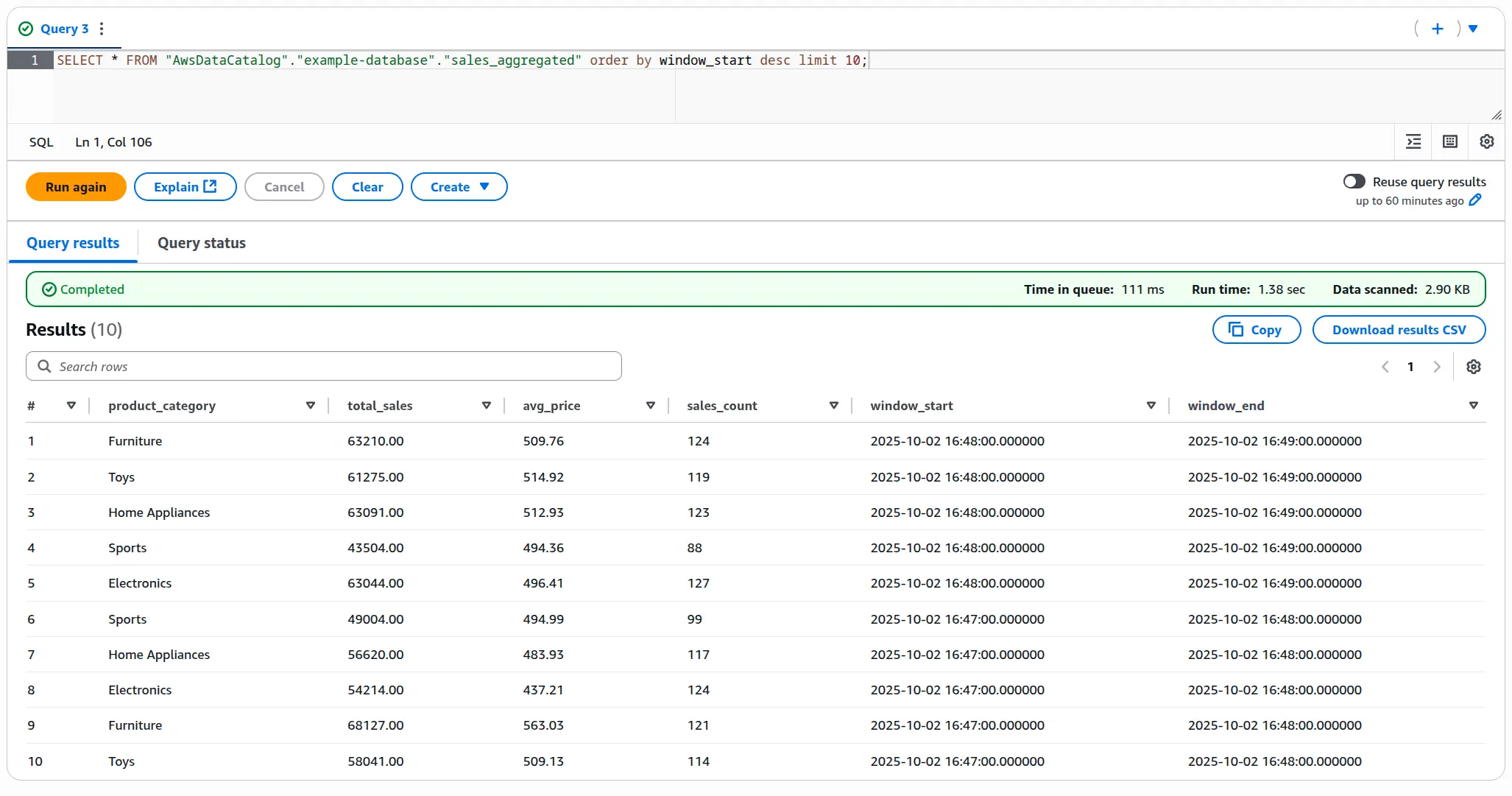
The data written to Glue Iceberg tables can be previewed in Athena or displayed in BI tools.
For further processing, you can also ingest these tables and process them further in Nussknacker using the ‘Iceberg AWS Glue’ Source component based on the Glue integration.
Summary
Using Nussknacker Cloud with AWS Glue and Iceberg, we built a real-time pipeline that ingests, enriches, and aggregates streaming sales data directly into a lakehouse. Each operation - from data parsing and cleaning, through database enrichment, to stateful aggregation and Iceberg writes - is represented as an intuitive, configurable node.
Nussknacker models pipelines visually, focusing on data flow and transformations rather than syntax. Everything happens without a single line of code, and with built-in testing and live event inspection, mistakes are easy to spot and fix instantly. You can watch data move through the pipeline in real time, making development faster, clearer, and more interactive.
It’s streaming analytics without the complexity - turning what used to take days of coding into minutes of visual design, with Iceberg ensuring every result is stored reliably, versioned, and ready for time-travel queries.