Mobile carriers face credit risk when customers buy phones in installments, and a fraud risk from those who sign contracts with no intent to pay.
To mitigate these risks, companies rely on credit scoring to assess customers’ creditworthiness. Higher credit scores allow customers to purchase more expensive handsets or multiple services, while lower scores may limit them to basic services without a handset.
Such credit scoring systems are usually underpinned by ML models that help them calculate credit scores by analyzing a wide range of input variables, from basic demographic data such as age to detailed credit histories fetched from external sources. However, these credit models must evolve to take into consideration changing customer behaviour and business requirements. This requires frequent updates and retraining.
This is where Nussknacker has proven invaluable in integrating ML models. Its true power comes when it is used not only to infer ML models, but also to enable end-to-end decision automation. This includes decisions such as verifying customer identity or assessing eligibility for additional products.
We’ll explore here how integrating Nussknacker transformed the credit scoring system of Play, a Polish telecom company, with 13 million active users, enabling greater agility, automation, and efficiency.
The challenges of the credit scoring system
Before we introduced Nussknacker, the system faced several challenges:
- Scoring model integration
The credit scoring model was a component of a fairly monolithic scoring application, making updates complex. Each update required developer intervention, which slowed down model iteration, adaptation and deployment to the production environment. Moreover, model preprocessing and postprocessing logic was also embedded in the system. Whenever changes were needed, we faced similar problems to updating the model itself. The image below illustrates how the scoring model was integrated before we introduced Nussknacker:
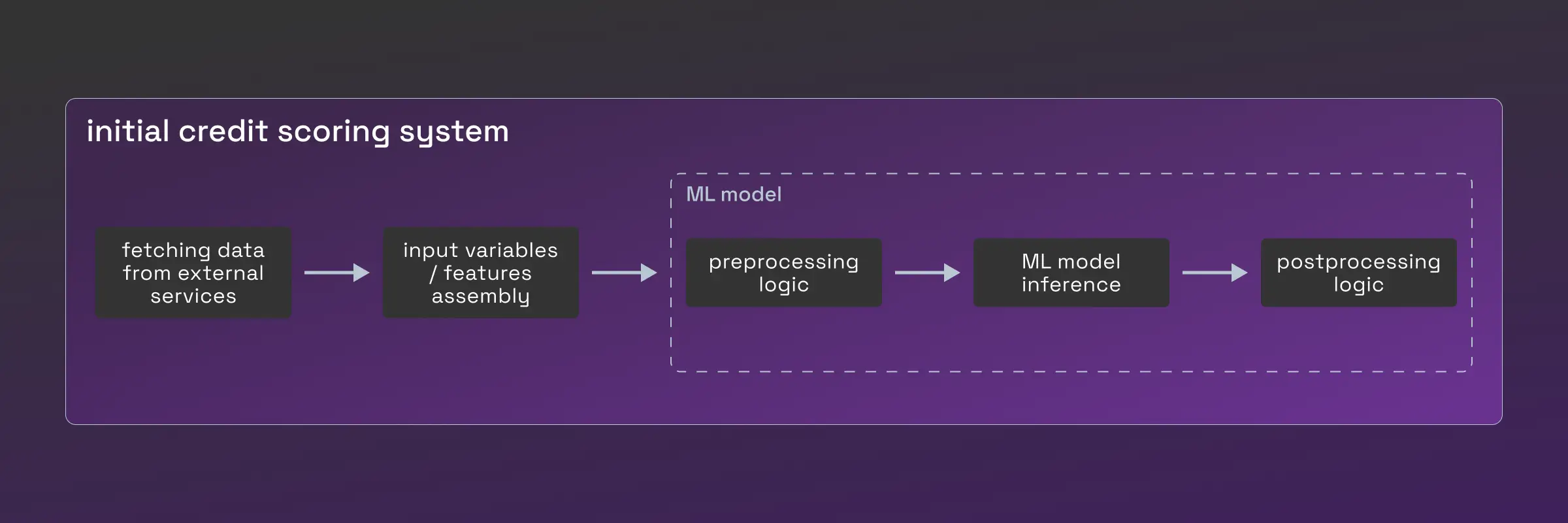
- Business logic changes
The credit scoring system also involved business rules that change frequently. These rules were challenging for developers to understand and implement, as they were often domain-specific. Ideally, such logic would be better managed by credit risk analysts themselves, rather than requiring detailed specifications for developers.
These limitations created inefficiencies, stifled innovation, and often delayed necessary updates to our credit evaluation processes.
Nussknacker & ML Solution
Three areas we had to consider
- Request-response processing mode: Since most of the system workflows are executed in request-response manner, we decided to integrate with Nussknacker scenarios deployed in request-response mode. This approach enables simple communication between the credit scoring system and Nussknacker, without relying on additional components to communicate, such as Apache Kafka.
- ML model inference was one of the most challenging topics we encountered. Aware of the bottlenecks in scoring model integration — particularly the reliance on developers to integrate new models — we decided to enable model inference directly within a Nussknacker scenario. This approach makes it easy for scenario authors to utilize newly published models by data scientists or adjust scenario logic as needed. We evaluated various methods for performing model inference; we’ll go into greater details in the next section.
- Business logic migration was a logical next step in the evolution of the system. Frequent changes to the business logic meant that it made sense to extract and implement it as Nussknacker scenarios. This change gave our business analysts and domain experts the opportunity to take ownership of these decision algorithms, reducing the bottleneck on developer dependency.
ML model inference
A credit scoring model can be a highly complex construct. In our case, the model consisted of an ensemble of sub-models, which were combined using loops and conditionals, to create the final model. Furthermore, in contrast to traditional methods that calculate a single general risk score, our scoring model assessed risk across a range of categories (from inexpensive services to costly products with services sold in installments). The ability to use Python also enabled Play’s data scientists to develop a final ML model by themselves using such Python-based models. Adding a pre- and postprocessing logic was not an issue for them.
The first solution we evaluated was to expose the model as an OpenAPI service. Initially, this seemed promising, offering the flexibility to infer any Python-based model and the ability to use any ML library. However, subsequent discussions highlighted the limitations of this approach. The biggest one was probably the deployment of a new model (or a version of the model), as it would require a developer or an ML engineer to deploy the model. Another issue was the need to develop a custom REST service that serves scoring models. Not to forget the monitoring of the service, e.g. checking if the service is alive, checking if inference responses arrive in a timely manner, checking if inference requests are succeeding. We concluded that, although an OpenAPI model inference service meets our expectations, developing an additional component and maintaining it would be beyond the capacity of a small team and probably not optimal.
Hoping to avoid the burden of building and maintaining an OpenAPI service, we experimented with models exported in PMML and ONNX formats. These formats allow models to be efficiently inferred in the same operating system process as the application inferring such models. In-process inference eliminates the need for network communication to send input data to the model and receive predictions. Furthermore, the runtime for inferring models is just a library imported into Nussknacker, which requires no additional maintenance and monitoring. Since the Nussknacker request-response installation was available and ready to use with the credit scoring system, inference of exported models in a scenario could be up and running in a very short time.
Now while this might seem to suggest that the inference of exported models is a perfect solution, we haven't yet discussed the export itself. In the credit scoring system, data scientists train their models using Python libraries such as scikit-learn and XGBoost. In order to infer these models in-process using a PMML or ONNX runtime library, they first need to be converted into a suitable format. And this is where we encountered some obstacles: not all algorithms were supported by converters and preparing a model consisting of several models often turned out to be impossible.
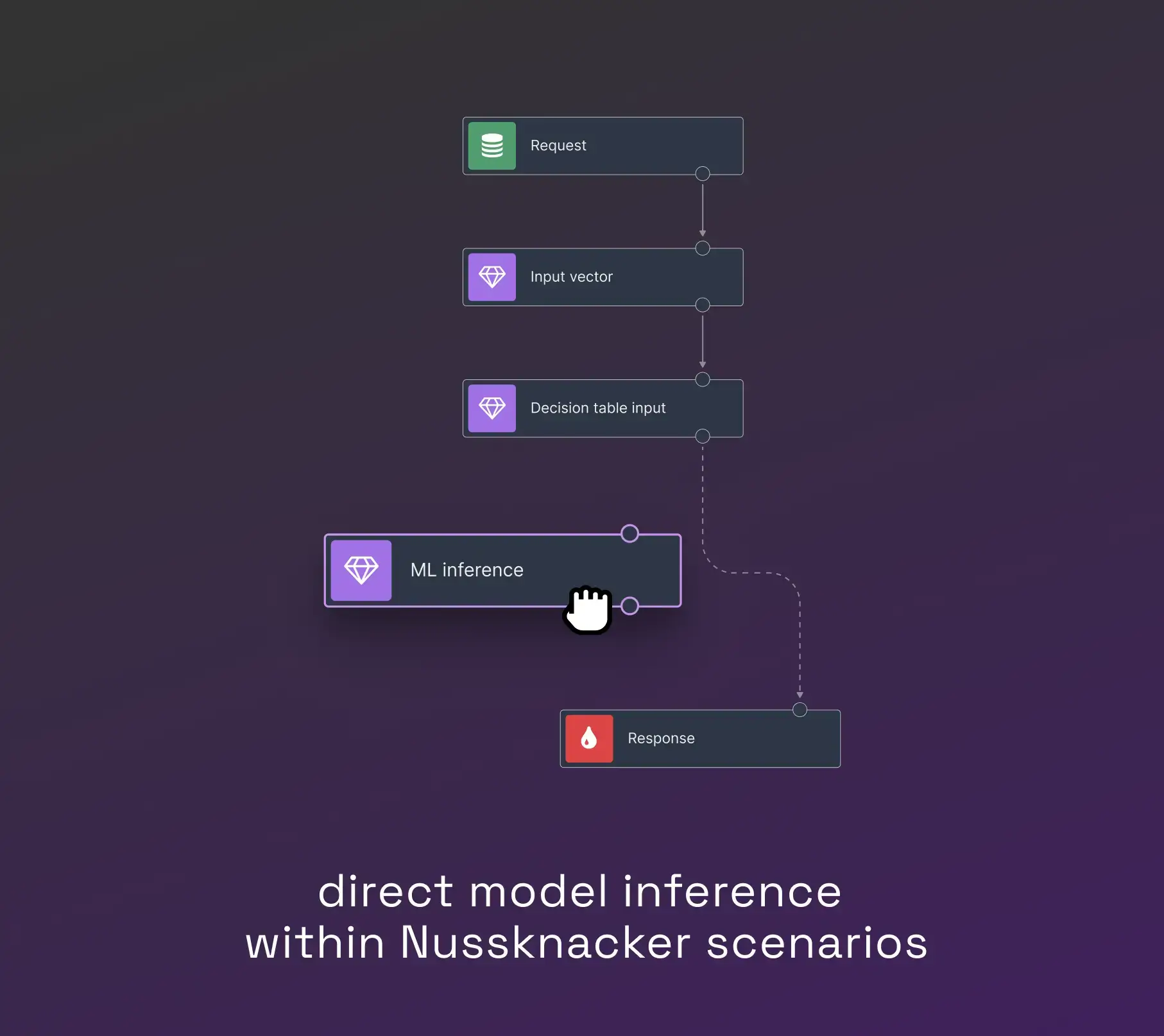
Combining these two solutions, we concluded that we had to give data scientists the freedom to choose any Python ML library and make it as easy as possible for them to build an ensemble of models. On the other hand, as a small team, we wanted to avoid manual deployment of new models. In the end, we came up with a solution consisting of the MLflow models registry and the Nussknacker ML runtime, which enables the inference of any Python-based machine learning model without prior deployment and integration. The image below illustrates how a scoring model was integrated after the introduction of Nussknacker:
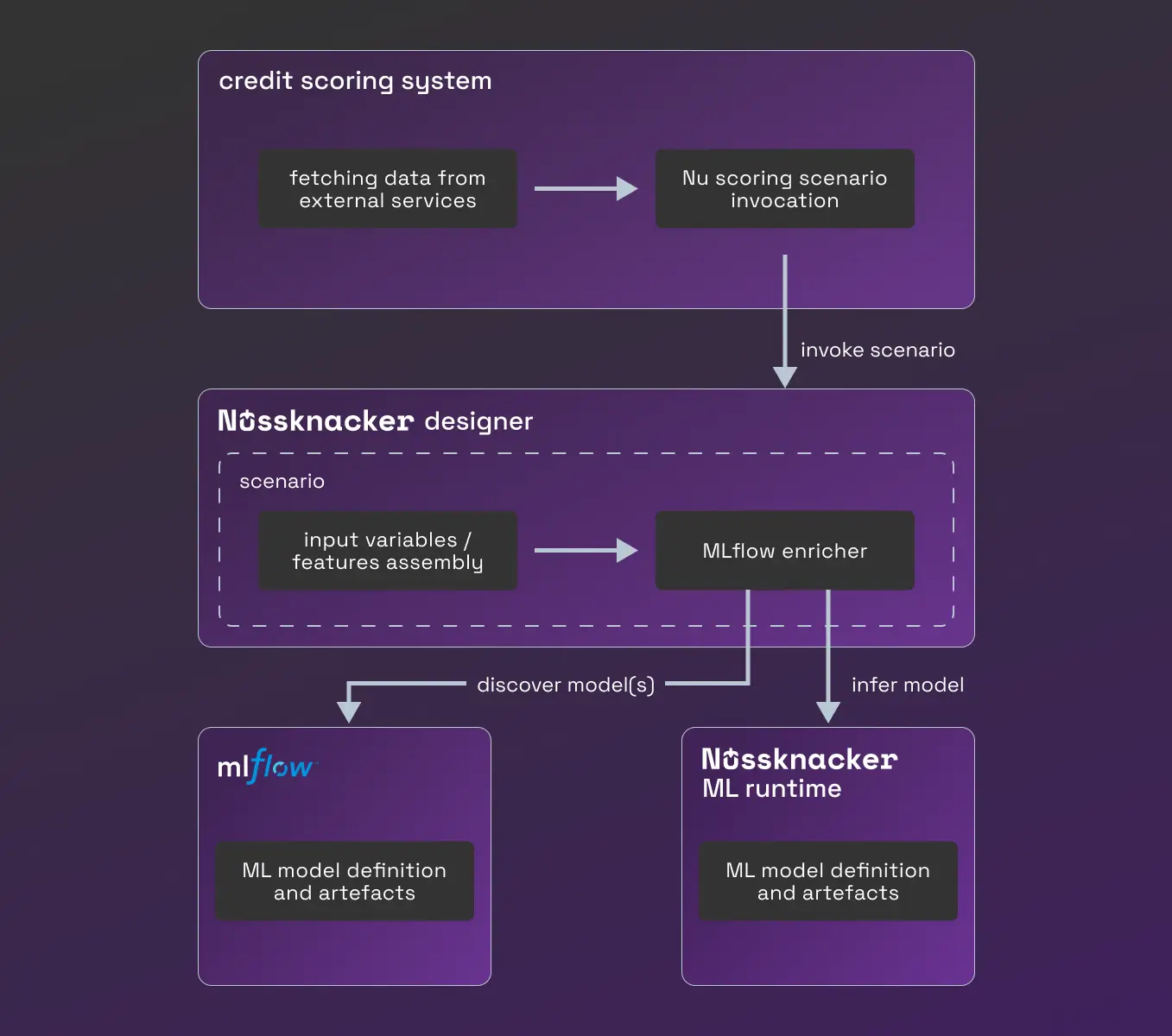
By separating the inference of scoring models from the system, data scientists have gained the ability to prepare models in their 'native' language (Python). They can also store the results of their work in the MLflow model repository. With models stored in MLflow, domain experts can change models and their versions in the Nussknacker scoring scenario without the help of developers thanks to Nussknacker's MLflow enricher.
This solution's flexibility allows data scientists and domain experts to extend the use of ML models beyond the scoring area, making it easier to integrate new models into other parts of the system. Please refer to the documentation and/or article for further information about MLflow and Nussknacker ML runtime-based solution.
Migrating credit scoring ML model to Nussknacker
In the new approach, scenarios which use ML models look roughly like this:
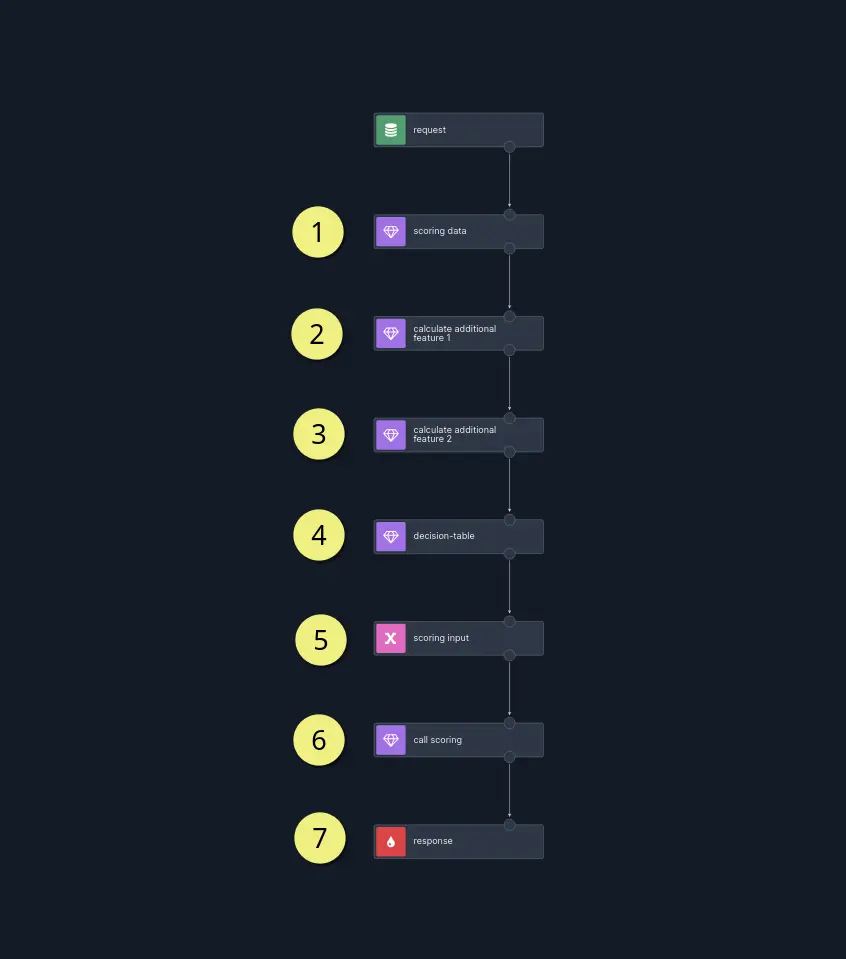
1. The input vector is sourced primarily from our credit scoring system, with pre-calculated features stored in the database and fetched using an SQL enricher .
2. 3. Additionally, the scenario computes real-time features needed to power the scoring process.
4. Another source of input parameters for the model is a decision table with values depending on factors such as the channel of the sales process .
5. Having gathered all that data, we assemble it
6. and infer the model using the ML enricher .
7. The final step is to prepare and return the response from the model.
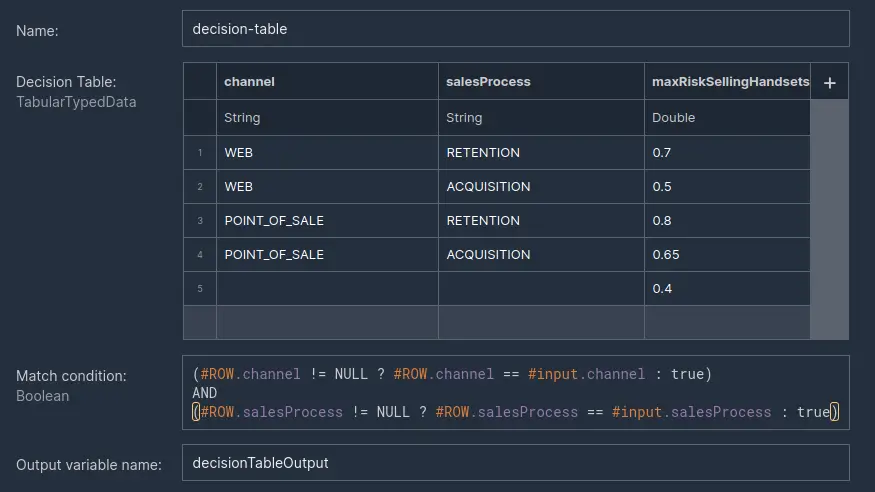
The screenshot above shows the decision table with a row match predicate based on channel and sales process. The last row of the decision table has empty (null) cells for channel and salesProcess and we treat it as a fallback row when any of the previous rows are not matched.
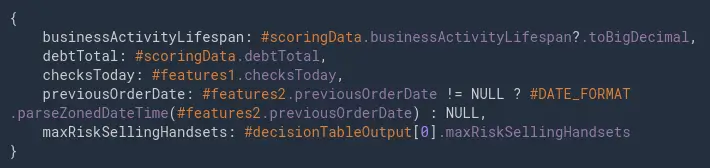
The input vector to the model (6) is a record consisting of features from the enrichment (1, 2, 3) and the decision table (4) shown in the screenshot above.
In the future, the scenario can be extended, e.g. when a new model version is introduced, only 1% of requests can be directed to the new version and the rest to the stable model version. Alternatively, a component can be added that writes inference results to an external service for further analysis. Extracting the scoring model and inference from the credit scoring system into Nussknacker not only accelerated updates to the model and its features, but also reduced the amount of work for developers to integrate new models.
Frequently changing business logic
It is important to note that the credit scoring system consisting of an ML model is only one component of a larger sales system that plays a pivotal role in supporting the sales process. We have identified certain business logic fragments that are subject to frequent change and are familiar to domain experts. This makes them an ideal use case for Nussknacker scenarios to manage the kind of logic usually handled by domain experts. An example of business logic migrated to a Nussknacker scenario is the verification of customer eligibility for additional products or services. The scenario implementing this use case looks roughly as follows:
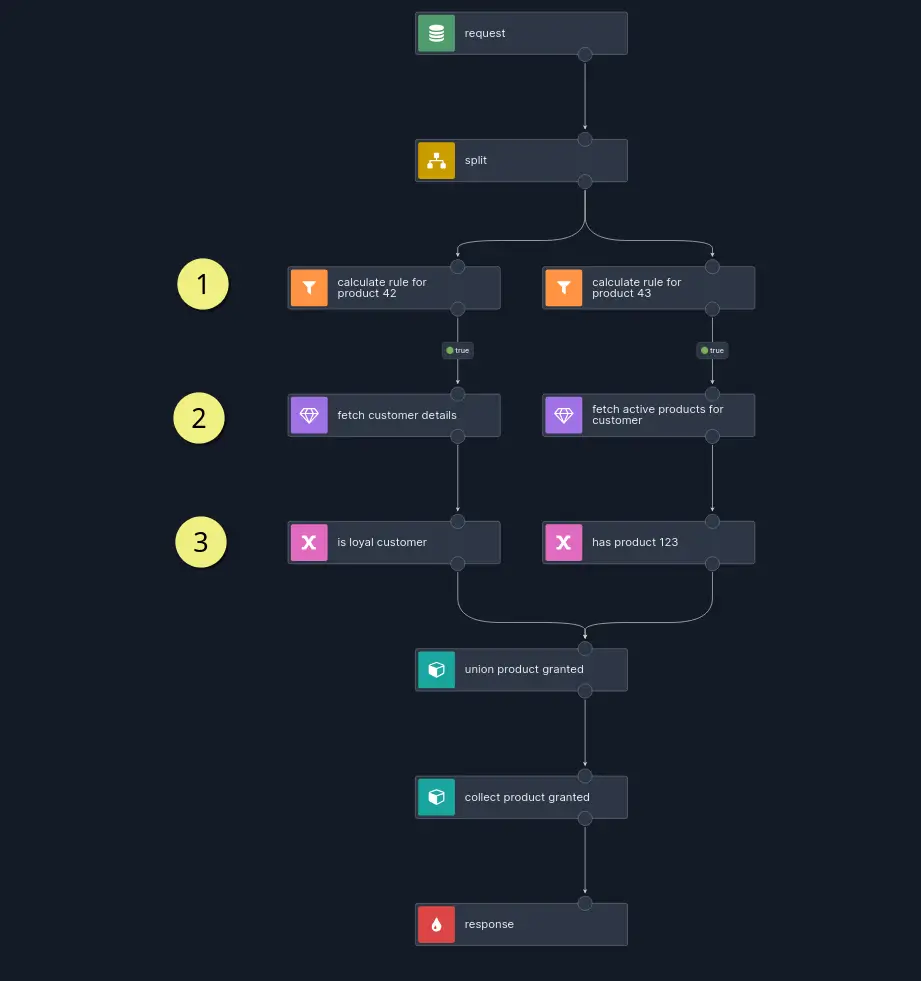
The scenario receives a list of product identifiers and the customer’s attributes. It then executes specific rules matching the requested products (1). A rule to be executed usually needs data from other services, which are retrieved using enrichers (2). The rule itself could be (3): a customer has been active for at least a year; a customer should have bought product X; a customer is retired, and so on.
Benefits of using Nussknacker as a credit scoring system
Using Nussknacker and its ML inference capability caused a fundamental change in the way Play experiments, integrates and deploys ML models:
- Agility: Updates to ML models and business logic can now be implemented swiftly.
- Business team autonomy: Domain experts manage workflows directly, reducing dependency on developers.
- Efficiency: Seamless integration of complex ML models and decision algorithms ensures a streamlined process.
The journey of integration underscores how modern low-code tools can drive innovation and efficiency in complex, high-stakes systems like credit scoring.