Technical explanation
With down-to-earth examples for advanced technical topics like processing modes the problem is that it’s simply not possible to convey everything. Sure, you could look at interns as CPU cores or threads and extend the analogy even further, but there are limits to this. Things like presenting costs of operations, fault tolerance or the sheer volume and scale that makes Big Data big is not an easy thing to do. Reaching the limits of the analogy, let’s get technical.
Request-response mode
Request-response is often used to describe the way systems communicate in the context of network protocols, however in the context of data processing we’re using this term to describe a processing mode. The way it works can be boiled down to this:
- User or application interacts with the processing system by sending a request and waits for a response.
- The request-response service processes the request and sends the results in a response.
And that’s basically it. The fact that the user is waiting for the response is why it is classified as synchronous (for a comparison of processing modes in the context of synchronous and asynchronous processing, check out Arek Burdach’s blog post about the concept of bridge application). In our example, this is why lawyers were waiting for clients data at the desk in a queue.
In the current debate about Big-Data processing modes, request-response is usually omitted, as the debate focuses on comparing streaming and batch processing and request-response is not out-of-the-box suitable for high-volume stateful computations that batch and streaming processing technologies provide. Due to the focus on quickly serving pre-computed results, generally, custom request-response services can be implemented without specialised tooling like processing engines or message queues. Since the service itself is stateless, it can be easily scaled, as seen in the client data serving desks example. Though keep in mind that processing modes are not absolute categories - if the trade-off is acceptable in your use case, you could implement stateful computations or other functionalities not typical for the mode.
Request-response style of processing is the way user-facing web services are implemented. When loading a web application, the response time is vital to user experience. Of course, sometimes websites can make the request in the background and wait for response in a way that hides this delay from the user, but in other cases the user sees what is essentially a loading screen until the response from the slowest-response-time service arrives. This is the reason why typical service within this mode will focus on response time above all else. In the context of Big-Data, an ideal use case of request-response services is serving the results of batch and streaming computations or to act as a convenient interface for these pipelines for other purposes.
Batch processing 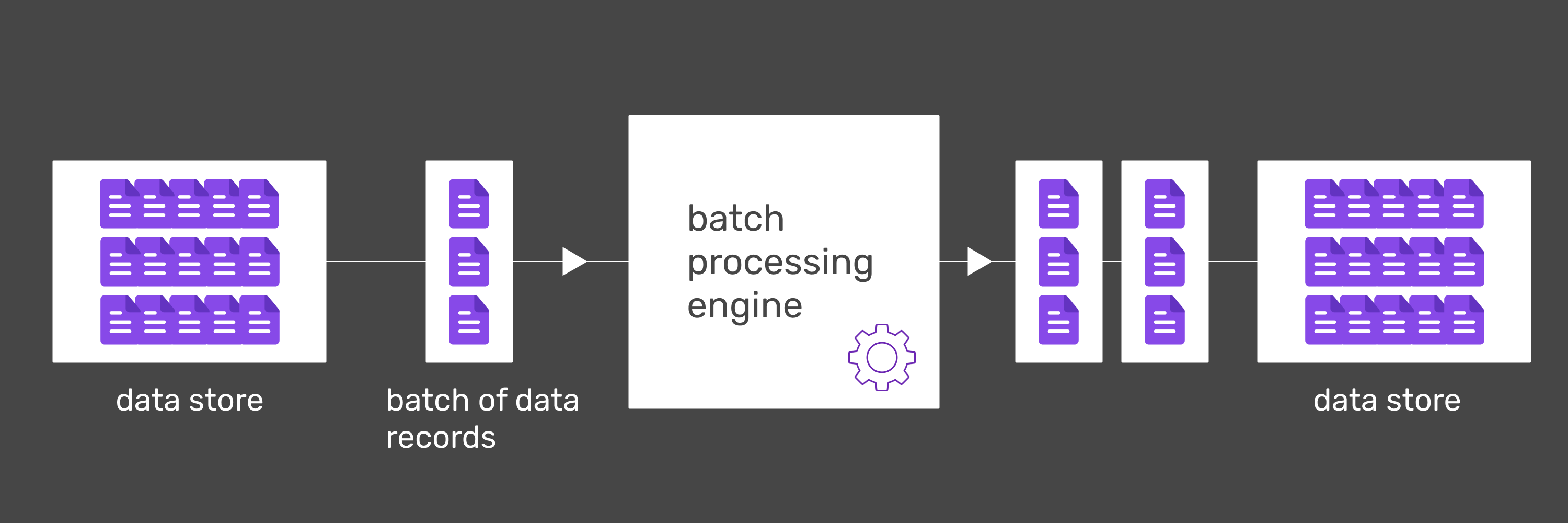
Batch processing refers to processing a bounded set of data (batch) and producing output for the entire batch. It is also a very old form of computing. This is the way data was processed even in the 1890 US Census, way before digital computers were even invented, as Martin Kleppman noted, in his famous book "Designing Data-Intensive Applications". And if you think about it intuitively, it is the most natural form of processing for stateful operations - if someone wanted you to sort some documents, you would expect them to give you the entirety of these documents up front.
The long age and relative simplicity of batch processing does not mean however it can be in any way classified as legacy. To keep up with the increasing volume of data that today’s businesses require, there is a great need to parallelize the processing workload - dividing the work between multiple processing units (like CPU cores). In hardware terms, this is motivated by the fact that in the last decades, CPU single-core performance has stagnated, while the amount of cores per CPU increases steadily. It’s also related to advances in networking, allowing for the load to be delegated to other machines. Processing engines like Apache Spark or Apache Flink allow batch processing to scale batch workloads to today’s Big-Data requirements. Using their declarative API’s, we can keep processing logic separated from operative concerns. That way, changes in these areas remain isolated and processing engines can optimise their performance under the hood without requiring any action from their users.
Batch jobs typically run in scheduled intervals. If their input volume is high, the processing may take hours, or even days. This may seem non-optimal, but for big volumes, even after lots of optimizations, scaling the system, using specialised technologies, it will still take a long time since there’s no way around physical limitations. To mitigate this, if the processing results are needed for day-to-day business operations, these workloads may be scheduled to run during the non operation hours. Some use cases are perfectly suited towards batch processing because they need to be computed in bigger intervals like generating periodical reports, invoicing at the end of the month or making back-ups.
An important advantage of batching, especially when compared to streaming, is the cost of operations. Ecosystem of batch processing is very mature, with battle-tested, scalable storage and processing technologies. Finding experienced engineers or training new ones to operate these systems should be relatively easy and cheap. From a technical side, having all input data available upfront reduces the amount of complex cases to handle and makes it possible to know how much resources are needed for an operation. The business logic part of processing is also relatively very easy to reason about. These arguments make it attractive to use batch processing for use cases where there isn’t much value to be gained from real-time insights or from window-based intermediate results. In some situations, like operating in legacy architectures, use cases which are suitable for streaming may not be economically justifiable when compared to processing them in short-interval batches.
Stream processing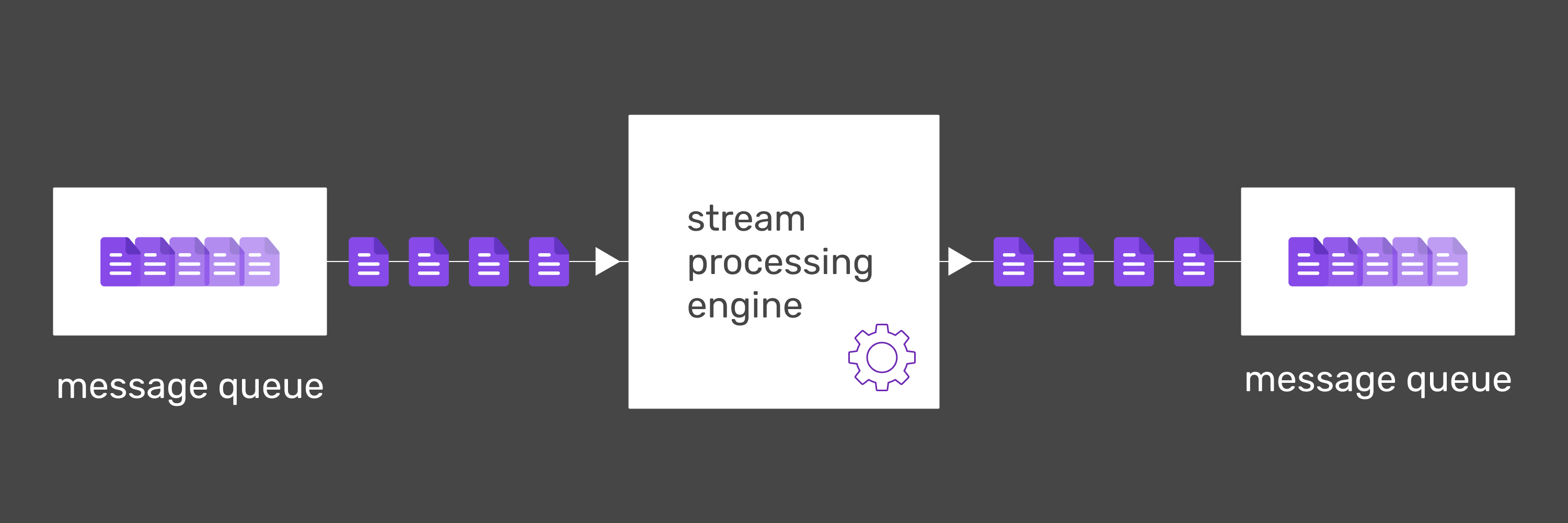
Stream processing is a method of processing data where input ingestion and output production is continuous. Input data can be unbounded and potentially infinite, thus streaming pipeline does not produce final results in a way that batch workload does. The pipeline “finishes” processing when it is stopped. Arguably, this resembles how business processes are often conducted in today’s world - not in scheduled intervals, but as a constant, reactive pipeline.
Streaming technologies are sometimes described as the holy grail of Big-Data processing. From a historical perspective we know that in computing there are no silver bullets, so to counterbalance the hype, let’s start with the downsides. At the end they can all be boiled down to complexity. In the example section of this article, request-response and batch examples, much of the content was a description of supporting topics, not essential to these processing modes. That’s because there’s not a lot of essential complexity to them - they are pretty simple. However in the streaming example, all of the introduced concepts were in some part essential to streaming and it was only scratching the surface.
Window aggregations, watermarks, lateness, idle sources are all non-trivial concepts that need to be understood and properly handled. This means increased cost of operations and engineer training. It also is not possible to push all of this complexity onto the engineering side because some of these concepts are business-critical. For example, deciding how to approach the compromise between completeness and latency stemming from late events is a business decision. This makes stream processing harder to reason about for data analysts.
However, the streaming ecosystem has been developing at a spectacular pace during the last decade and this complexity becomes less and less of a problem. Streaming technologies are becoming more robust in terms of fault tolerance and scalability and their interfaces are becoming more refined. Companies like Confluent keep delivering fantastic learning resources and actively cultivate a healthy developer community. Certain complexity may never be reduced, but the ecosystem’s actors keep making progress in simplifying what can be simplified.
Streaming comes with an incredible set of advantages. Not having to wait for a batch to finish and still have complex, stateful computations done on the fly can provide a lot of business value. This makes streaming shine in cases where freshness of data is critical. For example, in the case of fraud detection in the telecommunications industry, the window of time from detecting an anomaly to prevention is extremely short (for an in-depth fraud detection dive, check out Łukasz Ciolecki’s blog post series). The same can be said for alerting systems based on IoT devices (check out an example on Nussknacker demo application). Another use case perfectly suited towards streaming is real-time recommendation systems. These examples rely on low latency of processing - the lower it is, the more business value the system can provide.
