LLMs are great at turning messy, unstructured input into clean, structured answers. Hand a model a free-form product review — "Got an aluminium folding e-scooter from Zorvex in matte black. 480 euros. Battery died after a month, terrible for this price." — and ask for the brand, the price, and whether the customer is happy, and it will happily oblige. The trouble starts after the model replies. You get back a string. To actually use that price — or that very unhappy customer — to route the event, you have to parse the string into JSON, hope the shape is what you expected, pull out the field, and cast it to the right type — every single time, in every downstream node. In Nussknacker, the LLM Chat and AI Agent enrichers used to hand you exactly that: a String. Now, with structured output, they hand you something much better — a typed record you can navigate with autocomplete and design-time validation, just like any other variable in your scenario. In this post we'll build a real scenario around it: a stream of customer product reviews that an LLM turns into structured product listings, which we then route, aggregate, and fan out — all on typed fields, no JSON parsing nodes anywhere. 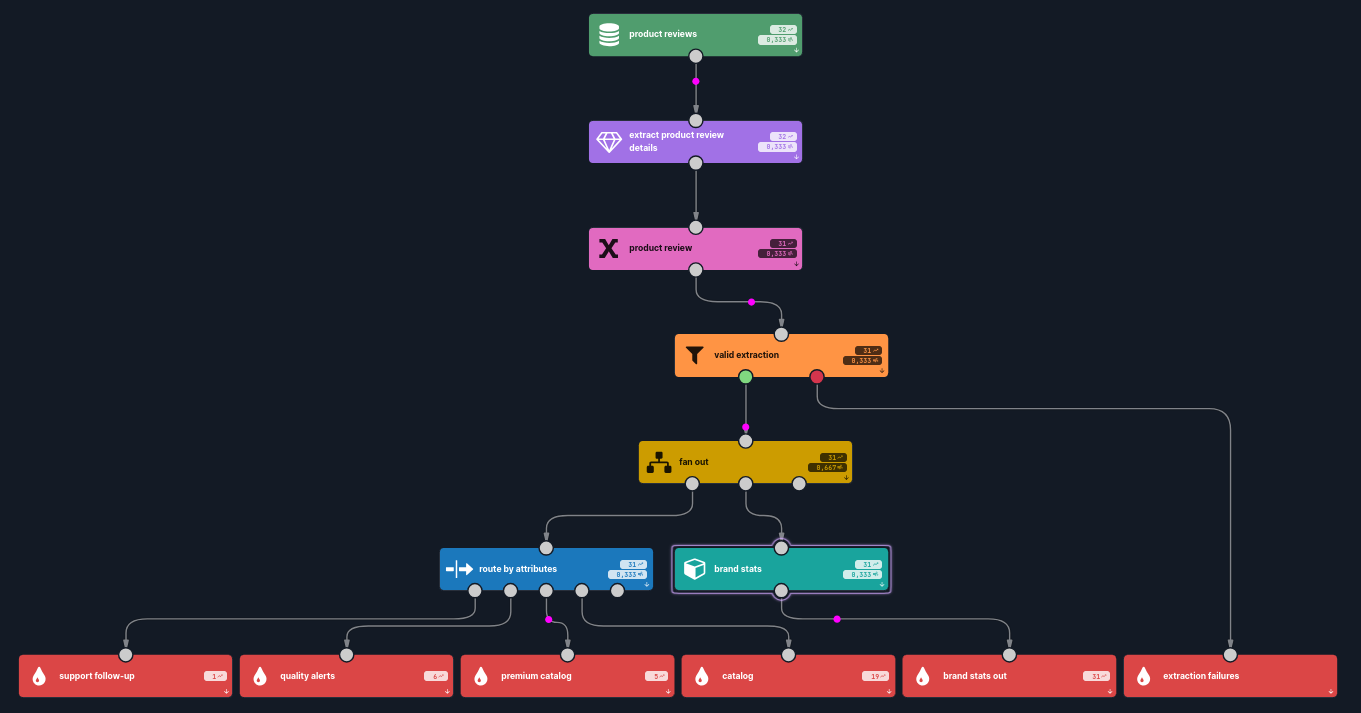
The problem: a model returns text, but your scenario needs fields
Say you're ingesting a stream of free-text product reviews and you want to extract a structured listing from each one — brand, price, materials, the review's sentiment, and whether the reviewer expects a reply. You write a prompt, tell the model to answer in JSON, and it returns something like:
{"brand": "Zorvex", "price": 480.0, "sentiment": "negative", "needsReply": false}But to Nussknacker, that's still just a String. If you want to branch on sentiment — say, route every unhappy review to a quality-alerts topic — you'd have to do something like this in every expression:
#CONV.toJson(#productReviewExtraction.raw)["sentiment"] == "negative"…with no guarantee the field exists, no type information (is sentiment guaranteed to be one of your labels, or did the model freestyle a "very negative"?), no autocomplete, and a runtime explosion the first time the model wraps its answer in a markdown code block or renames a field. This is the classic "stringly-typed" trap. The model already knows the shape of the data — you described it in the prompt — but that knowledge is lost the moment the response crosses into your scenario. You end up re-parsing and re-validating the same structure by hand, downstream, forever.
The solution: describe the shape once, get typed fields everywhere
Both the LLM Chat and AI Agent enrichers now have an Output schema parameter. You give it a JSON Schema describing the answer you expect. Here's the schema from our scenario — a ProductReview with nested specs and a sentiment enum:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "ProductReview",
"type": "object",
"properties": {
"brand": { "type": "string", "description": "The manufacturer or brand name." },
"productName": { "type": "string", "description": "The full commercial name of the item." },
"specs": {
"type": "object",
"properties": {
"color": { "type": "string", "description": "The color or finish name." },
"material": { "type": "array", "items": { "type": "string" } }
},
"required": ["color", "material"]
},
"price": { "type": "number", "minimum": 0 },
"sentiment": { "type": "string", "enum": ["positive", "neutral", "negative"],
"description": "Overall sentiment of the review." },
"needsReply": { "type": "boolean",
"description": "True if the reviewer asks a question or requests a response." }
},
"required": ["brand", "productName", "specs", "price", "sentiment", "needsReply"]
}Notice that neither sentiment nor needsReply is something the reviewer wrote down anywhere — the model judges them from the text. And with an enum in the schema, the sentiment judgment is constrained to exactly three values instead of whatever wording the model fancies. Nussknacker does two things with that schema:
- At runtime, every call to the model carries the schema as a response-format constraint, so the model is steered to answer in exactly that shape.
- At design time, it converts the schema into a Nussknacker type, so the rest of your scenario knows the fields and their types before you ever run anything.
The enricher output becomes a record with two fields:
raw— the model's response as text, exactly as it came back.structured— the response parsed and typed according to your schema (or null; more on that below).
So if the enricher's output variable is #productReviewExtraction, every field under #productReviewExtraction.structured comes out as a known, navigable type — with autocomplete and design-time validation:
structured.price— a numberstructured.needsReply— a booleanstructured.specs.material— a list of stringsstructured.sentiment—String(negative) | String(neutral) | String(positive)
That last one is the enum getting the royal treatment: instead of collapsing to a plain String, it keeps the exact set of literal values you declared in the schema. 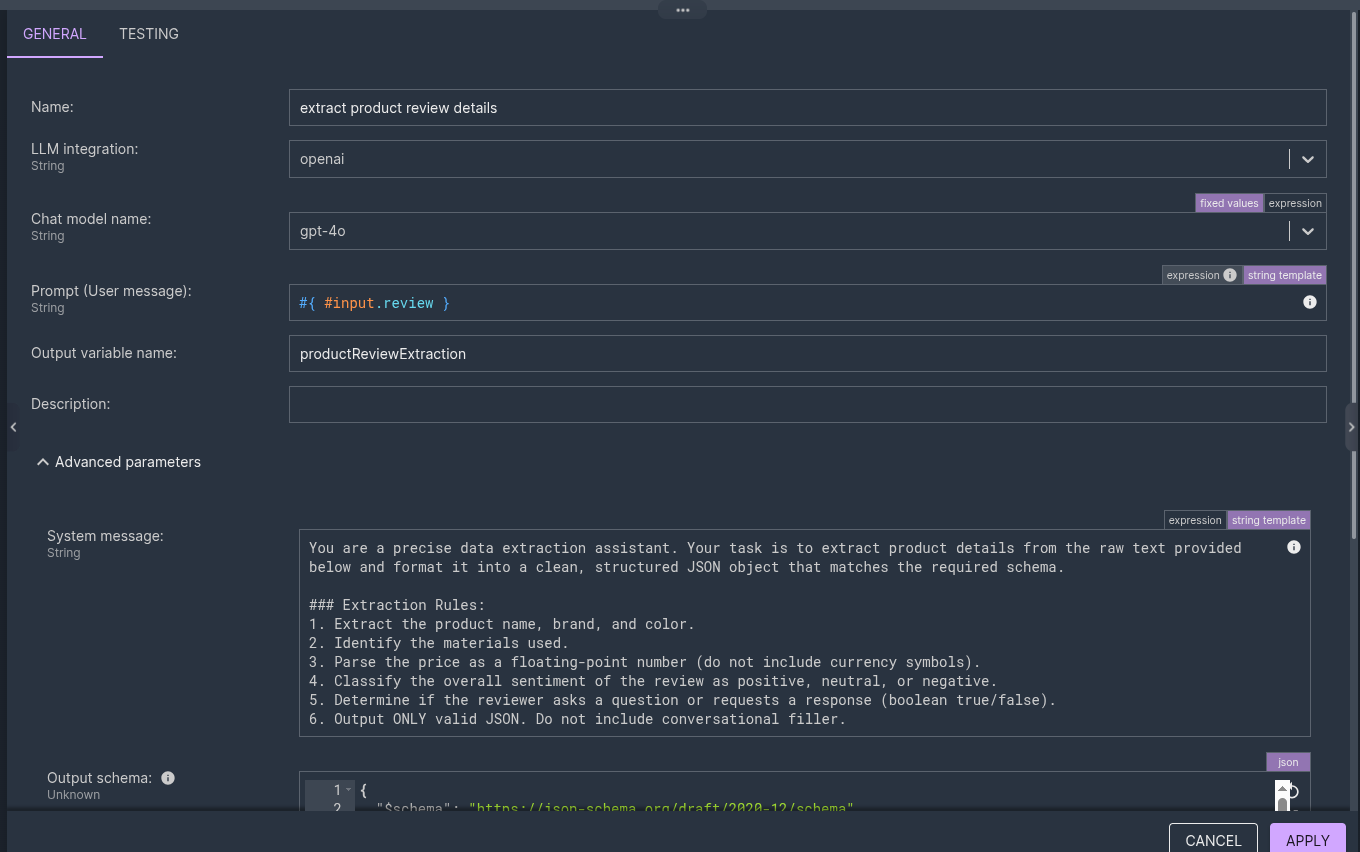 A nice touch in this scenario: the instructions live in the System message, and the user-message Prompt is just the data —
A nice touch in this scenario: the instructions live in the System message, and the user-message Prompt is just the data — #{ #input.review }. The schema does the structural heavy lifting; the system message handles the few things a schema can't express ("parse the price as a number, no currency symbol", "classify the overall sentiment of the review"). The user message stays clean. 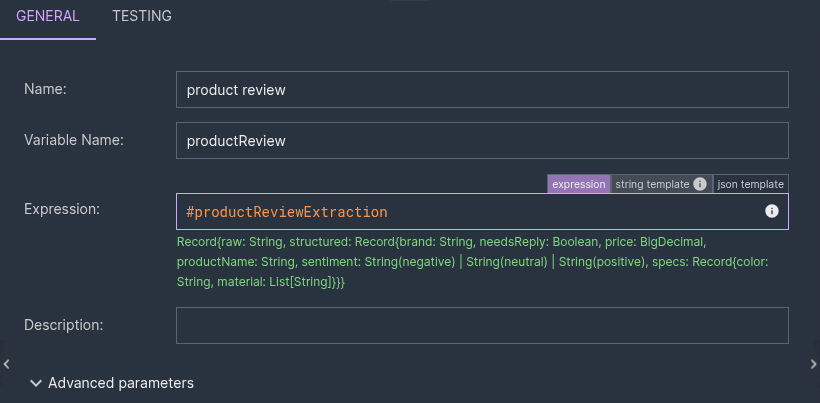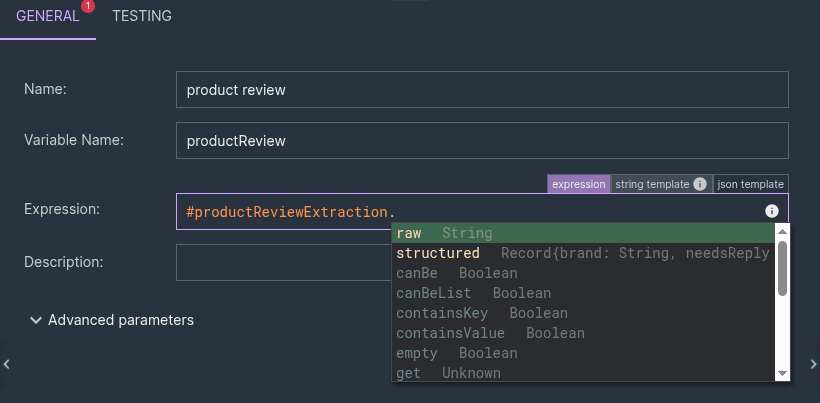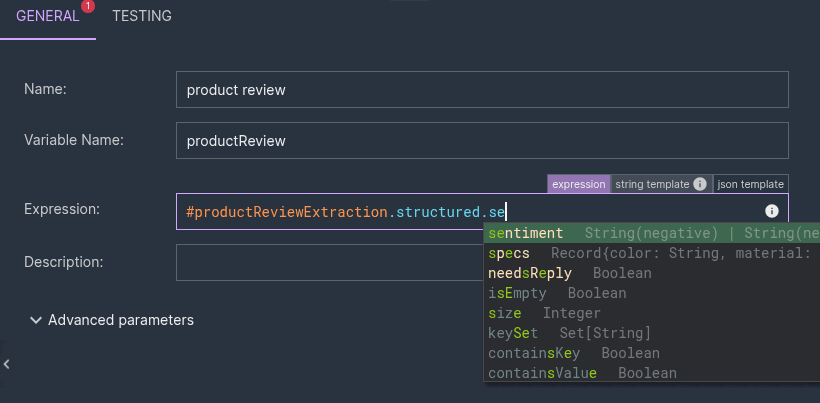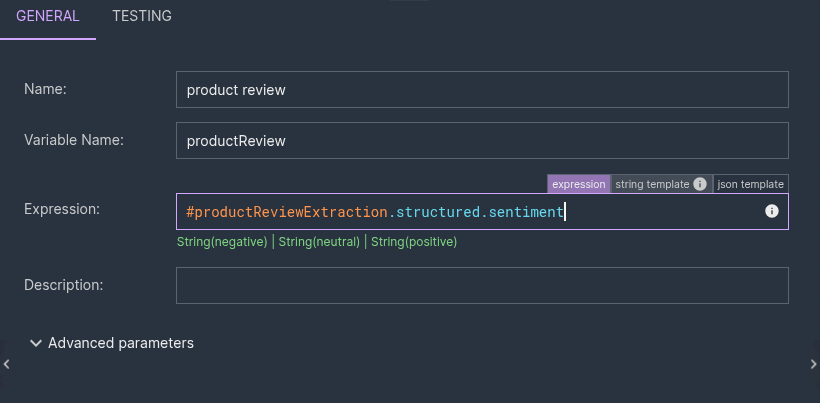
What happens when the model misbehaves?
LLMs are probabilistic. Sooner or later a model will return something that isn't valid JSON, or JSON that doesn't match your schema — a number where you asked for a string, a missing field, a chatty "Sure! Here's your JSON:" prefix. We didn't want a single bad response to blow up your scenario. So the contract is deliberately forgiving:
rawalways holds the model's text, parseable or not. You never lose the original answer.structuredis null when the response can't be parsed or doesn't match the schema.
That means failure is a value you can branch on, not an exception that kills the event. In our scenario we make that explicit with a single variable and a filter:
// variable "product review"
#productReview = #productReviewExtraction.structured
// filter "valid extraction"
#productReview != nullEverything that parsed flows on through #productReview — already typed. Everything that didn't goes out the filter's false branch to an extraction failures sink, where you can review it, retry with a stricter prompt, or alert when the failure rate climbs. The flow keeps running either way. 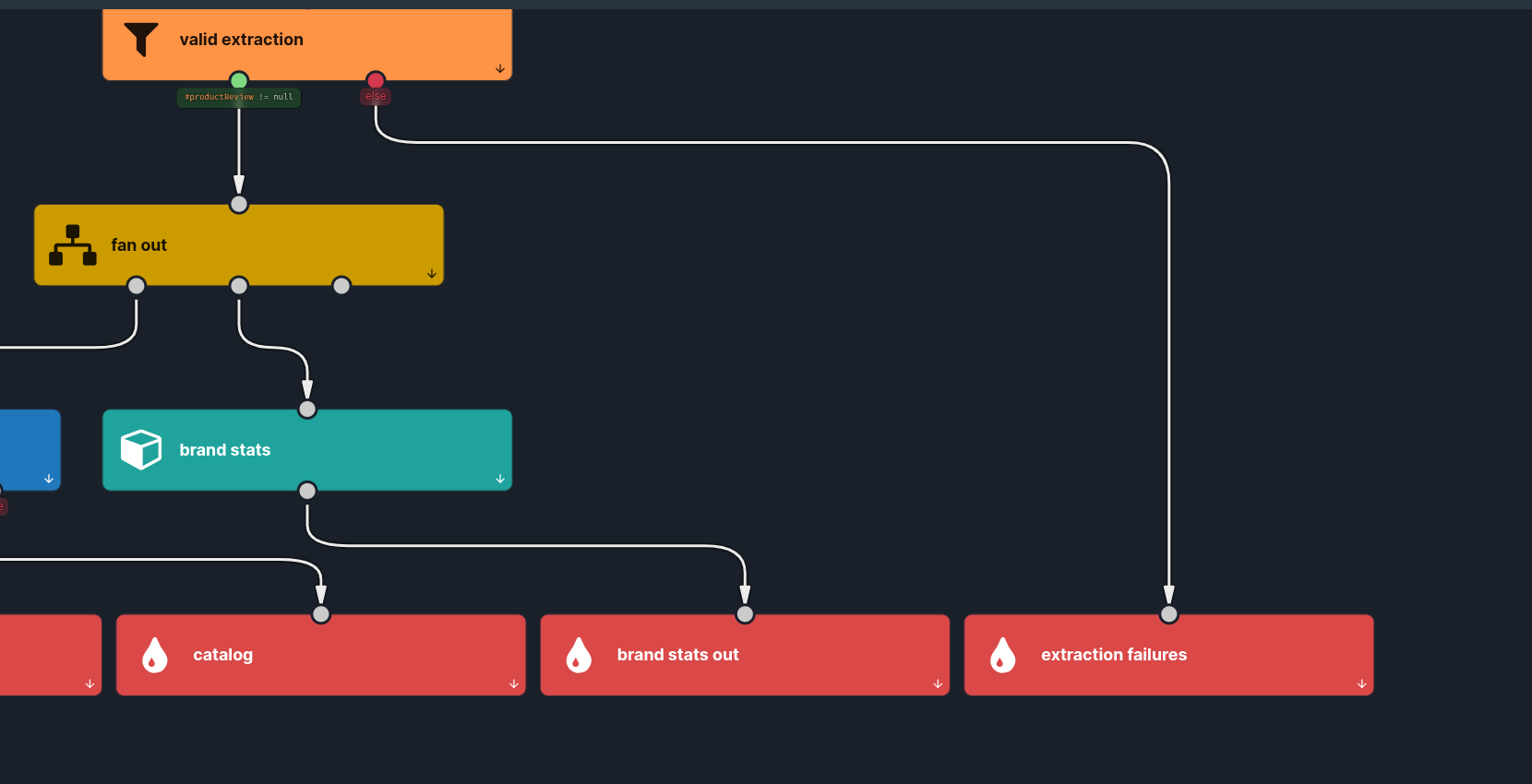
A full example: extracting and routing product listings
Here's the whole scenario, end to end. It reads product reviews, extracts a typed ProductReview from each, drops the ones that couldn't be parsed, and then fans the good ones out two ways.
1. Source — product reviews. A stream of records, each with a free-text review field. For example:
"Grabbed the HydroFlow 1L bottle from PeakGear in teal, stainless steel build. 28 euros."
2. Enricher — extract product review details (LLM Chat). Configured with the OpenAI integration and gpt-4o, the system message holding the extraction rules, the prompt bound to #{ #input.review }, and the ProductReview schema in the Output schema parameter. For the review above, #productReviewExtraction.structured comes back typed as:
{
"brand": "PeakGear",
"productName": "HydroFlow 1L Bottle",
"specs": { "color": "teal", "material": ["stainless steel"] },
"price": 28.0,
"sentiment": "neutral",
"needsReply": false
}This review offers no real opinion and asks nothing — so the model fills sentiment as neutral and needsReply as false. The judgment fields always come back with a value, even when the text barely supports one; the schema isn't just steering the output format, it's deciding what to pay attention to.
3. Variable + filter — product review / valid extraction. Project #productReviewExtraction.structured into #productReview, then filter on #productReview != null. Unparseable responses peel off to extraction failures; the rest continue, fully typed.
4. Split — fan out. From here the same typed #productReview feeds two independent branches.
5a. Switch — route by attributes. Each outgoing branch is just a condition on a typed #productReview field, evaluated top to bottom — first match wins:
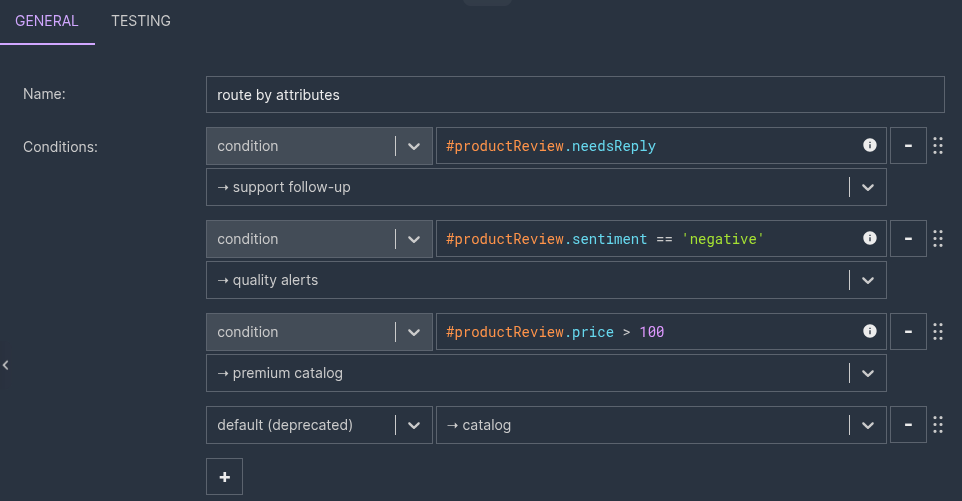 Each condition is an ordinary SpEL expression over the typed record —
Each condition is an ordinary SpEL expression over the typed record — #productReview.price > 100 against a value the editor already knows is a number, #productReview.sentiment == 'negative' against one it knows can only be three strings. No get(...), no casts, no "does this field exist?" guards. Four of the source's sample reviews make the routing concrete:
| Review | Extracted | Lands in |
|---|---|---|
| Espresso machine, €420, "Which beans would you recommend for it?" | needsReply: true | support follow-up (the question outranks the premium price) |
| Folding e-scooter, €480, "battery died after a month" | sentiment: "negative" | quality alerts (sentiment also outranks price) |
| Merino wool overcoat, €240 | price: 240 | premium catalog |
| HydroFlow bottle, €28 | nothing special | catalog (default) |
That top row is the interesting one. The espresso-machine review is positive and €420 — it clears the premium bar — yet because it asks a question, needsReply matches first and it routes to support follow-up. The scenario ships with a saved test case that pins exactly this down: mock the enricher's output and assert the branch. 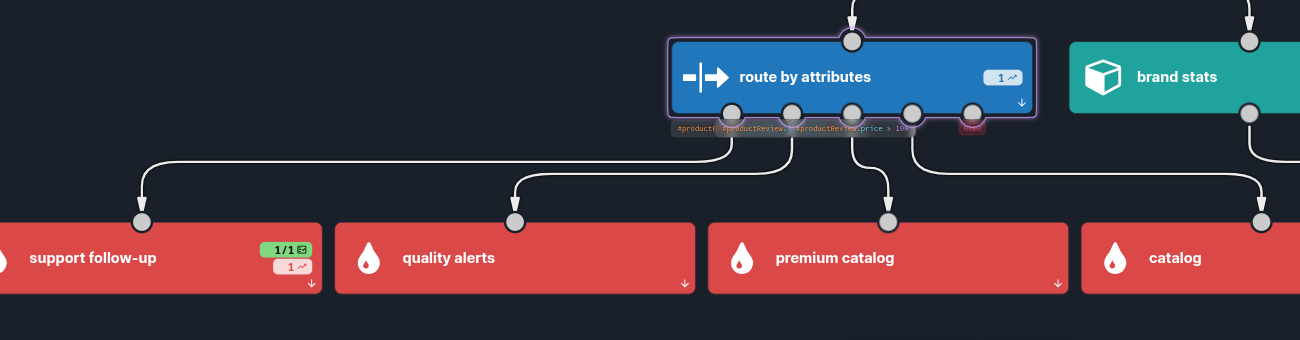 The per-node counters tell the story at a glance: one record into route by attributes, and a green 1/1 on support follow-up — not premium catalog, even though the price would have qualified. Because the test mocks the enricher and asserts on the branch, the routing is verified deterministically, without ever calling the model. (Testing the routing is exactly what you want here; the LLM's job is upstream of the logic you're asserting on.)
The per-node counters tell the story at a glance: one record into route by attributes, and a green 1/1 on support follow-up — not premium catalog, even though the price would have qualified. Because the test mocks the enricher and asserts on the branch, the routing is verified deterministically, without ever calling the model. (Testing the routing is exactly what you want here; the LLM's job is upstream of the logic you're asserting on.)
5b. Aggregate — brand stats. In parallel, a tumbling-window aggregation computes the average #productReview.price grouped by #productReview.brand. The aggregated field is the same typed number you routed on — no separate parsing step to feed the aggregator.
Why this matters
A few things fall out of this design that are worth calling out:
- Design-time safety. Typos and shape mismatches surface in the editor, not in production. The cost of a wrong field name drops from a debugging session to a red squiggle.
- It composes. Because structured is an ordinary typed record, every downstream feature — filters, switches, aggregations, for-each, joins, other enrichers — works on it natively. Routing on needsReply and averaging price per brand use the same typed value, and the nested
specs.materiallist is one for-each node away from becoming individual events. The LLM output stops being a special case. - Nothing breaks. Leave the Output schema parameter empty and the enricher still returns a plain String, exactly as before. This is purely additive — you opt in per node.
- Graceful degradation. Unparseable answers don't crash the flow; they become a null you choose how to handle.
Under the hood, we reused the same JSON-Schema-to-type machinery that already powers Nussknacker's OpenAPI enricher and JSON-Schema integrations, so the typing behaves consistently with the rest of the platform — nested objects, arrays, and primitives all map the way you'd expect, and enums become unions of literal types.
When to use it
Reach for structured output whenever you need to act on what the model says, rather than just store or display it:
- Extraction — pull structured records out of free text: reviews, invoices, emails, logs, transcripts (the example above).
- Classification and routing — categorize events and fan them out by the result.
- Enrichment — derive attributes (sentiment, language, risk score) that later nodes filter or aggregate on.
If you only need the raw text — a generated summary you pass straight to a sink — leave the schema out and keep the simple String output. The same applies to AI Agent, where the model can call tools across several iterations before producing its final answer — that final answer gets typed against your schema in exactly the same way.
Try it
Structured output is available on the LLM Chat and AI Agent enrichers today. Point the Output schema parameter at a JSON Schema, and your model's answers arrive as typed fields — ready to route, filter, and aggregate across the rest of your scenario, with no JSON-parsing nodes anywhere. Further reading
- LLM Chat enricher and AI Agent enricher — component reference
- Nussknacker documentation
- Try it on Nussknacker Cloud
- Nussknacker on GitHub
Building something with LLMs on streaming data? Feel free to ask any questions — we'd love to see what you make.